Exercise 4: Logistic Regression and Newton's Method
来源:互联网 发布:java链表原理 编辑:程序博客网 时间:2024/04/30 17:19
In this exercise, you will use Newton's Method to implement logistic regression on a classification problem.
Data
For this exercise, suppose that a high school has a dataset representing 40 students who were admitted to college and 40 students who were not admitted. Each ![]() training example contains a student's score on two standardized exams and a label of whether the student was admitted.
training example contains a student's score on two standardized exams and a label of whether the student was admitted.
Your task is to build a binary classification model that estimates college admission chances based on a student's scores on two exams. In your training data,
a. The first column of your x array represents all Test 1 scores, and the second column represents all Test 2 scores.
b. The y vector uses '1' to label a student who was admitted and '0' to label a student who was not admitted.
Plot the data
Load the data for the training examples into your program and add the ![]() intercept term into your x matrix.
intercept term into your x matrix.
Before beginning Newton's Method, we will first plot the data using different symbols to represent the two classes. In Matlab/Octave, you can separate the positive class and the negative class using the find command:
% find returns the indices of the% rows meeting the specified conditionpos = find(y == 1); neg = find(y == 0);% Assume the features are in the 2nd and 3rd% columns of xplot(x(pos, 2), x(pos,3), '+'); hold onplot(x(neg, 2), x(neg, 3), 'o')
Your plot should look like the following:
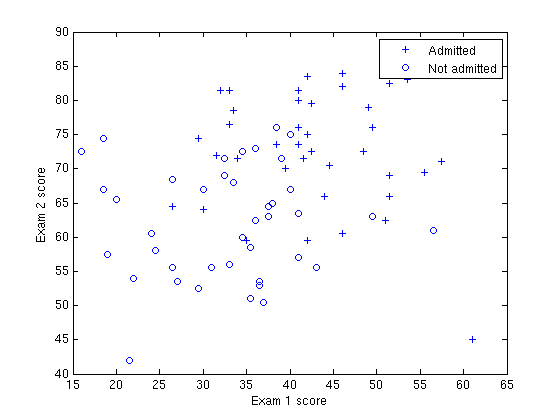
Newton's Method
Recall that in logistic regression, the hypothesis function is
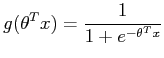
In our example, the hypothesis is interpreted as the probability that a driver will be accident-free, given the values of the features in x.
Matlab/Octave does not have a library function for the sigmoid, so you will have to define it yourself. The easiest way to do this is through an inline expression:
g = inline('1.0 ./ (1.0 + exp(-z))'); % Usage: To find the value of the sigmoid % evaluated at 2, call g(2)The cost function ![]() is defined as
is defined as
![\begin{displaymath}J(\theta)=\frac{{1}}{m}\sum_{i=1}^{m}\left[-y^{(i)}\log(h_......(1-y^{(i)})\log(1-h_{\theta}(x^{(i)}))\right] \nonumber\par\end{displaymath}](http://openclassroom.stanford.edu/MainFolder/courses/MachineLearning/exercises/ex4/img8.png)
Our goal is to use Newton's method to minimize this function. Recall that the update rule for Newton's method is
In logistic regression, the gradient and the Hessian are

![\begin{displaymath}H & = & \frac{1}{m}\sum_{i=1}^{m}\left[h_{\theta}(x^{(i)})\l......^{(i)})\right)x^{(i)}\left(x^{(i)}\right)^{T}\right] \nonumber\end{displaymath}](http://openclassroom.stanford.edu/MainFolder/courses/MachineLearning/exercises/ex4/img11.png)
Note that the formulas presented above are the vectorized versions. Specifically, this means that ![]() ,
, , while
, while ![]() and
and ![]() are scalars.
are scalars.
Implementation
Now, implement Newton's Method in your program, starting with the initial value of ![]() . To determine how many iterations to use, calculate
. To determine how many iterations to use, calculate ![]() for each iteration and plot your results as you did in Exercise 2. As mentioned in the lecture videos, Newton's method often converges in 5-15 iterations. If you find yourself using far more iterations, you should check for errors in your implementation.
for each iteration and plot your results as you did in Exercise 2. As mentioned in the lecture videos, Newton's method often converges in 5-15 iterations. If you find yourself using far more iterations, you should check for errors in your implementation.
After convergence, use your values of theta to find the decision boundary in the classification problem. The decision boundary is defined as the line where
which corresponds to
Plotting the decision boundary is equivalent to plotting the ![]() line. When you are finished, your plot should appear like the figure below.
line. When you are finished, your plot should appear like the figure below.

Questions
Finally, record your answers to these questions.
1. What values of ![]() did you get? How many iterations were required for convergence?
did you get? How many iterations were required for convergence?
2. What is the probability that a student with a score of 20 on Exam 1 and a score of 80 on Exam 2 will not be admitted?
Solutions
After you have completed the exercises above, please refer to the solutions below and check that your implementation and your answers are correct. In a case where your implementation does not result in the same parameters/phenomena as described below, debug your solution until you manage to replicate the same effect as our implementation.
Newton's Method
1. Your final values of theta should be
Plot. Your plot of the cost function should look similar to the picture below:
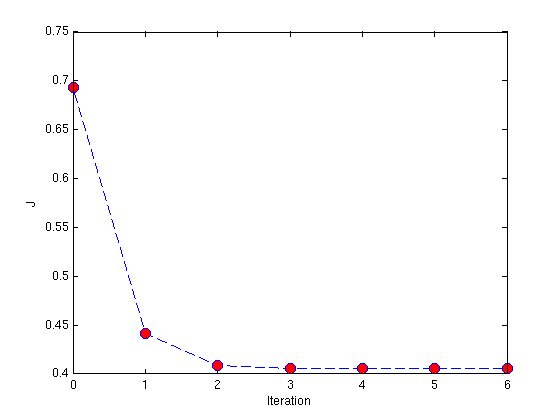
From this plot, you can infer that Newton's Method has converged by around 5 iterations. In fact, by looking at a printout of the values of J, you will see that J changes by less than ![]() between the 4th and 5th iterations. Recall that in the previous two exercises, gradient descent took hundreds or even thousands of iterations to converge. Newton's Method is much faster in comparison.
between the 4th and 5th iterations. Recall that in the previous two exercises, gradient descent took hundreds or even thousands of iterations to converge. Newton's Method is much faster in comparison.
2. The probability that a student with a score of 20 on Exam 1 and 80 on Exam 2 will not be admitted to college is 0.668.
- Logistic Regression and Newton's Method Exercise
- Exercise: Logistic Regression and Newton's Method
- Exercise 4: Logistic Regression and Newton's Method
- [Exercise 3] Logistic Regression and Newton's Method
- Logistic Regression and Newton's Method
- Exercise 4: Logistic Regressionand Newton's Method
- Logistic regression ,Softmax regression and Newton's method
- 逻辑回归和牛顿法 Logistic Regression and Newton's Method
- Machine Learning Logistic Regression and Newton's Method Andrew Ng 课程练习 Matlab Script 详细解析
- [机器学习实验3]Logistic Regression and Newton Method
- 第三讲之 Logistic Regression(method:Gradient descent and Newton)
- Newton's method Drawback and advantage
- Lesson 4 Part 1 Newton's method
- Newton's method
- Matlab Newton‘s method
- SUMMARIZE:Newton's method
- Softmax Regression and Logistic Regression
- Linear Regression and Logistic Regression
- JS移除数组中的某个元素而得到新数组
- Exercise 2: Linear Regression
- anti-pattern for web page design
- 清除动态创建DIV的方法
- Exercise 3: Multivariate Linear Regression
- Exercise 4: Logistic Regression and Newton's Method
- msserver 将sql字符串分割为Table (splitToTable)
- 在css中如何让一个图片铺满全屏
- 把一个DataTable对象转换成一个数组对象
- 基于开源 Openfire 聊天服务器 - 开发Openfire 聊天记录插件
- HDU1010-Tempter of the Bone(DFS+各种剪枝)
- 谷歌浏览器开发工具使用教程
- js中js数组、对象与json之间的转换
- Delphi预编译


