Linux System Programming --Chapter Two
来源:互联网 发布:珠峰js培训视频下载 编辑:程序博客网 时间:2024/05/18 17:27
 首先,需要解释的东西是Linux系统调用
首先,需要解释的东西是Linux系统调用
一、 什么是系统调用
在Linux的世界里,我们经常会遇到系统调用这一术语,所谓系统调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核中实现的,再通过一定的方式把系统调用给用户,一般都通过门(gate)陷入(trap)实现。系统调用是用户程序和内核交互的接口。
二、 系统调用的作用
系统调用在Linux系统中发挥着巨大的作用.如果没有系统调用,那么应用程序就失去了内核的支持。
我们在编程时用到的很多函数,如fork、open等这些函数最终都是在系统调用里实现的,比如说我们有这样一个程序:
#include <unistd.h>#include <stdio.h>int main(){ fork(); exit(0);}这里我们用到了两个函数,即fork和exit,这两函数都是glibc中的函数,但是如果我们跟踪函数的执行过程,看看glibc对fork和exit函数的实现就可以发现在glibc的实现代码里都是采用软中断的方式陷入到内核中再通过系统调用实现函数的功能的。
由此可见,系统调用是用户接口在内核中的实现,如果没有系统调用,用户就不能利用内核。
接下来,我们需要看一个经常用到的函数--perror()
头文件
#include<stdio.h> #include<stdlib.h>
注意
不可以掉了这个头文件,perror是包含在这个文件里的
void perror(const char *s); perror ("open_port");函数说明
perror ( )用 来 将 上 一 个 函 数 发 生 错 误 的 原 因 输 出 到 标 准 设备 (stderr) 。参数 s 所指的字符串会先打印出,后面再加上错误原因字符串。此错误原因依照全局变量errno 的值来决定要输出的字符串。 在库函数中有个errno变量,每个errno值对应着以字符串表示的错误类型。当你调用"某些"函数出错时,该函数已经重新设置了errno的值。perror函数只是将你输入的一些信息和现在的errno所对应的错误一起输出。
范例:
#include <stdio.h> int main(void) { FILE *fp ; fp = fopen( "/root/noexitfile", "r+" ); if ( NULL == fp ) ?{ perror("/root/noexitfile"); } return 0; }运行结果[root@localhost io]# gcc perror.c [root@localhost io]# ./a.out /root/noexitfile: No such file or directory
接下来的内容是本章的重点
文件I/O
IO分为有缓冲IO和无缓冲IO两种,具体的区别可以见下图。不带缓冲的I/O,直接调用系统调用,速度快,如函数open(), read(), write()等。而带缓冲的I/O,在系统调用前采用一定的策略,速度慢,比不带缓冲的I/O安全,如fopen(), fread() fwrite()等。
两者的区别:
1.带缓存的io操作是在标准C里面定义的(可移植),而不带缓存的io操作是POSIX中定义的(不可移植),属于系统调用。带缓存的实际上是在不带缓存的基础之上
封装了一层,维护了一个输入输出缓冲区,使之能跨OS,成为ASCI标准。
2.fread一次可以读一个结构,read在linux/unix中读二进制与普通文件没有区别。
3.fopen返回的是文件流,open返回的是文件描述符。设备文件不可以当成流式文件来用,只能用open,而在linux/unix中任何设备都是文件,都可以用open,read等。
另外,标准io又提供了3种不同方式的缓冲
1.全缓冲。即缓冲区被写满或是调用fflush后,数据才会被写入磁盘。
2.行缓冲。即缓冲区被写满或是遇到换行符时,才会进行实际的io操作。当流涉及一个终端时(标准输入和标准输出),通常使用行缓冲。
3.不缓冲 。标准io库不对字符进行缓存处理。标准出错流stderr往往是不带缓存的,使得出错信息可以尽快显示出来。


下面介绍文件IO中的基础函数。
1.open函数
open函数:调用它可以打开或者创建一个文件。
#include <fcntl.h> int open(const char *pathname, int flags) int open(const char *pathname, int flags, mode_t mode) 如果失败,返回值为-1
参数解析: pathname是要打开或者创建的文件名。flags 文件打开时候的选项, O_RDONLY以只读方式打开文件。O_WRONLY以只写方式打开文件。 O_RDWR以读、写方式打开文件。
这三个选项是必选的!
flags 可选选项:
O_APPEND 以追加方式打开文件,每次写时都写在文件末尾。
O_CREAT 如果文件不存在,则创建一个,存在则打开它。
O_EXCL 与O_CREAT一起使用时,如果文件已经存在则返回出错。
O_TRUNC 以只写或读写方式打开时,把文件截断为0
O_DSYNC 每次write时,等待数据写到磁盘上。
O_RSYNC 每次读时,等待相同部分先写到磁盘上。
O_SYNC 每次write时,等到数据写到磁盘上并接更新文件属性。
SYNC选项都会影响降低性能,有时候也取决于文件系统的实现。
mode 只有创建文件时才使用此参数,指定文件的访问权限。模式有:
S_IRWX[UGO] 可读 可写 可执行
S_IR[USR GRP OTH] 可读
S_IW[USR GRP OTH] 可写
S_IX[USR GRP OTH] 可执行
S_ISUID 设置用户ID
S_ISGID 设置组ID
U->user G->group O->others
2.creat函数
creat 以只写方式创建一个文件,若文件已经存在,则把它截断为0
#include <fcntl.h> int creat(const char *pathname, mode_t mode) 参数解析:
pathname 要创建的文件名称mode 跟open的第三个参数相同,可读,可写,可执行 。如果失败 ,返回值为-1
creat函数等同于 open (pathname, O_WRONLY | O_CREAT | O_TRUNC, mode)
3.close函数
close 关闭已经打开的文件,并释放文件描述符
#include <unistd.h> int close(int filedes) 参数解析:filedes 文件描述符,有open或者creat返回的非负整数。
如果失败,返回值为-1
当一个进程结束时,操作系统会自动释放该进程打开的所有文件。但还是推荐用close来关闭文件。
lsof命令可以查看进程打开了那些文件。
4.lseek函数
lseek 用来定位当前文件偏移量,既你对文件操作从文件的那一部分开始。
#include <unistd.h> off_t lseek(int filedes, off_t offset, int whence); 如果失败,返回值为-1,成功返回移动后的文件偏移量。
参数解析:filedes 文件描述符。offset 必须与whence一同解析
whence为 SEEK_SET, 则offset从文件的开头算起。
whence为 SEEK_CUR, 则offset从当前位置算起,既新偏移量为当前偏移量加上offset
whence为 SEEK_END, 则offset从文件末尾算起。
可以通过lseek、write来快速创建一个大文件。
5.read函数
read 从当前文件偏移量处读入指定大小的文件内容
#include <unistd.h> ssize_t read(int filedes, void *buf, size_t nbytes) 失败返回-1, 成功返回读入的字节数,到文件末尾返回0
参数解析 filedes 文件描述符 ,有open返回。buf 读入文件内容存放的内存首地址。nbytes 要读取的字节数。
实际读入的字节数可能会小于要求读入的字节数。比如文件只有所剩的字节数小于你要读入的字节数,读取fifo文件和网络套接字时都可能出现这种情况。
ssize_t ret;while(len != 0 && (ret = read(fd , buf , len)) != 0){if(ret == -1){if(errno == EINTR)continue;perror("read");break;}len -= ret;buf +=ret;}6.write函数
write向一个文件写入一定字节的内容。
#include <unistd.h> ssize_t write(int filedes, const void * buff, size_t nbytes) 失败返回-1,成功返回实际写入的字节数。当磁盘满或者文件到达上限时可能写入失败。
一般从当前文件偏移量出写入,但如果打开时使用了O_APPEND,那么无论当前文件偏移量在哪里,都会移动到文件末尾写入。
ssize_t ret;while(len != 0 && (ret = write(fd , buf , len)) != 0){if(ret == -1){if(errno == EINTR)continue;perror("write");break;}len -= ret;buf +=ret;} 以上都是文件IO最基本的几个函数,那么linux的IO是怎么实现的呢?内核使用了三种数据结构,来实现I/O
1. 每个进程在进程表中都有一个记录项,每个记录项中有一张打开文件描述符表,可将其视为一个矢量,每个描述符占用一项。与每个 文 件描述符相关联的是:
(a) 文件描述符标志。
(b) 指向一个文件表项的指针。
2. 内核为所有打开文件维持一张文件表。每个文件表项包含:
(a) 文件状态标志(读、写、增写、同步等)。
(b) 当前文件位移量。
(c) 指向该文件v节点表项的指针。
3. 每个打开文件(或设备)都有一个v节点结构。v节点包含了文件类型和对此文件进行各种操作的函数的指针信息。对于大多数文件, v节点还包含了该文件的i节点(索引节点)。例如, i节点包含了文件的所有者、文件长度、文件所在的设备、指向文件在盘上所使用的实际数据块的指针等等
如下图所示,内核中的数据结构
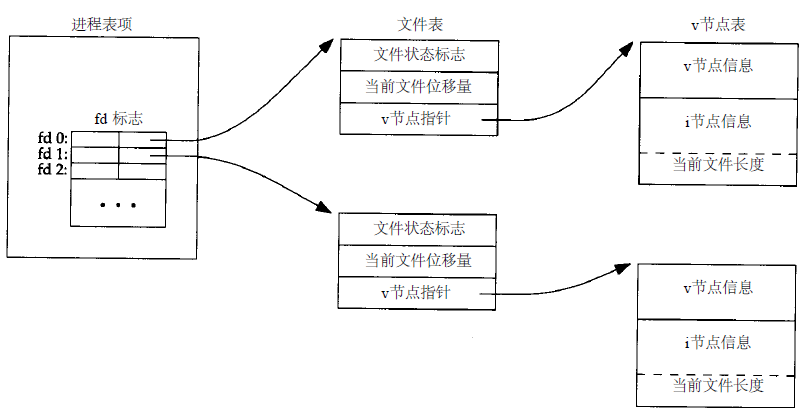
两个文件各自打开同一个文件,它们拥有各自的文件表项,但共享v节点表。见下图所示

什么是原子操作?
A B两个进程以O_APPEND方式打开同一个文件。A 进程去写该文件,假设此时文件偏移量为1000,B进程同时去写该文件,此时由于A进程未写完,则B进程得到的文件偏移量仍为1000。最后B进程的内容可能会覆盖掉A进程写的内容。pread , pwrite是原子读写操作。相当于先把文件偏移量定位到offset,然后在进行读写。这都是一步完成,不存在竞争问题。
#include <unistd.h> ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset) ssize_t pwrite(int filedes, const void *buf, size_t nbytes, off_t offset)
返回值跟read和write一样。offset为文件偏移量。
下面介绍一些文件IO中比较高级的函数。dup(),fcntl(),sync()等。
1.dup函数
dup/dup2用来复制一个已经存在的文件描述符
#include <unistd.h> int dup(int filedes) ; int dup2(int filedes, int filedes2) ; 失败返回-1,成功返回新文件描述符。filedes2是新文件描述符,如果已经打开则先关闭它。
ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset);
共享文件表项。
2.fcntl函数
fcntl 可以改变已经打开的描述符。
#include <unistd.h> #include <fcntl.h> int fcntl(int fd, int cmd) int fcntl(int fd, int cmd, long arg)
参数解析:
第一个为已经打开的文件描述符
第二个为要对文件描述采取的动作
F_DUPFD 复制一个文件描述,返回值为新描述符。
F_GETFD/F_SETFD 目前只有FD_CLOEXEC一个,set时候会用到第三个参数。
F_GETFL / F_SETFL 得到或者设置目前的文件描述符属性,返回值为当前属性。设置时使用第三个参数。
3.sync函数
#include <unistd.h> int fsync(int filedes) //把指定文件的数据和属性写入到磁盘。 int fdatasync(int filedes) //把指定文件的数据部分写到磁盘。 void sync(void) //把修改部分排入磁盘写队列,但并不意味着已经写入磁盘。
下面给出一个测试程序
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <fcntl.h> #include <string.h> int main(void) { int fd, fdd, ret; char str[]="hello world!"; char buf[10]; fd = open("file", O_RDWR|O_CREAT|O_TRUNC, 755); if(fd < 0){ perror("open error"); exit(1); } ret = write(fd, str, sizeof(str)); if(ret != sizeof(str)){ perror("write error"); exit(1); } fdd = dup(fd); if(ret == -1){ perror("dup error"); exit(1); } lseek(fdd, 6, SEEK_SET); memset(buf,0,sizeof(buf)); ret = read(fdd, buf, sizeof(buf)); if(ret < 0){ perror("read error"); exit(1); } printf("%s\n",buf); return 0; } 下面介绍另一个也是非常重要的主题--多任务式 I/O表头文件
#include<sys/time.h>#include<sys/types.h>#include<unistd.h>
定义函数
int select(int n,fd_set * readfds,fd_set * writefds,fd_set * exceptfds,struct timeval * timeout);
函数说明
select()用来等待文件描述词状态的改变。参数n代表最大的文件描述词加1,参数readfds、writefds 和
FD_CLR(inr fd,fd_set* set);用来清除描述词组set中相关fd 的位FD_ISSET(int fd,fd_set *set);用来测试描述词组set中相关fd 的位是否为真FD_SET(int fd,fd_set*set);用来设置描述词组set中相关fd的位FD_ZERO(fd_set *set); 用来清除描述词组set的全部位参数
timeout为结构timeval,用来设置select()的等待时间,其结构定义如下
struct timeval{time_t tv_sec;time_t tv_usec;};返回值
如果参数timeout设为NULL则表示select()没有timeout。
错误代码
执行成功则返回文件描述词状态已改变的个数,如果返回0代表在描述词状态改变前已超过timeout时间,当
EBADF 文件描述词为无效的或该文件已关闭
EINTR 此调用被信号所中断
EINVAL 参数n 为负值。
ENOMEM 核心内存不足
常见的程序片段:
fs_set readset;FD_ZERO(&readset);FD_SET(fd,&readset);select(fd+1,&readset,NULL,NULL,NULL);if(FD_ISSET(fd,readset){……}在标准输入读取9个字节数据。用select函数实现超时判断!
#include <stdio.h>#include <string.h>#include <unistd.h>#include <sys/time.h>#include <sys/types.h>int main(int argc, char ** argv){ char buf[10] = ""; fd_set rdfds;// struct timeval tv; //store timeout int ret; // return val FD_ZERO(&rdfds); //clear rdfds FD_SET(1, &rdfds); //add stdin handle into rdfds tv.tv_sec = 3; tv.tv_usec = 500; ret = select(1 + 1, &rdfds, NULL, NULL, &tv); if(ret < 0) perror("\nselect"); else if(ret == 0) printf("\ntimeout"); else { printf("\nret=%d", ret); } if(FD_ISSET(1, &rdfds)) { printf("\nreading"); fread(buf, 9, 1, stdin); // read form stdin }// read(0, buf, 9); /* read from stdin */// fprintf(stdout, "%s\n", buf); /* write to stdout */ write(1, buf, strlen(buf)); //write to stdout printf("\n%d\n", strlen(buf)); return 0;}内核内部inode是什么?
使用ls -i命令,可以看到文件名对应的inode号码:
页高速缓存是linux内核实现的一种主要磁盘缓存,它主要用来减少对磁盘的IO操作,具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。为什么要这么做呢?
一,速度,访问磁盘的速度要远低于访问内存的速度
二临时局部原理,短时期内集中访问同一片数据的原理。
有关这两个概念,相信熟悉操作系统的我们不会太陌生。页高速缓存是由RAM中的物理页组成的,缓存中的每一页都对应着磁盘中的多个块。每当内核开始执行一个页IO操作时,就先到高速缓存中找。这样就可以大大减少磁盘操作。
一个物理页可能由多个不连续的物理磁盘块组成。也正是由于页面中映射的磁盘块不一定连续,所以在页高速缓存中检测特定数据是否已被缓存就变得不那么容易了。另外linux页高速缓存对被缓存页的范围定义的非常宽。缓存的目标是任何基于页的对象,这包含各种类型的文件和各种类型的内存映射。
首先,在页高速缓存中搜索需要的页,如果需要的页不在高速缓存中,那么内核在高速缓存中新分配一空闲项;下一步,prepare_write()方法被调用,创建一个写请求;接着数据被从用户空间拷贝到内核缓冲;最后通过commit_write()函数将数据写入磁盘。
因为在任何页IO操作前内核都要检查页是否已经在页高速缓存中了,所以这种检查必须迅速,高效。否则得不偿失了。前边已经说过,也高速缓存通过两个参数address_space对象和一个偏移量进行搜索。每个address_space对象都有唯一的基树(radix tree),它保证在page_tree结构体中。基树是一个二叉树,只要指定了文件偏移量,就可以在基树中迅速检索到希望的数据,页高速缓存的搜索函数find_get_
page()要调用函数radix_tree_lookup(),该函数会在指定基树中搜索指定页面。基树核心代码的通用形式可以在文件lib/radix-tree.c中找到,另外想要使用基树,需要包含头文件linux/radix_tree.h.
在内存中累积起来的脏页必须被写回到磁盘,在一下两种情况下,脏页会被写会到磁盘:
1.在空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
2.当脏页在内存中驻留超过一定的阈值时,内核必须将超时的脏页写会磁盘,以确保脏页不会无限期地驻留在内存中。
3. 当用户进程调用sync()和fsync()函系统调用时,内核会按要求执行回写动作。
现在你只需知道,2.6内核中,使用pdflush后台回写例程来完成这个工作,(注:flusher线程,具体可以查看linux Kernel development, fuli ma)那么具体是怎么实现的呢:
首先,pdflush线程在系统中的空闲内存低于一个特定的阈值时,将脏页刷新回磁盘。该后台回写例程的目的在于在可用物理内存过低时,释放脏页以重新获得内存。上面提到的特定的内存阈值可以通过dirty_background_ratio系统调用设置。一旦空闲内存比这个指小时,内核便会调用函数wakeup_bdflush() 唤醒一个pdflush线程,随后pdflush线程进一步调用函数background_writeout()开始将脏页写会到磁盘,函数background_writeout()需要一个长整型参数,该参数指定试图写回的页面数目。函数background_writeout会连续地写会数据,直到满足一下两个条件:
2.空闲内存页已经回升,超过了阈值dirty_background_ration.
- Linux System Programming --Chapter Two
- Linux System Programming --Chapter Three
- Linux System Programming --Chapter Four
- Linux System Programming --Chapter Five
- Linux System Programming --Chapter Six
- Linux System Programming --Chapter Seven
- Linux System Programming --Chapter Eight
- Linux System Programming --Chapter Nine
- Beginning Linux Programming chapter 3
- Beginning Linux Programming chapter 4
- Beginning Linux Programming chapter 7
- Beginning Linux Programming chapter 11
- Beginning Linux Programming chapter 13
- 书评:Linux System Programming
- Linux system programming
- Linux System Programming -- Appendix
- 读书笔记 - Beginning Linux Programming - Chapter 2 Shell Programming
- Linux System Programming:Memory Management
- 让的PHP代码飞起来的40条小技巧(提升php效率)
- Android Bundle类
- 二叉树中和为某一值的路径
- 获取iOS各种文件路径
- 17 C# 第十五章 Linq标准查询的使用
- Linux System Programming --Chapter Two
- Win7系统下VS2008开发的程序打包步骤图解
- 堆排序实现
- SAP APO 介绍
- 日期格式化工具类DateFormat
- 超越Flat——iOS 7的救赎
- WM_COPYDATA Message
- 博客地址
- 伟大的程序员所必须具备的7项特质


