Storing Big Data With Hive: RCFile
来源:互联网 发布:imax for mac 编辑:程序博客网 时间:2024/04/27 15:54
Are sequence files or RCFile (Record Columnar File) the best way to store big data in Hive?
There are reasons to use text on the periphery of an ETL process, as the previous post discussed. (See: Storing Big Data With Hive: Text and Storing Big Data With Hive: Optimizing Text.) The inside of a Hive data processing pipeline can be optimised for performance though. Commonly, derived, intermediate tables are queried heavily. Optimising these tables speeds up the whole pipeline greatly. How can these potentially huge tables be query agnostically optimised to only read and process the relevant fraction of the data stored?
The challenge
Continuing the scenario from the previous posts: a startup ingests and transforms with Hive logs from (HDFS) filesystem containing user interactions, transactional and user data from a SQL, and factual product information from a NoSQL store. (See: Big Data Explained: What Is HDFS?.) The business questions arising now are around slicing and dicing the data on demand, e.g. which region sold what when, what kind of user interactions lead to sales, and so forth. Increasingly, queries become ad-hoc and demand answers within a few minutes and not potentially hours. Additionally, the data is growing and the scheduled nightly batch processing for reports and search index takes longer every day.
At the core of the ETL process, Hive parses log information and aggregates it in a dedicated table. Combinations of the log information with the user, transaction, and product information then lead to sizeable derived tables. Some of the data is planned to feed into machine learning tools for predictive analysis, clustering, and classification. Consequently, a lot of features are recorded in additional columns. The resulting tables have become numerous and large, and are central for subsequent reports and data products. Only a fraction or aggregation of the data is exported to external services and tools. Therefore text for the time being is feasible for the import and export. Internally, optimisation is needed to satisfy ad-hoc queries and maintain execution time and cost.
In scenario a central table pulls together all the data and has billions of rows with product user interactions with dozens of columns. Ideally, a specific report or a one-off query by a business stakeholder translates into reading and processing only the smallest amount of data. That requires Hive to skip the maximum amount of rows and columns whenever possible.
The solution
One way to break down the tables is to partition them and save different data in different subdirectories, e.g. split it into years, months, and days, or regions. Nevertheless, partitioning is only sensible for large predictable splits. Hive would still have to read and parse terabytes or at least gigabytes to find as little as a single value in specific column of a specific row. More importantly, doing so would waste resources and time answering the question.
In traditional DBMS, creating dedicated indices of the data solves these problems. Recent research has demonstrated that indices are attainable for Hadoop and bring tremendous performance benefits. (See: Blazingly Fast Hadoop: Discover Indexing and Blazingly Fast Hadoop: Adaptive Indexing.) There are more options available today that can further improve the performance.
Sequence file
Traditionally, Hadoop saves its data internally in flat sequence files, which is a binary storage format for key value pairs. It has the benefit of being more compact than text and fits well the map-reduce output format. Sequence files can be compressed on value, or block level, to improve its IO profile further. Unfortunately, sequence files are not an optimal solution for Hive since it saves a complete row as a single binary value. Consequently, Hive has to read a full row and decompress it even if only one column is being requested.
RCFile
The state-of-the-art solution for Hive is the RCFile. The format has been co-developed by Facebook, which is running the largest Hadoop and Hive installation in the world. RCFile has been adopted by the Hive and Pig projects as the core format for table like data storage. The goal of the format development was "(1) fast data loading, (2) fast query processing, (3) highly efficient storage space utilization, and (4) strong adaptivity to highly dynamic workload patterns," as can be seen in this PDF from the development teams.
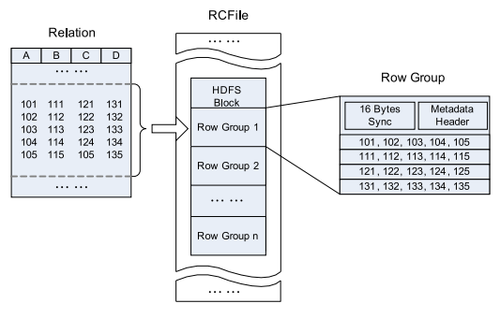
The RCFile splits data horizontally into row groups. For example, rows 1 to 100 are stored in one group and rows 101 to 200 in the next and so on. One or several groups are stored in a HDFS file. The RCFile saves the row group data in a columnar format. So instead of storing row one then row two, it stores column one across all rows then column two across all rows and so on.
The benefit of this data organization is that Hadoop's parallelism still applies since the row groups in different files are distributed redundantly across the cluster and processable at the same time. Subsequently, each processing node reads only the columns relevant to a query from a file and skips irrelevant ones. Additionally, compression on a column base is more efficient. It can take advantage of similarity of the data in a column.
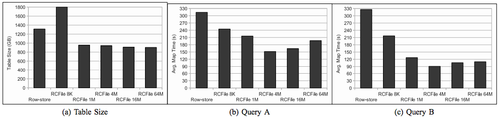
Storing the intermediate tables as (compressed) RCFile reduces the IO and storage requirements significantly over text, sequence file, and row formats in general. Querying tables stored in RCFile format allows Hive to skip large parts of the data and get the results faster and cheaper. An experiment, from the original RCFile paper, with Facebook data with a 1.3 TB table with 38 columns containing ad-click data, demonstrates that RCFile tables are smaller and can be more than three times faster in processing.
The last part of this series will review the most recent evolution of this storage format, the ORC (Optimized Row Columnar) file format. ORC provides exciting, substantial improvements beyond RCFile.
Related posts:
- Big Data Explained: What Is HDFS?
- Storing Big Data With Hive: Optimizing Text
- Big Data Explained: What Is HDFS?
- Big Data Explained: What Is Pig?
- Storing Big Data With Hive: RCFile
- Storing Big Data with HBase
- Big Data with MATLAB
- Pentaho Work with Big Data(四)—— 转换Hive里的数据
- Data Mining with Big Data--阅读笔记
- Storing data in browser
- Hive中的RCFile
- hive的文件格式-RCfile
- Hive文件格式(RCFILE)
- hive rcfile存储格式
- hive rcfile存储格式
- hive rcfile存储格式
- hive rcfile存储格式
- hive中使用rcfile
- Use Cases > Storing Log Data
- HIVE RCFile高效存储结构
- HIVE RCFile高效存储结构
- HIVE RCFile高效存储结构
- Gallery 3D+倒影 滑动切换图片示例
- 第7章:函数
- [osg]OSG中的图元控制
- AS3 DragManager ---- 自己写个拖动管理器
- C++面试出现频率最高的30道题目(一)
- Storing Big Data With Hive: RCFile
- ASP.Net编程问题总结
- tomcat部署web项目的3中方法.txt
- Oracle分析函数
- Notification与NotificationManager详细介绍
- linux 下开发服务性能评估参考表
- 编写使用root权限的android应用程序
- Ubuntu 常见错误: could not get lock /var/lib/dpkg/lock
- [osg]源码分析:osg::StateSet


