Java Collection
来源:互联网 发布:淘宝店铺添加客服帐号 编辑:程序博客网 时间:2024/05/17 07:56
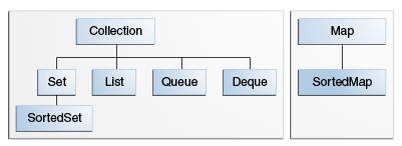
add/get/remove 操作Collection时遇到异常直接抛出,offer/peek/poll则不会,会返回一些特殊值。
Queue — Besides basic Collection operations, a Queue provides additional insertion, extraction, and inspection operations.Queues typically, but do not necessarily, order elements in a FIFO (first-in, first-out) manner.Among the exceptions are priority queues, which order elements according to a supplied comparator or the elements' natural ordering. (比如:PriorityQueue(int initialCapacity,Comparator<? superE> comparator) ) Whatever the ordering used, the head of the queue is the element that would be removed by a call to remove or poll. In a FIFO queue, all new elements are inserted at the tail of the queue. Other kinds of queues may use different placement rules. Every Queue implementation must specify its ordering properties. BlockingQueue都是线性安全的么?是的,并且“并发队列”加上了一些PutifAbsent之类的封装好的函数。
Deque — 是double ended queue的简写,Besides basic Collection operations, a Deque provides additional insertion, extraction, and inspection operations. Deques can be used both as FIFO (first-in, first-out) and LIFO (last-in, first-out). In a deque all new elements can be inserted, retrieved and removed at both ends. Deque 实现对FIFO和LIFO的支持通过add/offer Last or First 和 get/poll Last or First实现,即相当于在queue的基础上加上了First和Last表示哪个端的称呼。
SortedSet — a Set that maintains its elements in ascending order. Several additional operations are provided to take advantage of the ordering,比如first()和last,subSet(fromE,toE),这些方法都是根据compartor比较得到的顺序有关. ASet that further provides atotal ordering on its elements.The elements are ordered using their natural ordering, or by a Comparator typically provided at sorted set creation time.所有要进行排序的都可使用Comparator,比如PriorityQueue因为涉及到优先级,也要使用comparator进行比较。SortedMap — a Map that maintains its mappings in ascending key order. This is the Map analog of SortedSet.注意:This order is reflected when iterating over the sorted map's collection views (returned by the entrySet,keySet andvalues methods). Several additional operations are provided to take advantage of the ordering.
Collection Interface Bulk Operations
Bulk operations perform an operation on an entire Collection. You could implement these operations using the basic operations, though in most cases such implementations would be less efficient. The following are the bulk operations:
containsAll— returnstrueif the targetCollectioncontains all of the elements in the specifiedCollection.addAll并集 — adds all of the elements in the specifiedCollectionto the targetCollection.removeAll减集 — removes from the targetCollectionall of its elements that are also contained in the specifiedCollection.retainAll交集 — it retains only those elements in the targetCollectionthat are also contained in the specifiedCollection.clear— removes all elements from theCollection.
The toArray methods are provided as a bridge between collections and older APIs that expect arrays on input. The array operations allow the contents of a Collection to be translated into an array.
The Set interface contains only methods inherited from Collection and adds the restriction that duplicate elements are prohibited. Set also adds a stronger contract on the behavior of the equals and hashCode operations(equals和hashCode用于比较Element是否相同), allowing Set instances to be compared meaningfully even if their implementation types differ.
The Java platform contains three general-purpose Set implementations: HashSet, TreeSet, and LinkedHashSet.
HashSet, which stores its elements in a hash table, is the best-performing implementation; however it makes no guarantees concerning the order of iteration.
TreeSet, which stores its elements in a red-black tree,orders its elements based on their values; it is substantially slower than HashSet,注意 treeSet实现了SortedSet接口,故TreeSet的排序中的order或者自然顺序或者comparator顺序.
LinkedHashSet, which is implemented as a hash table with a linked list running through it, orders its elements based on the order in which they were inserted into the set (insertion-order).LinkedHashSet spares its clients from the unspecified, generally chaotic ordering provided by HashSet at a cost that is only slightly higher. 即LinkedHashSet比HashSet强一点的是前者是根据插入顺序来遍历Element,而后者的顺序完全不可考,只是前者可能比后者性能稍差,总体而言这三个中HashSet性能最好,因为它对顺序神马的完全不在乎。
因为Set不允许重复值,所以可以根据这个属性,将具有重复值的集合作为Set构造器的参数,然后得到的集合就是去掉重复的了。比如HashSet()
Here's a simple but useful Set idiom. Suppose you have a Collection, c, and you want to create another Collection containing the same elements but with all duplicates eliminated. The following one-liner does the trick.
Collection<Type> noDups = new HashSet<Type>(c);
Here is a minor variant of this idiom that preserves the order of the original collection while removing duplicate element.
Collection<Type> noDups = new LinkedHashSet<Type>(c);
The following is a generic method that encapsulates the preceding idiom, returning a Set of the same generic type as the one passed.
public static <E> Set<E> removeDups(Collection<E> c) { return new LinkedHashSet<E>(c);}Set Interface Bulk Operations
Bulk operations are particularly well suited to Sets; when applied, they perform standard set-algebraic operations. Suppose s1 and s2 are sets. Here's what bulk operations do:
s1.containsAll(s2)— returnstrueifs2is a subset ofs1. (s2is a subset ofs1if sets1contains all of the elements ins2.)s1.addAll(s2)— transformss1into the union ofs1ands2. (The union of two sets is the set containing all of the elements contained in either set.)s1.retainAll(s2)— transformss1into the intersection ofs1ands2. (The intersection of two sets is the set containing only the elements common to both sets.)s1.removeAll(s2)— transformss1into the (asymmetric) set difference ofs1ands2. (For example, the set difference ofs1minuss2is the set containing all of the elements found ins1but not ins2.)
To calculate the union, intersection, or set difference of two sets nondestructively(without modifying either set), the caller must copy one set before calling the appropriate bulk operation. The following are the resulting idioms.
下面这一小段是求的并集-交集-差集
Set<Type> union = new HashSet<Type>(s1);union.addAll(s2);Set<Type> intersection = new HashSet<Type>(s1);intersection.retainAll(s2);Set<Type> difference = new HashSet<Type>(s1);difference.removeAll(s2);
The List Interface
A List is an ordered Collection (sometimes called a sequence). Lists may contain duplicate elements. In addition to the operations inherited from Collection, the List interface includes operations for the following:
Positional access 位置即时访问— manipulates elements based on their numerical position in the listSearch— searches for a specified object in the list and returns its numerical positionIteration— extendsIteratorsemantics to take advantage of the list's sequential natureRange-view— performs arbitrary range operations on the list. Set中除了有顺序的Set可以返回sub之外,其他不可。
The Java platform contains two general-purpose List implementations. ArrayList which is usually the better-performing implementation, and LinkedList which offers better performance under certain circumstances. Also, Vector has been retrofitted to implement List.
The Arrays class has a static factory method called asList,which allows an array to be viewed as a List. This method does not copy the array. Changes in the List write through to the array and vice versa. The resulting List is not a general-purpose List implementation, because it doesn't implement the (optional) add and remove operations: Arrays are not resizable. Taking advantage of Arrays.asList and calling the library version of shuffle, which uses a default source of randomness, you get the following tiny program whose behavior is identical to the previous program.
import java.util.*;public class Shuffle { public static void main(String[] args) { List<String> list = Arrays.asList(args); Collections.shuffle(list); System.out.println(list); }}As you'd expect, the Iterator returned by List's iterator operation returns the elements of the list in proper sequence. List also provides a richer iterator, called a ListIterator, which allows you to traverse the list in either direction,modify the list during iteration, and obtain the current position of the iterator. The ListIterator interface follows.而其他Set,Map和Queue则没有提供ListIterator。
The range-view operation, subList(int fromIndex, int toIndex), returns a List view of the portion of this list whose indices range from fromIndex, inclusive, to toIndex, exclusive. As the term view implies, the returned List is backed up by the List on which subList was called, so changes in the former are reflected in the latter.
List Algorithms
Most polymorphic algorithms in the Collections class apply specifically to List. Having all these algorithms at your disposal makes it very easy to manipulate lists. Here's a summary of these algorithms, which are described in more detail in the Algorithms section. Sort和reverse都涉及到排序,只要涉及到排序那么就或者使用自然顺序(默认)或者传递comparator参数
sort— sorts aListusing a merge sort algorithm 归并排序, which provides a fast, stable sort. (A stable sort is one that does not reorder equal elements.)shuffle— randomly permutes the elements in aList.reverse— reverses the order of the elements in aList.rotate— rotates all the elements in aListby a specified distance.swap— swaps the elements at specified positions in aList.replaceAll— replaces all occurrences of one specified value with another.fill— overwrites every element in aListwith the specified value.copy— copies the sourceListinto the destinationList.binarySearch— searches for an element in an orderedListusing the binary search algorithm.由此可以小结一下,至此用到的一些算法,TreeSet的底层实现是用红黑树实现的,List中的默认排序方法是合并排序,搜索是二分查找。indexOfSubList— returns the index of the first sublist of oneListthat is equal to another.lastIndexOfSubList— returns the index of the last sublist of oneListthat is equal to another.
The Queue Interface
Each Queue method exists in two forms: (1) one throws an exception if the operation fails, and (2) the other returns a special value if the operation fails (either null or false, depending on the operation). The regular structure of the interface is illustrated in the following table.
add(e)offer(e)Removeremove()poll()Examineelement()peek()
The Queue interface does not define the blocking queue methods, which are common in concurrent programming. These methods, which wait for elements to appear or for space to become available, are defined in the interface java.util.concurrent.BlockingQueue, which extends Queue.
Java中Stack的实现是继承了Vector,而Vector是实现了List接口,但是更好的实现是通过Deque来实现Stack. A more complete and consistent set of LIFO stack operations is provided by theDeque interface and its implementations, which should be used in preference to this class.
Deque<Integer> stack = new ArrayDeque<Integer>();The Deque Interface
The Deque interface is a richer abstract data type than both Stack and Queue because it implements both stacks and queues at the same time. The Deque interface, defines methods to access the elements at both ends of the Deque instance. Methods are provided to insert, remove, and examine the elements. Predefined classes like ArrayDeque and LinkedList implement the Deque interface. 以下接口中的add/remove/get,与offer/poll/peek都是成对出现,分别对First和Last即头部和尾端进行操作,依照惯例失败时,前三者都是会抛出exception的,后三者会return NULL
Insert
The addfirst and offerFirst methods insert elements at the beginning of the Deque instance. The methods addLast and offerLast insert elements at the end of the Deque instance. When the capacity of the Deque instance is restricted, the preferred methods are offerFirst andofferLast because addFirst might fail to throw an exception if it is full.
Remove
The removeFirst and pollFirst methods remove elements from the beginning of the Dequeinstance. The removeLast and pollLast methods remove elements from the end. The methodspollFirst and pollLast return null if the Deque is empty whereas the methods removeFirst andremoveLast throw an exception if the Deque instance is empty.
Retrieve
The methods getFirst and peekFirst retrieve the first element of the Deque instance. These methods dont remove the value from the Deque instance. Similarly, the methods getLast andpeekLast retrieve the last element. The methods getFirst and getLast throw an exception if the deque instance is empty whereas the methods peekFirst and peekLast return NULL.
The 12 methods for insertion, removal and retieval of Deque elements are summarized in the following table:
Deque instance)Deque instance)addFirst(e)offerFirst(e)addLast(e)offerLast(e)RemoveremoveFirst()pollFirst()removeLast()pollLast()ExaminegetFirst()peekFirst()getLast()peekLast()In addition to these basic methods to insert,remove and examine a Deque instance, the Deque interface also has some more predefined methods. One of these is removeFirstOccurence, this method removes the first occurence of the specified element if it exists in the Dequeinstance. If the element does not exist then the Deque instance remains unchanged. Another similar method is removeLastOccurence; this method removes the last occurence of the specified element in the Deque instance. The return type of these methods is boolean, and they return true if the element exists in the Deque instance.
The Map Interface
A Map is an object that maps keys to values.
Map implementations: HashMap, TreeMap, and LinkedHashMap. Their behavior and performance are precisely analogous to HashSet, TreeSet, and LinkedHashSet, as described in The Set Interface section. Also, Hashtable was retrofitted to implement Map. 即HashMap和HashTable都可看作是Map,都实现了Map的接口。The basic operations of Map (put, get, containsKey, containsValue, size, and isEmpty) behave exactly like their counterparts in Hashtable. Hashtable has a method called contains, which returns true if the Hashtable contains a given value
The Collection view methods allow a Map to be viewed as a Collection in these three ways:
keySet— theSetof keys contained in theMap.values— TheCollectionof values contained in theMap. ThisCollectionis not aSet, because multiple keys can map to the same value.entrySet— theSetof key-value pairs contained in theMap. TheMapinterface provides a small nested interface calledMap.Entry, the type of the elements in thisSet.
Comparable, Collections.sort(list) will throw a ClassCastException. Similarly, Collections.sort(list, comparator) will throw a ClassCastException if you try to sort a list whose elements cannot be compared to one another using the comparator.Writing Your Own Comparable Types
The Comparable interface consists of the following method. Comparable的接口中的compareTo返回的int值表示比较结果
public interface Comparable<T> { public int compareTo(T o);}The compareTo method compares the receiving object with the specified object and returns a negative integer, 0, or a positive integer depending on whether the receiving object is less than, equal to, or greater than the specified object. If the specified object cannot be compared to the receiving object, the method throws a ClassCastException.
The following class representing a person's name implements Comparable.
import java.util.*;public class Name implements Comparable<Name> { private final String firstName, lastName; public Name(String firstName, String lastName) { if (firstName == null || lastName == null) throw new NullPointerException(); this.firstName = firstName; this.lastName = lastName; } public String firstName() { return firstName; } public String lastName() { return lastName; } public boolean equals(Object o) { if (!(o instanceof Name)) return false; Name n = (Name) o; return n.firstName.equals(firstName) && n.lastName.equals(lastName); } public int hashCode() { return 31*firstName.hashCode() + lastName.hashCode(); } public String toString() {return firstName + " " + lastName; } public int compareTo(Name n) { int lastCmp = lastName.compareTo(n.lastName); return (lastCmp != 0 ? lastCmp : firstName.compareTo(n.firstName)); }}Sets or as keys in Maps. The hashCode method is redefined. This is essential for any class that redefines the equals method. (Equal objects must have equal hash codes.) WHY? 据我理解,应该是hashcode肯定是用于做Hash到时候使用,那么如果两个对象都可以作为Key的时候,如果相等,必须有相同的HashCode.
What if you want to sort some objects in an order other than their natural ordering? Or what if you want to sort some objects that don't implement Comparable? To do either of these things, you'll need to provide a Comparator — an object that encapsulates an ordering. Like the Comparable interface, the Comparator interface consists of a single method.
public interface Comparator<T> { int compare(T o1, T o2);}The SortedSet Interface
A SortedSet is a Set that maintains its elements in ascending order, sorted according to the elements' natural ordering or according to a Comparator provided at SortedSet creation time. In addition to the normal Set operations, the SortedSet interface provides operations for the following:
Range view— allows arbitrary range operations on the sorted setEndpoints— returns the first or last element in the sorted setComparator access— returns theComparator, if any, used to sort the set
The code for the SortedSet interface follows.
public interface SortedSet<E> extends Set<E> { // Range-view SortedSet<E> subSet(E fromElement, E toElement); SortedSet<E> headSet(E toElement); SortedSet<E> tailSet(E fromElement); // Endpoints E first(); E last(); // Comparator access Comparator<? super E> comparator();}The SortedMap Interface
A SortedMap is a Map that maintains its entries in ascending order, sorted according to the keys' natural ordering, or according to a Comparator provided at the time of the SortedMapcreation. Natural ordering and Comparators are discussed in the Object Ordering section. The SortedMap interface provides operations for normal Map operations and for the following:
Range view— performs arbitrary range operations on the sorted mapEndpoints— returns the first or the last key in the sorted mapComparator access— returns theComparator, if any, used to sort the map
The following interface is the Map analog of SortedSet.
public interface SortedMap<K, V> extends Map<K, V>{ Comparator<? super K> comparator(); SortedMap<K, V> subMap(K fromKey, K toKey); SortedMap<K, V> headMap(K toKey); SortedMap<K, V> tailMap(K fromKey); K firstKey(); K lastKey();}There are two special-purpose Set implementations — EnumSet and CopyOnWriteArraySet.
EnumSet is a high-performance Set implementation for enum types. All of the members of an enum set must be of the same enum type. Internally, it is represented by a bit-vector, typically a single long. Enum sets support iteration over ranges of enum types. For example, given the enum declaration for the days of the week, you can iterate over the weekdays. The EnumSet class provides a static factory that makes it easy.
for (Day d : EnumSet.range(Day.MONDAY, Day.FRIDAY)) System.out.println(d);
Enum sets also provide a rich, typesafe replacement for traditional bit flags.
EnumSet.of(Style.BOLD, Style.ITALIC)
CopyOnWriteArraySet(thread-safe) is a Set implementation backed up by a copy-on-write array. All mutative operations, such as add, set, and remove, are implemented by making a new copy of the array; no locking is ever required. Even iteration may safely proceed concurrently with element insertion and deletion. Unlike most Set implementations, the add, remove, and contains methods require time proportional to the size of the set.This implementation isonly appropriate for sets that are rarely modified but frequently iterated. It is well suited to maintaining event-handler lists that must prevent duplicates.
Sample Usage. The following code sketch uses a copy-on-write set to maintain a set of Handler objects that perform some action upon state updates.
class Handler { void handle(); ... } class X { private final CopyOnWriteArraySet<Handler> handlers = new CopyOnWriteArraySet<Handler>(); public void addHandler(Handler h) { handlers.add(h); } private long internalState; private synchronized void changeState() { internalState = ...; } public void update() { changeState(); for (Handler handler : handlers) handler.handle(); } } CopyOnWriteArrayList is a List implementation backed up by a copy-on-write array. A thread-safe variant of ArrayList in which all mutative operations (add, set, and so on) are implemented by making a fresh copy of the underlying array. This implementation is similar in nature to CopyOnWriteArraySet.No synchronization is necessary, even during iteration, and iterators are guaranteed never to throwConcurrentModificationException. This implementation is well suited to maintaining event-handler lists, in which change is infrequent, and traversal is frequent and potentially time-consuming. CopyOnWriteArrayList的实现中只对写的时候才进行加锁,然后copy和修改,然后替换原来的引用,为修改后的List的引用,而在读的时候,不涉及到同步。
If you need synchronization, a Vector will be slightly faster than an ArrayList synchronized with Collections.synchronizedList. But Vector has loads of legacy operations, so be careful to always manipulate the Vector with the List interface or else you won't be able to replace the implementation at a later time.
If your List is fixed in size — that is, you'll never use remove, add, or any of the bulk operations other than containsAll — you have a third option that's definitely worth considering. See Arrays.asList in the Convenience Implementations section for more information.
Concurrent Map Implementations
The java.util.concurrent package contains the ConcurrentMap interface,which extends Map with atomic putIfAbsent, remove, and replace methods, and the ConcurrentHashMap implementation of that interface.
ConcurrentHashMap is a highly concurrent, high-performance implementation backed up by a hash table.即比较重要的是ConcurrentHashMap是使用Hashtable来实现的 This implementation never blocks when performing retrievals and allows the client to select the concurrency level for updates. It is intended as a drop-in replacement for Hashtable: in addition to implementing ConcurrentMap, it supports all the legacy methods peculiar to Hashtable. Again, if you don't need the legacy operations, be careful to manipulate it with the ConcurrentMap interface.
关于putIfAbsent,Remove,Replace这三者,都是原子操作,在实现层上已经对需要的IF语句进行封装,在使用它们的时候不用再进行判断putIfAbsent原Key是否存在,Remove和Replace原Key是否存在,如果不存在就会返回false,例如Replace方法:
boolean replace(K key, V oldValue, V newValue)
- Replaces the entry for a key only if currently mapped to a given value. This is equivalent to
if (map.containsKey(key) && map.get(key).equals(oldValue)) { map.put(key, newValue); return true; } else return false;except that the action is performed atomically.
Concurrent Queue Implementations
LinkedList implements the Queue interface, providing first in, first out (FIFO) queue operations for add, poll, and so on.The java.util.concurrent package contains a set of synchronized Queue interfaces and classes. BlockingQueue extends Queue with operations that wait for the queue to become nonempty when retrieving an element and for space to become available in the queue when storing an element. This interface is implemented by the following classes:
LinkedBlockingQueue— an optionally bounded FIFO blocking queue backed by linked nodesArrayBlockingQueue— a bounded FIFO blocking queue backed by an arrayPriorityBlockingQueue— an unbounded blocking priority queue backed by a heapDelayQueue— a time-based scheduling queue backed by a heapSynchronousQueue— a simple rendezvous mechanism that uses theBlockingQueueinterface
LinkedList and ArrayDeque classes. The Dequeinterface supports insertion, removal and retrieval of elements at both ends. The ArrayDeque class is the resizable array implementation of the Deque interface, whereas the LinkedList class is the list implementation.Wrapper Implementations
Wrapper implementations delegate all their real work to a specified collection but add extra functionality on top of what this collection offers. For design pattern fans, this is an example of the decorator pattern. Although it may seem a bit exotic, it's really pretty straightforward.
Collections class, which consists solely of static methods.Synchronization Wrappers
The synchronization wrappers add automatic synchronization (thread-safety) to an arbitrary collection. Each of the six core collection interfaces — Collection, Set, List,Map, SortedSet, and SortedMap — has one static factory method.
public static <T> Collection<T> synchronizedCollection(Collection<T> c);public static <T> Set<T> synchronizedSet(Set<T> s);public static <T> List<T> synchronizedList(List<T> list);public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s);public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m);
In the face of concurrent access, it is imperative(必要的) that the user manually synchronize on the returned collection when iterating over it. The reason is that iteration is accomplished via multiple calls into the collection, which must be composed into a single atomic operation. The following is the idiom to iterate over a wrapper-synchronized collection.即对于Colletions返回的synchronized集合类,它的iterator没有加锁,用户需要自己加。
Collection<Type> c = Collections.synchronizedCollection(myCollection);synchronized(c) { for (Type e : c) foo(e);}iterator method must be called from within the synchronized block. Failure to follow this advice may result in nondeterministic behavior. The Java Collections Framework provides several general-purpose implementations of the core interfaces:
- For the
Setinterface,HashSetis the most commonly used implementation. - For the
Listinterface,ArrayListis the most commonly used implementation. - For the
Mapinterface,HashMapis the most commonly used implementation. - For the
Queueinterface,LinkedListis the most commonly used implementation. LinkedList就是Queue - For the
Dequeinterface,ArrayDequeis the most commonly used implementation.
Java的集合类主要分为两种Collection和Map。
常用集合类的继承结构如下:
Collection<--List<--Vector <--Stack
Collection<--List<--ArrayList
Collection<--List<--LinkedList(实现了Queue接口)
Collection<--Set<--HashSet
Collection<--Set<--HashSet<--LinkedHashSet
Collection<--Set<--SortedSet<--TreeSet
Map<--SortedMap<--TreeMap
Map<--HashMap
Dictionary<- HashTable
List:
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下 >标)来访问List中的元素,这类似于Java的数组。
Vector:
基于数组(Array)的List,其实就是封装了数组所不具备的一些功能方便我们使用,所以它难易避免数组的限制,同时性能也不可能超越数组。所以,在可能的情况下,我们要多运用数组。另外很重要的一点就是Vector是线程同步的(sychronized)的,这也是Vector和ArrayList 的一个的重要区别。
ArrayList:
同Vector一样是一个基于数组上的链表,但是不同的是ArrayList不是同步的。所以在性能上要比Vector好一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。
LinkedList:
LinkedList不同于前面两种List,它不是基于数组的,所以不受数组性能的限制。
它每一个节点(Node)都包含两方面的内容:
1.节点本身的数据(data);
2.下一个节点的信息(nextNode)。
所以当对LinkedList做添加,删除动作的时候就不用像基于数组的ArrayList一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了,这是LinkedList的优势。
List总结:
- 所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ]
- 所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ]
- 所有的List中可以有null元素,例如[ tom,null,1 ]
- 基于Array的List(Vector,ArrayList)适合查询,而LinkedList 适合添加,删除操作
Set: Set是一种不包含重复的元素的无序Collection。
HashSet: 虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在 HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项。看看 HashSet的add(Object obj)方法的实现就可以一目了然了。 也就是说使用Set的时候一定要对象实现Equals和Hashcode这两个方法的覆盖。
- public boolean add(Object obj) {
- return map.put(obj, PRESENT) == null;
- }
这个也是为什么在Set中不能像在List中一样有重复的项的根本原因,因为HashMap的key是不能有重复的。
LinkedHashSet: HashSet的一个子类,一个链表。
TreeSet: SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
Set总结:
- Set实现的基础是Map(HashMap)
- Set中的元素是不能重复的,如果使用add(Object obj)方法添加已经存在的对象,则会覆盖前面的对象
Map: Map 是一种把键对象和值对象进行关联的容器
Map有两种比较常用的实现:HashMap和TreeMap。
HashMap也用到了哈希码的算法,以便快速查找一个键,
TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。
键和值的关联很简单,用put(Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。
其它:
一、几个常用类的区别
1.ArrayList: 元素单个,效率高,多用于查询
2.Vector: 元素单个,线程安全,多用于查询
3.LinkedList:元素单个,多用于插入和删除
4.HashMap: 元素成对,元素可为空
5.HashTable: 元素成对,线程安全,元素不可为空
二、Vector、ArrayList和LinkedList
大多数情况下,从性能上来说ArrayList最好,但是当集合内的元素需要频繁插入、删除时LinkedList会有比较好的表现,但是它们三个性能都比不上数组,另外Vector是线程同步的。所以:
如果能用数组的时候(元素类型固定,数组长度固定),请尽量使用数组来代替List;
如果没有频繁的删除插入操作,又不用考虑多线程问题,优先选择ArrayList;
如果在多线程条件下使用,可以考虑Vector;
如果需要频繁地删除插入,LinkedList就有了用武之地;
如果你什么都不知道,用ArrayList没错。
三、Collections和Arrays
在 Java集合类框架里有两个类叫做Collections(注意,不是Collection!)和Arrays,这是JCF里面功能强大的工具,但初学者往往会忽视。按JCF文档的说法,这两个类提供了封装器实现(Wrapper Implementations)、数据结构算法和数组相关的应用。
想必大家不会忘记“折半查找”、“排序”等经典算法吧,Collections类提供了丰富的静态方法帮助我们轻松完成这些在数据结构课上烦人的工作:
binarySearch:折半查找。
sort:排序,使用的排序算法是归并排序:merge sort,效率仍然是O(n * log n),但却是一种稳定的排序方法。 一趟归并排序的操作是两个相邻的有序数组合并为一个有序数组。
reverse:将线性表进行逆序操作,这个可是从前数据结构的经典考题哦!
rotate:以某个元素为轴心将线性表“旋转”。
swap:交换一个线性表中两个元素的位置。
……
Collections还有一个重要功能就是“封装器”(Wrapper),它提供了一些方法可以把一个集合转换成一个特殊的集合,如下:
unmodifiableXXX:转换成只读集合,这里XXX代表六种基本集合接口:Collection、List、Map、Set、SortedMap和SortedSet。如果你对只读集合进行插入删除操作,将会抛出UnsupportedOperationException异常。
synchronizedXXX:转换成同步集合。
singleton:创建一个仅有一个元素的集合,这里singleton生成的是单元素Set,
singletonList和singletonMap分别生成单元素的List和Map。
空集:由Collections的静态属性EMPTY_SET、EMPTY_LIST和EMPTY_MAP表示。
LinkedList implements the Queue interface, providing first in, first out (FIFO) queue operations for add, poll, and so on.- 【java】【java Collection】Collection
- java Collection
- java collection
- Java Collection
- Java Collection
- Java Collection
- java Collection
- java Collection
- Java Collection
- Java Collection
- Java Collection
- Java Collection
- Java Collection
- Java - Collection
- java Collection
- Java Collection
- Java Collection
- Java Collection
- 虚函数中的析构函数
- ajax学习篇7
- 左右菜单
- 重复记录的查询和删除
- c# XML操作 dom sax解析
- Java Collection
- 个人品牌战略
- Java 多线程深入浅出
- 通过sscanf处理GPS信息
- Android正则表达式
- 初学者必备:C++经典入门详细教程
- 文件操作函数之ftell
- 海量数据处理面试题
- iOS JSON解析


