【Machine Learning】SVM学习笔记
来源:互联网 发布:徐老师淘宝店二维码 编辑:程序博客网 时间:2024/05/18 05:25
理解Support Vector Machine
小弟最近在研究SVM方面的理论,写这篇文章来总结一下我的理解。
首先吐个槽,外国人有个毛病,稍微整个什么新的东西出来就要起个矫情的名字,让人觉得很高深。也许是我修行不够,不能理解其深奥的含义,但是好歹也得起个好理解的名字吧,直译过来”支持向量机“,这到底什么玩意儿?其实所谓”支持向量“,就是由影响决策平面(classifier)的点和原点形成而已,稍后再叙。
1、初窥SVM.
SVM可以理解为一个比较robust的分类器,简单的SVM可以把线性可分的点集分成两个部分。
2、简单的SVM
为简单起见,以二维平面中线性可分点集{xi,yi}, i=1,...,n, y∈{-1,+1}为例,要寻找出一条直线,使其到两类点的最短距离的和最大。这个最短距离的和可以称之为margin。SVM就是要找这个直线,并且最大化margin。
上面一段提到,SVM是一个比较robust的分类器。原因就在于SVM使得margin最大化,保证在距离某一类点集一段距离内,都可以被判断为属于该点集,这样可以降低小扰动带来的影响,提高正确率。
在多维情况下,该直线变为超平面(hyperplane)。
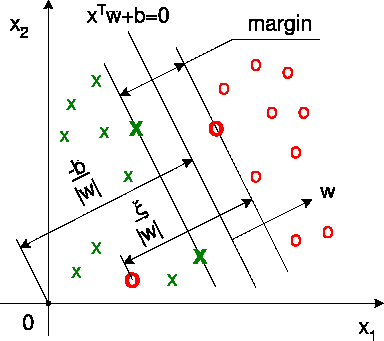
2.1、超平面(/直线)条件的确定
超平面的确定于直线相类似,w·x + b=0,其中 |b|/||w||为超平面到原点的垂直距离。只不过,这里斜率部分和自变量部分为向量表示。其算法主要是在于确定斜率向量和b中元素,以求margin最大(算法的核心就是线性规划,如果转化得当,可以用现有的linear programming solver)。
考虑用于训练的二维二元可分点集,可以得到如下约束条件:
w·xi+ b ≥ +1 (yi = +1) 【1】
w·xi+ b ≤ -1 (yi = -1) 【2】
上述两个约束条件可以总结为:
yi(w·xi+ b)-1 ≥ 0 (对于任意 i )【3】
考虑【1】中刚好在线上的点,这些点就是+1集的临界点,可以确定未知量的范围。那么在等号成立条件下【1】可以确定出来的超平面H1,到远点的距离就是
|b-1|/||w||, 同理【2】中等号成立时,确定H2,到原点距离为|b+1|/||w||,因为w相同,可以理解为H1和H2平行,那么margin就可以很方便的用上面的结果表示,即为:2/||w||。那么,最大化margin就等同于最小化||w||^2.
2.2、超平面参数确定的算法——拉格朗日乘子
2.3、【8】式如何解?!——Kernal Function
3、SVM的使用
- 【Machine Learning】SVM学习笔记
- 【Machine Learning】笔记:SVM
- machine learning week7 学习笔记 SVM 习题解答
- Machine Learning 学习笔记
- machine learning 学习笔记
- Machine Learning SVM
- Machine Learning (2) SVM
- Machine Learning---SVM
- Machine Learning---5--SVM
- Machine Learning 课程学习笔记
- 学习笔记-machine learning foundaton2
- machine learning 学习笔记<一>
- machine learning学习笔记<二>
- Machine learning学习笔记<三>
- Machine Learning学习笔记-概述
- Machine Learning机器学习 - Supervised Learning监督学习 - SVM(Support Vector Machine)
- Kaggle学习之Machine Learning from Disaster(2) -SVM
- [Machine learning]SVM实验续
- 9.从零开始学习C语言--do...while循环语句
- 推荐一个IT人必备的东西【用过的都懂,让我们的环境越来越好吧】
- c++ 类之间的相互调用问题 .
- 04-不用乘法运算符实现2*16(运算符)
- osgEarth开发数据准备(一)——原始的数据下载
- 【Machine Learning】SVM学习笔记
- cvFitLine2D
- 远程不能访问CentOS的tomcat 8080端口
- CSDN博客第二期云计算最佳博主评选
- PAT 1056
- IOS中的ViewController 的loadView、viewDidLoad、viewDidUnload
- json的js解析方法
- 提高表格操作的十五款jQuery插件
- Box2D简单封装(2.1a版)


