堆与堆排序
来源:互联网 发布:db数据库修改器 编辑:程序博客网 时间:2024/04/29 05:19
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个大根堆:

接下来是一个小根堆:

堆的操作——插入删除
下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解
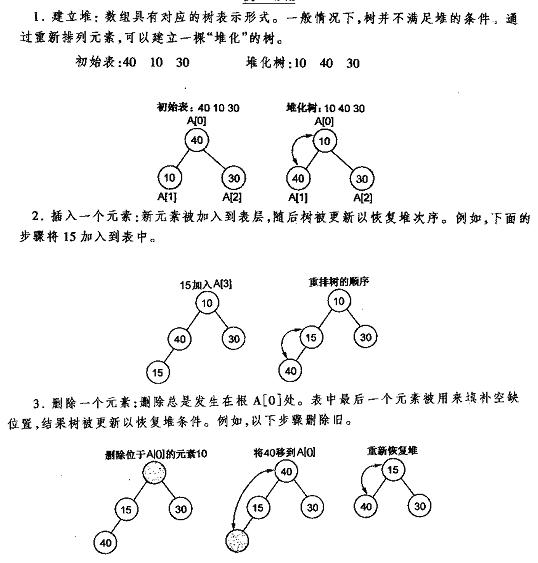
这样有什么好处呢?好处就是能方便地把指针省略掉,用一个简单的数组来表示一棵树,如图: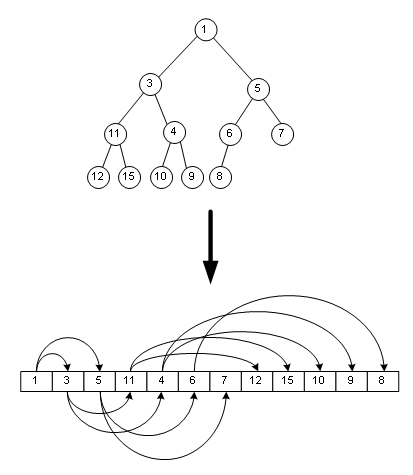
下面接着介绍一个维护方法:
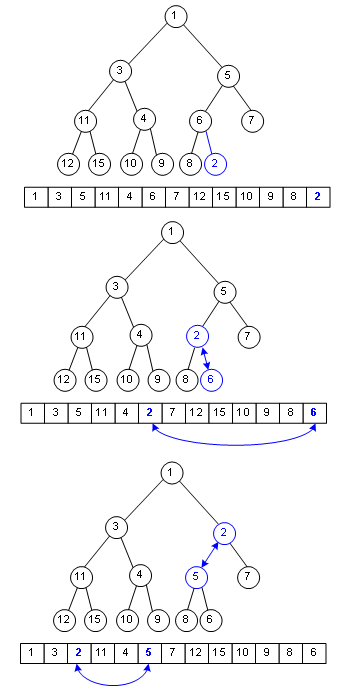
假设要在这个二叉堆里入队一个单元,键值为2,那只需在数组末尾加入这个元素,然后尽可能把这个元素往上挪,直到挪不动,经过了这种复杂度为Ο(logn)的操作,二叉堆还是二叉堆。
那如何出队呢?也不难,看图: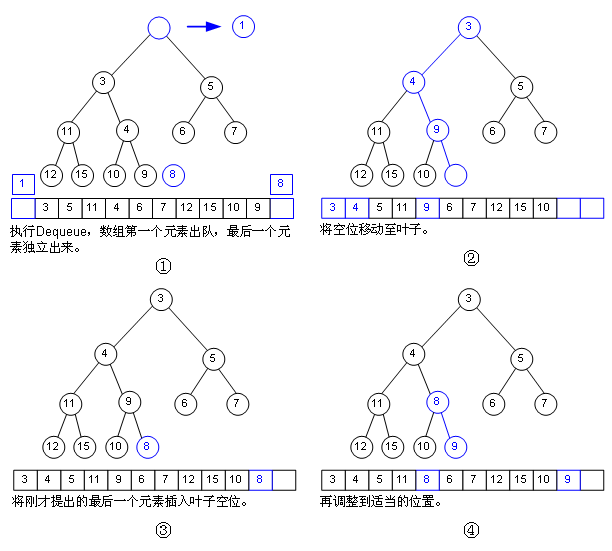
堆排序:
一个动态的堆排序过程

 [1]
[1]
 total,
total, 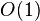 auxiliary
auxiliary下面是一个堆排序的代码:
#include <iostream>#include <stdlib.h>int data[2000],n,len;FILE *fin,*fout; void change(int &a,int &b){ //快速交换2个数 a^=b;b^=a;a^=b;} void sift(int a){//维护堆过程 int l=a*2;if (l>len) return ; if (l+1<len && data[l+1]>data[l]) l++;//选取左右子节点中最大的一个 if (data[l]>data[a]) {//比较子节点与父节点 change(data[a],data[l]);sift(l);//维护子节点堆 }}void heap_sort(){//堆排序主过程 int i;len=n;for (i=n/2;i>0;i--) sift(i);//维护以i为父节点的堆,将数据中最大的交换到data[1],即堆顶 for (i=1;i<=n;i++){change(data[1],data[len]);//交换堆顶和堆底元素 len--;//减少堆元素 sift(1); //整理堆 }}void input(){//读入元素 int i;fscanf(fin,"%d",&n);//表示读入的数为n for (i=1;i<=n;i++) fscanf(fin,"%d",&data[i]);//将n个数读入到data数组中,注意这里数组从1开始 fclose(fin);}void output(){//输出排序后结果 int i;for (i=1;i<=n;i++) fprintf(fout,"%d ",data[i]); fclose(fout);}int main(){fin=fopen("heapin.txt","r");fout=fopen("heapout.txt","w");input();heap_sort();output();return 0;}
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- 【堆与堆排序】
- 堆与堆排序
- 堆与堆排序
- 堆与堆排序
- [《think in java》学习——操作符]自增自减符号和表达式执行的顺序
- builder模式
- SQLite cursor遍历
- 用户控件与用户控件数据同步刷新;方法调用
- C#的Timer
- 堆与堆排序
- c++强制类型转换
- 哪些东西必须放在构造函数的初始化列表中?
- 提高VS2010/VS2012编译速度
- 《数据通信与网络》笔记--CSMA/CD和CSMA/CA
- (Android)API Guides/Accessing Resources
- 编程心理学
- ANDROID fastboot刷机傻瓜教程
- 浅谈搜索引擎的核心算法


