表的概念
来源:互联网 发布:兴趣部落签到软件 编辑:程序博客网 时间:2024/06/06 10:57
表的概念
我们当前环境都是用二维表来存储数据的,那表又是什么呢?Oracle是一种关系型数据库系统,在关系型数据库里,一组关系的实体化就组成了一张表。表里面有一个或多个字段,这些字段按着某种规则(称为关系,一般是业务规则)组成一个集合,这样的每一个关系,我们就成为一条记录或行。表是个十分重要的概念,无论是DBA还是研发人员大部分的工作就是和不同表打交道。
Oracle的表是如何存储的?oracle的表是按行来存储数据的。下面谈谈和存储有关的概念,oracle最小的存储单元是block(块),一般大小在2k-32k之间,默认是8k。这个oracle的block和os的block是不一样的,要远大于os的block,所以oracle的block不是io的基本单元,只是oracle的基本访问单元。对于oracle来说每个表空间都有一个唯一block大小,在oracle8i或更早版本中,整个数据库的所有表空间都有唯一block的大小,从oracle9i开始,不同的表空间可以拥有不同的表空间,因此参数db_block_size不在表示数据库块的大小,而是缺省表空间的大小。
Oracle的block的大小是最小访问单元,但他的值太小,如果表的存储按一个block一个block的大小分配,那效率太低了;为此oracle又引入了更大的单位extent(扩展),extent是oracle最小的分配单元,它是由连续的block组成的,oracle在给对象分配空间的时候,最少分配一个extent;extent由一个或多个block连续组成,这样连续是逻辑,在当下存储充分使用条带化条件下,不保证block物理也是连续的。
比extent更大的单位是segment,也就是我们常说的段,一组结构相同的extent就组成了一个segment,segment是存储在某个表空间的,表空间是个逻辑概念,一个表空间一般包括一个或着多个数据文件,也可以不包含数据文件,但这样的表空间是不同使用的。其实segment是存储在数据文件里,但是这种存储是按照表空间来组织的,一个段可能存储在一个数据文件中,也可能存储在多个数据文件中,不过这些数据文件必须属于同一个表空间。下面的图是一个很好的逻辑示意图:

表在Oracle数据库中就是存储在"Segment"里的。一张普通的表就对应一个SEGMENT,不过还有一些特例:
l 一张索引组织表可能包含了多个段,比如OVERFLOW段
l 一张表中,如果有LOB字段,那么LOB字段可能存储在独立的段中,那么这张表也可能包含多个段
l 一张分区表可能存储在N个独立的段中,这些段甚至可能存储在不同的表空间中
l 在一个CLUSTER(簇)中,可能存储多张表,而不是一张表。因此存储于簇中的表,表和SEGMENT不是一一对应的
通过上面的介绍大家知道了表的数据实际上是作为“段”的形式存储在表空间里的。当创建一个表的时候,Oracle自动会为这张表创建段,并分配第一个扩展(EXTENT)。我们已经知道了每个EXTENT是由多个连续的BLOCK组成的,数据就存储在这些BLOCK中,当这些BLOCK都使用完了,那么当下一次需要插入数据的时候,Oracle会自动为这张表扩展一个EXTENT。所以随着数据量的增长,这张表在不断的扩展。某张表的扩展的数量受到表空间容量和表的MAXEXTENTS参数的限制。对于早期版本的数据库,MAXEXTENTS的缺省值是255,这种情况下,某些较大的表就很容易达到了MAXEXTENTS的极限,这个时侯再插入数据,我们可能就会看到ORA-01631: Max # Extents (%s) Reached in TABLE %s.%s错误信息。这个时候就必须去加大MAXEXTENTS参数了。
了解了表和SEGMENT,下面我们来看看表的内部,我们知道表中的数据是存储在BLOCK里的,那么BLOCK的结构是什么样的呢?

实际上在一个BLOCK里,头部是BLOCK的HEADER,存储了一些数据块的信息、SCN、事务槽等信息。尾部的4个字节是块尾,块尾的目的是和块头的数据进行校验,确保这个数据块是一致的。块头和块尾中间的部分就是存储数据的。表中的数据是从数据块的底部开始存储的。比如我们在某个BLOCK中存储了3条记录,那么第一条记录的尾部正好和块尾相接,存储在BLOCK的最后,第三条记录存储在靠近块头的地方,前面就是这个块的空闲空间。随着数据块中数据的增长,数据区域逐渐接近块头的位置,也就是块中空闲的部分越来越少。如果这个块的空闲空间不足以插入一条新纪录了,那么就会寻找别的可以插入数据的块,如果所有的数据块都已经满了,那么就会扩展一个新的EXTENT。
现在我们的表中都设计了大量的VARCHAR字段,VARCHAR字段使用起来十分灵活,而且不会浪费空间,所以很好用。不过VARCHAR字段的使用也给BLOCK中的数据重组带来了麻烦。比如说我们在一张包含VARCHAR字段的表中插入一条数据的时候,如果某个字段首先我们插入了1个字节,而后来我们通过UPDATE将这个字段的值修改为200个字节,那么这条记录就需要重组,从而导致整个BLOCK进行重组。而如果这个时候我们修改的这条记录所在的BLOCK已经没有200个空闲的字节了,那么这条记录修改后就无法存储在这个BLOCK里了,Oracle在处理这种情况的时候,会把这条记录整个迁移到另外一个存在足够空闲空间的数据块中,而在原来记录的地方登记一个指向新位置的指针,这种情况就是我常说的行链。行链的产生,会加大系统的开销,影响对数据访问的性能。
表的分类及特点
我们大多系统只适用oracle的两种数据结构:分别是堆表和B*树索引,如果系统没有使用IOT或群,表示对数据优化访问没有进行充分的考虑。
1. 堆组织表(heap-organized table)
这是一种标准的数据库表,这种表的管理方式类似堆的管理,在增加数据时,在使用段中找到适合数据的可用空间;在删除数据时,在使空间可供后续更新和插入使用,堆是一连串的空间,这些空间以某种随机的方式使用。
2. B*树索引集群表(B* Tree index clustered table)
这种类型的集群表的主要完成两件事,一件是许多表可以物理的存储在一起。一般来说,来自同一个表的数据可以期望在一个数据块找到,利用集群表,可以让来自不同的表里数据一起存储在相同的数据块里。第二件是包含相同群键值的所有数据将物理的存储在一起,这些数据围绕群键值集群。群键利用B*树索引构造
所有表共享一个群键索引这一事实表示减少了索引的需要(散列群完全消除了对索引的需求,因为数据就是索引)。因为把数据存储在一起和共享群键索引可以有效的减少物理io,甚至减少逻辑io。从另一个角度说,也提高所需块的有效性(eg:本来需要10个块的提供,现在只需要2个块提供),这样也就自然提高了高速缓存的效率,可以使高速缓存缓存更多有效的块 群存在的连个基本限制:
l 不能进行群的直接路径装载
l 不能分区集群表
Oracle的数据库字典表主要是以群存放的(B*树群)
3. 散列集群表(hash-clusterd table)
这种类型的表类似B*树索引集群表,但不使用B*树索引按群键定位数据,散列群是使用散列算法把群键转化为数据块的地址,然后通过这个块地址查找数据,散列群跳过了除块读取外的所有io,这里的数据类似索引。散列表适合用在通过键的相等比较读取数据的时候。有两种类型的散列表,分别是单表和多表的散列群
4. 索引组织表(index-organized table(IOT))
这种表存储在索引结构中,他利用行的自身物理顺序。与堆不一样,堆中的数据是放在任何适合它的地方,而在IOT中,数据以根据主键来排序的次序存放。所以会影响插入的速度
5. 外部表(external table)
这种类型的表是oracle9i R1的新类型,它提供了将数据存储在oracle数据库的外部,不能修改这表的中数据,只能查询表中的数据,而且还不能像通常那样索引他们
集群表的共性是数据的集群存储,提供了数据预链接的作用,减少物理io的消耗。分为B*树索引集群表和散列集群表,这两个表的不同点是:
l B*树索引集群表用传统的B*树索引来存储一个键值和可找到数据的块地址,它非常像表上的索引,通过群键索引查找键值,找到数据所在的块地址,然后在其上查找数据。
l 散列表是用散列算法将键值转化为数据的块地址,从避免额外的io,直接读取数据块,数据自身就相当于索引。
集群表的优点:
l 物理集中放置数据
l 提高缓冲区高速缓存效率
l 加少物理io,甚至减少逻辑io
l 减少索引的需求,B*树索引集群表共享一个群键索引,而散列集群表的数据将相当于索引
群的缺点:
l 要仔细考虑设置合适的群尺寸,设置size值过大会浪费空间,设置过小不能体现群的主要好处(数据的集中存储),如果要更改size不合理的群,需要重建群。
l 必须控制和可控制对群的插入,否则会影响群的效果
l 集群表的插入要比堆表慢,因为数据必须进入适当的位置,而堆表可以在任何可以放入数据的地方添加数据,不需要将数据努力的保存在某个地方。这样并不是说集群表就不适合读写程序
索引组织表(IOT)
IOT用类似B*树的存储方法,在IOT中数据是按主键有序的存储在B*树索引结构中,而堆组织表是以一种无序的集合存储。与B*索引不同的是,在IOT的每个叶节点既有每行的主键值,又有那些非主键列值,即IOT是把数据和一个主键值物理的存储在一起。而普通表的索引只会对索引列索引,在索引结构中不包含非索引列的信息。
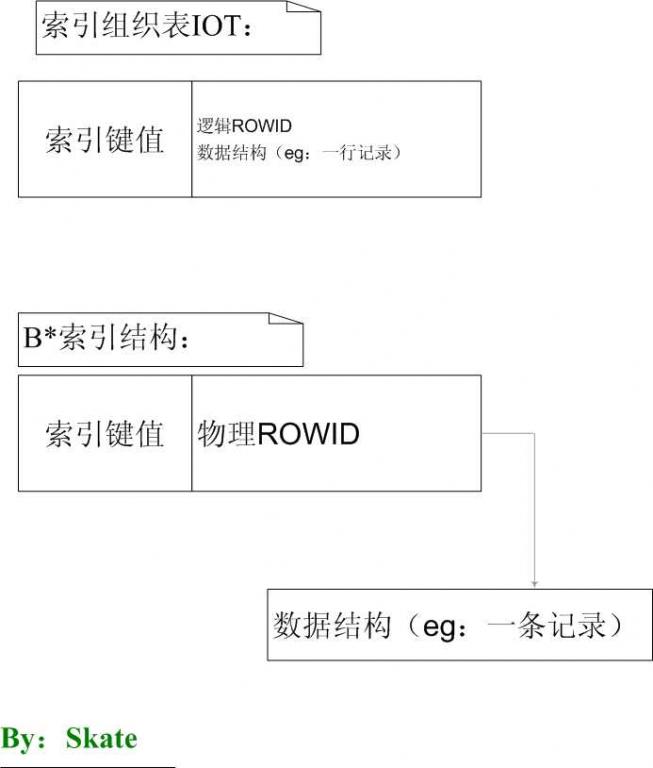
IOT与B*树群有如下不同点:
l 存在一个数据结构,一个索引结构。而B*树群有一个索引和数据项
l 存储是主键排序存储的,而B*树群是按键值存储,但并不按键值排序
l 设置IOT的尺寸要比设置集群表容易,不用像其群表那样估算键(size)的最大数目
l IOT除了具有集群表所有的优点,他还有一些特有的优点。索引是相当复杂的结构,它具有到处移动行的能力(集群表不能),允许更好的将相关的数据集中在一起存储。插入顺序是群要考虑的主要因素,IOT不需要考虑。
l IOT表可以在线联机重建或重组
IOT也存在一些缺点:
与群表一样,插入速度要比普通表慢,因为数据要装入特定的位置;它比较适合行比较小的表,行大了容易溢出段
IOT适用的环境:
1.表的全部列或大多数列为索引
2只会通过主键来访问一个表
3希望数据以特定的顺序物理存储
4希望某些数据物理地存储在同一处
5 经常在一个主键或唯一键上使用between查询,用IOT比较提高性能
Oracle的外部表一般用于数据装载和重装,把它单拿出来,哪天具体的学习下。
- 链表的概念
- 广义表的概念
- 表空间的概念
- 表分区的概念
- 表的概念
- 彩虹表的概念
- (三)表的概念
- 链表的概念
- 表的概念
- 概念架构的概念
- Oracle 临时表的概念
- 【数据库】“表提示” 的概念
- 线性表的一些概念
- oracle表空间的概念
- MySql表空间的概念
- 数据库表的相关概念
- MySql表空间的概念
- MySql表空间的概念
- Sprite Kit编程指南(2)-使用精灵
- RCP 视图间通信:SWT Canvas向JFace ViewPart发送消息
- Android平台Native开发与JNI机制详解
- tomcat下集成quartz任务调度
- ORACLE的锁机制
- 表的概念
- uva 348
- web中常有的几个pageContext,request,session,application,response等对象
- WinForm中MenuStrip控件
- (Android实战)ProgressBar+AsyncTask实现界面数据异步加载(含效果图)
- ios 全景浏览效果demo
- 【discuz3.x】discuz3.x后台【管理中心】->【全局】设置中表单名汇总
- android AsyncTask介绍
- Eclipse Hadoop插件使用


