机器学习_hadoop探究_文件系统
来源:互联网 发布:服装斜纹捆条计算法 编辑:程序博客网 时间:2024/05/23 11:38
研究hadoop的文章有很多,我想自己写一下,主要是理解学习hadoop,方便自己进行优化管理
主要参考是hadoop官方:http://hadoop.apache.org/docs/current/
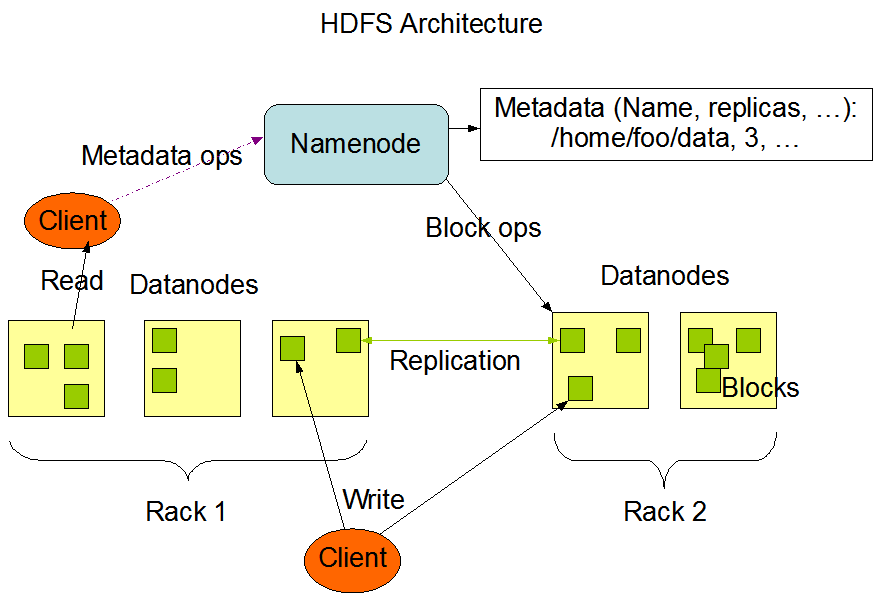
慢慢来吧,先copy一张hadoop官方的hdfs架构图
hdfs 全称 Hadoop Distributed File System
Metadata ops(Orbeon PresentationServer) 元数据描述服务
Block ops 块描述服务
Rack 机架
Replication 块复制
Namenode Datanode我就不解释了
大家学习hadoop流程应该和我差不多,先是单机伪分布,然后有条件的话,搭个多机分布,带机架的好像很少
这张图里面有两个机架左右都有7个datanode,client写的时候是对两个机架同时写,机架之间是相互备份的,可以判断机架之间就类似双机备份的那种
namenode 对datanode进行管理
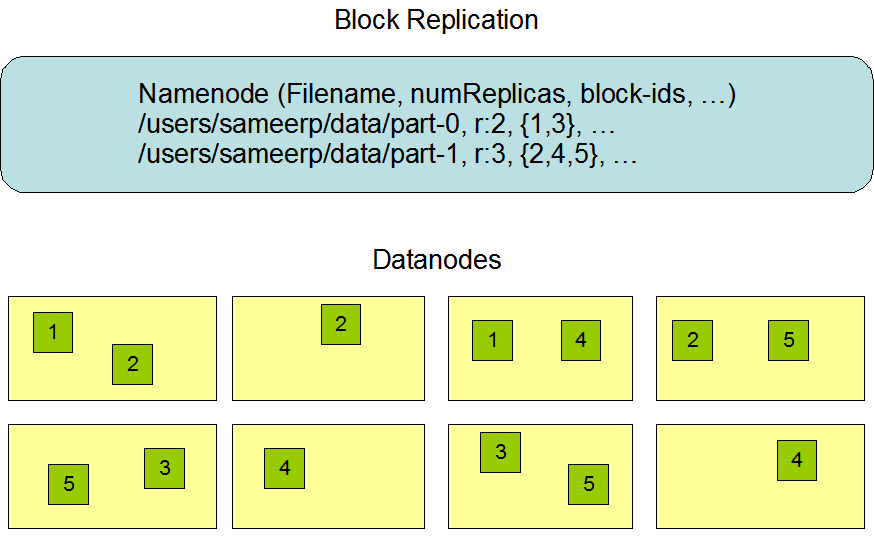
看一下第二张图,画的是datanode命名规则,这个我有体会,
我有三台datanode,后来有两台不用了,直接单机伪分布,然后进入到了safe mode :((hadoop fsck / 命令看)
有currupt块,提示的就是 /user/blacklaw/input/part-0, ......
网上介绍用 hadoop fsck / -move hadoop fsck / -delete把currupt的块删掉,感觉都不好使,反正只是实验,我直接hadoop namenode -format了
现在做个小实验,帮助大家理解
echo "aaaaa" > a.txt
hadoop fs -put a.txt input
hadoop fs -ls input
ls的时候完全正常,
然后跑到你设置的dfs文件夹,把dfs/data改成 data。bak
echo "bbbb" > b.txt
hadoop fs -put b.txt input
hadoop fs -ls input 直接给你报错了,说你有个datanode挂了,
可能还不直观,你用eclipse跑一下wordcount,直接告诉你Could not obtain block blk_-6775194498480386094_1278 from any node
而这个block就在改掉的data文件夹下面,现在datanode完全挂掉了
但是我的hadoop fs其实还可以用,不信可以试一下
hadoop fs -mkdir tmpdir 建目录
hadoop fs -ls tmpdir 列举
hadoop fs -touchz tmpdir/tmpfile 新建一个文件
hadoop fs -rmr tmpdir 删除目录
都可以用,大家一定很奇怪,datanode不是挂了吗,这么还是可以用咧,这里要讲一下hadoop的优化策略,在尽可能少的情况下读写datanode
实际上这些操作通过namenode都可以完成,并没有对datanode读写,touchz其实也只是在namenode上建了一个记录,也没有对datanode读写
如果用hadoop fs -put tmpfile tmpdir ,就会报错了
再做一个实验,把dfs/name/fsimage 改成 fsimage.bak
hdoop fs -ls 一下,没有问题
stop-all 一下,
再start-all jps看一下没有了namenode这项任务
cat fsimage ,可以看到目录结构,namenode储存的目录结构就在fsimage映像文件里,一般都是在内存里操作,需要的时候才对fsimage进行交换
可见hadoop优化的还是比较多的
- 机器学习_hadoop探究_文件系统
- 机器学习_hadoop探究_wordcount
- 机器学习_hadoop搭建
- 机器学习_hadoop + python
- Hadoop学习8_hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
- 学习_机器学习
- 机器学习_导航
- 机器学习_周志华
- 机器学习_协方差
- 机器学习_决策树
- 机器学习_谱聚类
- 【机器学习】K-MEANS算法探究
- Hadoop学习9_hadoop常用命令
- Python学习笔记_文件系统
- 机器学习_集成学习
- 机器学习_算法_朴素贝叶斯
- 机器学习_算法_神经网络_BP
- 机器学习_相关概念
- 用户体验网址收集
- ubuntu和mac OS X下另一种使用QQ的方法
- poj2033Alphacode(dp)
- uva 208
- 《灵飞经5·龙生九子》第二十三章 力压须眉(上)
- 机器学习_hadoop探究_文件系统
- HDU 2099 整除的尾数(模运算)
- 《灵飞经5·龙生九子》第二十三章 力压须眉(下)
- 对象变量或with块变量未设置
- STL源码 萃取技术分析
- Word中将批注换成自己的名字
- 多次注册事件会导致一个事件被触发多次
- 求两个字符串的最长公共子串,最长公共子序列,编辑距离
- [二叉树专题]:广度优先:按层次遍历二叉树的非递归实现||使用队列实现层次遍历二叉树


