使用wireshark分析网络流量实例
来源:互联网 发布:清除数据后照片还在吗 编辑:程序博客网 时间:2024/05/29 07:44
(1)简述访问web页面的过程。
(2)找出DNS解析请求、应答相关分组,传输层使用了何种协议,端口号是多少?所请求域名的IP地址是什么?
(3)统计访问该页面共有多少请求IP分组,多少响应IP分组?(提示:用脚本编程实现)
(4)找到TCP连接建立的三次握手过程,并结合数据,绘出TCP连接建立的完整过程,注明每个TCP报文段的序号、确认号、以及SYN\ACK的设置。
(5)针对(4))中的TCP连接,该TCP连接的四元组是什么?双方协商的起始序号是什么?TCP连接建立的过程中,第三次握手是否带有数据?是否消耗了一个序号?
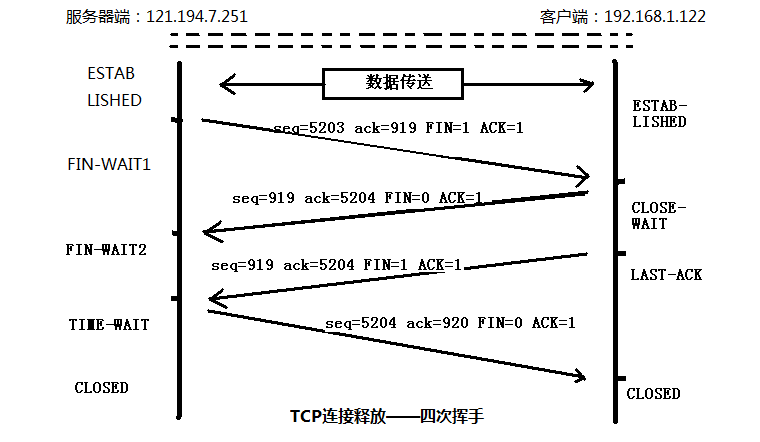
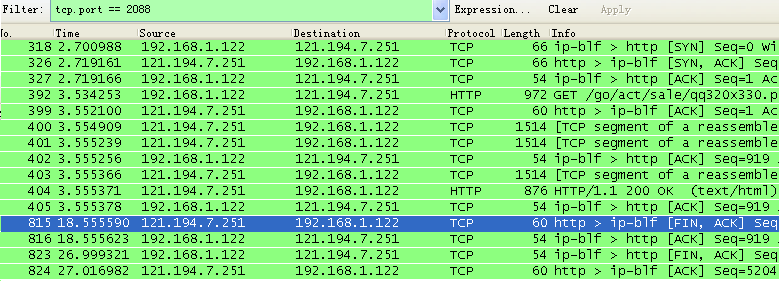
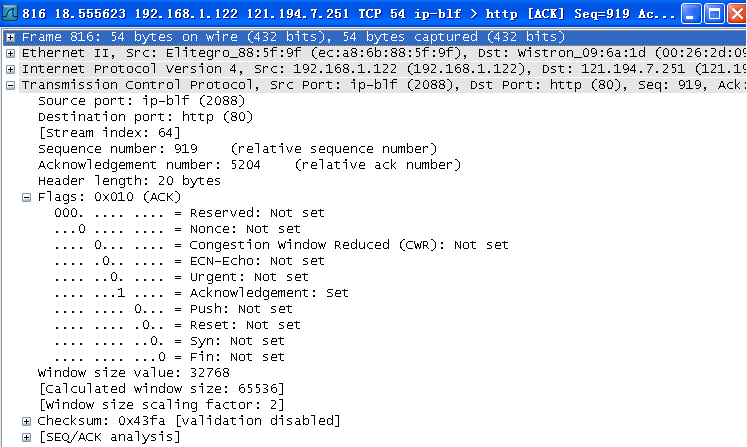
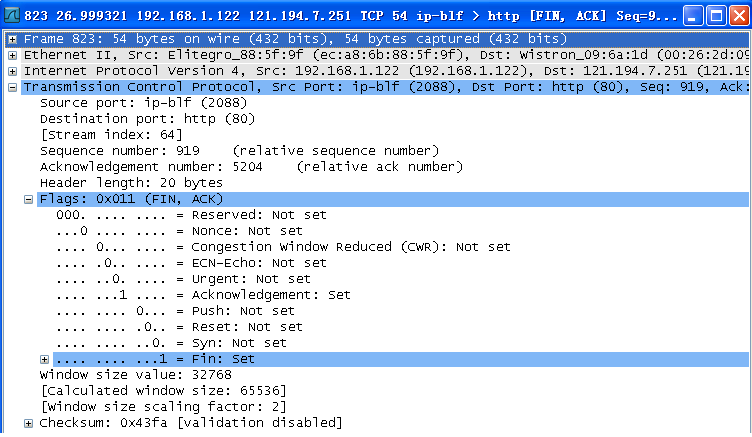
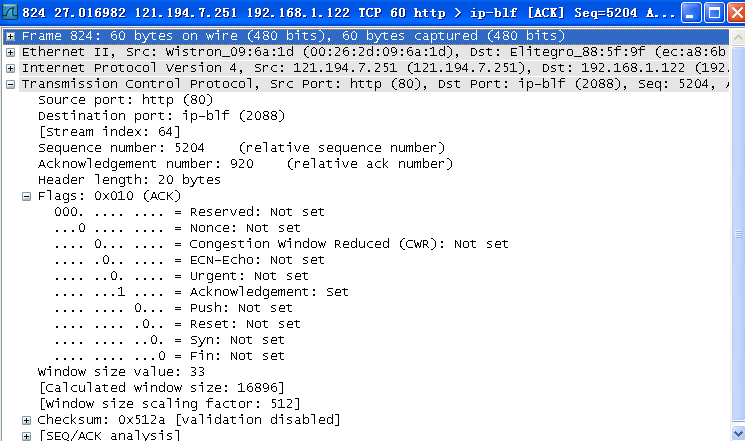
(6)找到TCP连接的释放过程,绘出TCP连接释放的完整过程,注明每个TCP报文段的序号、确认号、以及FIN\ACK的设置。
(7)针对(6)中的TCP连接释放,请问释放请求由服务器还是客户发起?FIN报文段是否携带数据,是否消耗一个序号?FIN报文段的序号是什么?为什么是这个值?
(8)在该TCP连接的数据传输过程中,找出每一个ACK报文段与相应数据报文段的对应关系,计算这些数据报文段的往返时延RTT(即RTT样本值)。根据课本200页5.6.2节内容,给每一个数据报文段估算超时时间RTO。(提示:用脚本编程实现)
(9)分别找出一个HTTP请求和响应分组,分析其报文格式。参照课本243页图6-12,在截图中标明各个字段。
Wireshark是网络包分析工具。网络包分析工具的主要作用是尝试捕获网络包,并尝试显示包的尽可能详细的情况。
你可以把网络包分析工具当成是一种用来测量有什么东西从网线上进出的测量工具,就好像使电工用来测量进入电信的电量的电度表一样。(当然比那个更高级)过去的此类工具要么是过于昂贵,要么是属于某人私有,或者是二者兼顾。Wireshark出现以后,这种现状得以改变。
Wireshark可能算得上是今天能使用的最好的开源网络分析软件。
主要应用
下面是Wireshark一些应用的举例:
• 网络管理员用来解决网络问题
• 网络安全工程师用来检测安全隐患
• 开发人员用来测试协议执行情况
• 用来学习网络协议
除了上面提到的,Wireshark还可以用在其它许多场合。

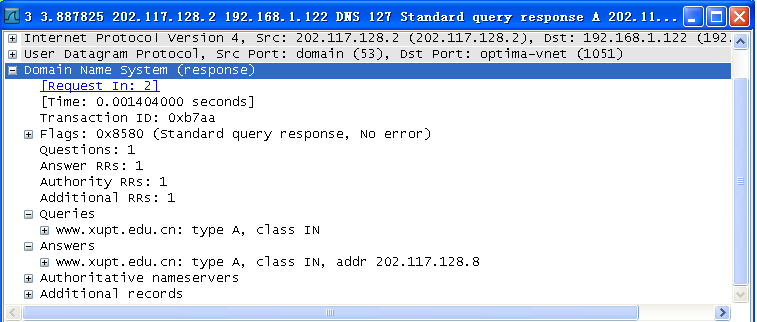
a)浏览器向DNS请求解析www.xupt.edu.cn的IP地址
b)域名系统DNS解析出邮电大学的IP地址202.117.128.8
c)浏览器与服务器建立TCP连接
d)浏览器发出取文件命令
e)服务器端给出响应,把首页文件发送给浏览器
f)释放TCP连接
g)浏览器显示西安邮电大学首页中的所有文本
(2)wireshark中DNS分组默认使用浅蓝色




- #!/usr/bin/perl
- $i=0;
- while(<>){
- if(/Frame/){
- $i++;
- }
- }
- print "The number of IP request packets is:",$i,"\n";


第一次握手:序号:seq=0;无确认号;ACK=0(not set);SYN=1



使用显示过滤规则选择一个客户端端口(打开一个网页其实会建立许多TCP连接,选择一个端口也是选择一个特定的TCP连接):tcp.port == 2088 得到下面这些报文


新的RTTD = (1-b)*(旧的RTTD) + b*|RTTs – 新的RTT样本|
超时重传时间RTO = RTTs + 4 * RTTD;

- #!/usr/bin/perl
- $i=0;
- @RTT;
- while(<>){
- if(/RTT/){
- @words = split(/ +/,$_);
- $RTT[$i++]=$words[8];
- }
- }
- $i=0;
- $RTTs=0;
- $a=0.125;
- $b=0.25;
- while($RTT[$i]){
- $RTTs *= (1-$a);
- $RTTs += $a*$RTT[$i];
- if($i==0){
- $RTTd=$RTT[$i]/2;
- }else{
- $RTTd *= (1-$b);
- $RTTd += $b * abs($RTTs-$RTT[$i]);
- }
- $RTO = $RTTs + 4*$RTTd;
- print "RTTs=",$RTTs,"\t";
- print "RTTd=",$RTTd,"\t";
- print "RTO=",$RTO,"\n";
- $i++;
- }

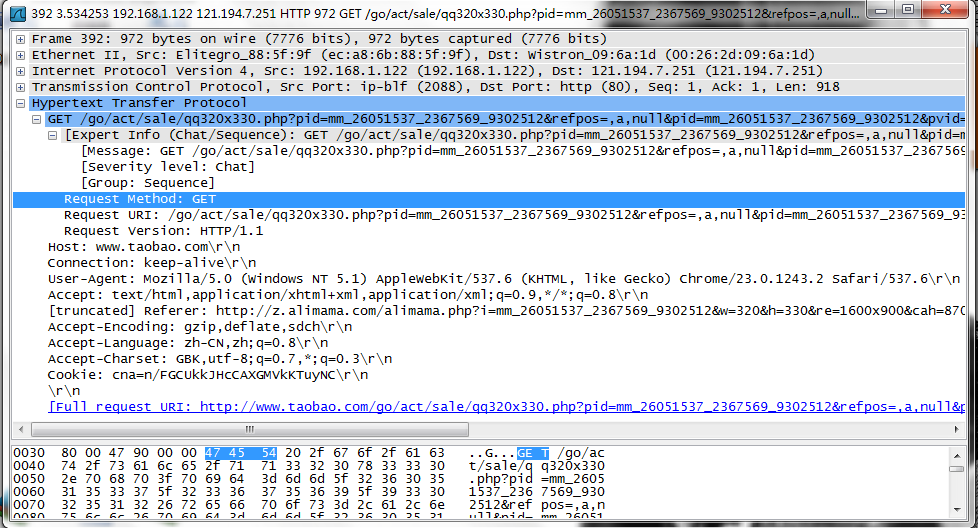
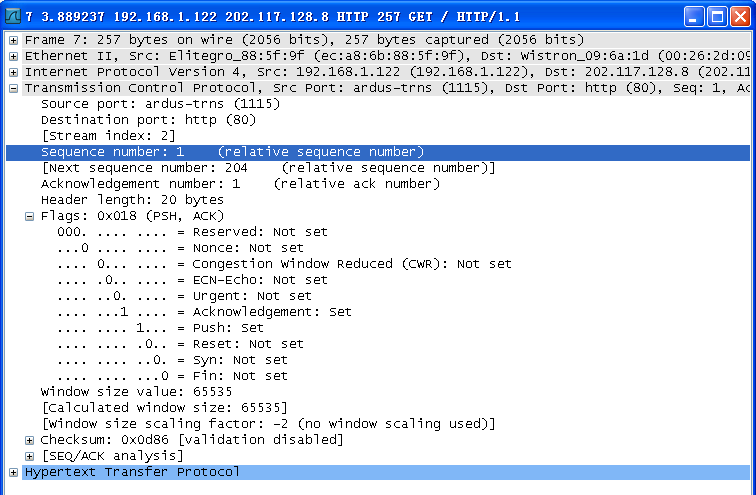
Request Method:GET(请求的方法)
Request URL:/go/act/sale/qq320x330.php?pid=mm_26051537……(URL)
Request Version:HTTP/1.1(http版本)
User-Agent:Mozilla/5.0(windows NT 5.1) AppleWebkit/537.6(KHTML,like Gecko) chrome/23.0.1243.2 Safari/537.6(用户代理使用的基于Mozilla内核的浏览器)

- 使用wireshark分析网络流量实例
- 网络流量分析/网络流量监测
- 图解Wireshark协议分析实例
- wireshark 使用及分析
- TCP/IP 实践之Ubuntu 16.04下安装网络流量分析工具 Wireshark
- [编程实例]linux下的以太网简单网络流量分析
- 使用wireshark分析网络报文
- 使用WireShark分析DICOM数据包
- 使用wireshark分析网络协议
- 使用wireshark进行安卓抓包分析
- 使用wireshark抓包分析
- 使用WireShark分析网站密码
- 使用wireshark进行安卓抓包分析
- Wireshark 分析 UDP 数据帧实例
- 【协议分析】Wireshark 过滤表达式实例
- Wireshark抓包实例分析HTTP问题
- VC++如何使用Mschart 实例-------网络流量监控程序
- VC++如何使用Mschart 实例-------网络流量监控程序
- 【Android 开发教程】发送Email
- 定时器、队列的逻辑。
- MFC定时器的应用
- 兼容所有主流浏览器的图片上传本地预览(IE\FIREFOX\CHROME)
- 访问者模式讨论篇:java的动态绑定与双分派
- 使用wireshark分析网络流量实例
- 详解java类的生命周期
- innosetup 64bit 和32 bit
- TCP网络关闭的状态变换时序图
- NSXMLParser和GDataXMLNode两种解析方式
- 自助Linux之问题诊断工具strace
- 纯手工打造漂亮的垂直时间轴,使用最简单的HTML+CSS+JQUERY完成100个版本更新记录的华丽转身!
- SOSO街景地图 API (Javascript)开发教程(1)- 街景
- iozone iostat atop


