WEBUS2.0 In Action - 解析索引文件结构(2)
来源:互联网 发布:淘宝代销怎么刷销量 编辑:程序博客网 时间:2024/04/30 05:58
上一篇:WEBUS2.0 In Action - 解析索引文件结构(1) |下一篇:WEBUS2.0 In Action - 索引操作指南(1)
通过前一篇文章,我们知道了WEBUS的索引数据都在一个虚拟的目录(IDirectory)中得以保存。本篇将继续前文,详细解析索引中的数据类型。
为了同时实现关键词搜索和范围搜索,WEBUS的索引采取了“主索引(Master Index)+序列(Sequence)”的方式进行组织:
图中0.idx、1.idx、2.idx是主索引,0.seq、1.seq是序列
主索引是一种倒排索引结构(Reversed Index);序列是根据字段值(Field.Value)排序之后的列表。
倒排索引是索引技术中最常见的名词之一,其原理就是通过预处理将原文根据关键词分门别类编排,当搜索时只要确定关键词就能够立即获取所有相关原文。如: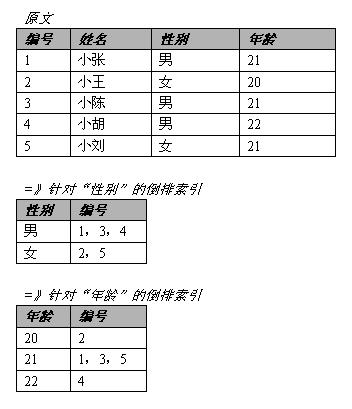
从上图我们可以看出,其实倒排索引简单来说就是一个速查字典,我们根据关键词能够一次性将所有的相关原文都找到,无须对原始数据进行扫描。进一步,如果用Hash表来实现倒排索引,将可以得到最高查询效率,其时间复杂度接近O(1)。不过普通Hash表受限于内存大小,不能保存太多项。因此WEBUS采用了一种叫做Big Hash Storage(BHS)的独特散列文件结构来解决容量限制的问题。
(BHS就是为大容量存储设计的一种Hash表结构。它的所有数据都会直接保存到磁盘中,因此突破了内存的限制,成为一种适合于搜索引擎索引构建的技术。关于其详细信息有机会专题讨论,本篇关注与WEBUS索引组成,所以不再深入探讨这个话题。)
序列是排序后的列表。当一个Document被添加到索引中时,WEBUS会分析这个Document的所有Field,如果某个Field需要排序(FieldAttributes.Sort),当前Document就会被插入到对应的序列中。由于序列在任何时刻都是有序的,因此我们使用BinarySearch来对其进行快速查找。
增量索引
当我们对大量Document编制索引时(比如上百万),可能要花费很长的时间。而这段时间内我们又需要访问索引进行搜索。因此就必须用增量方式来编制索引,这样的话,应用程序就能够编多少,访问多少,从而大大提高了程序的可用性。WEBUS也支持增量索引,它是通过分段-合并的方式来实现的: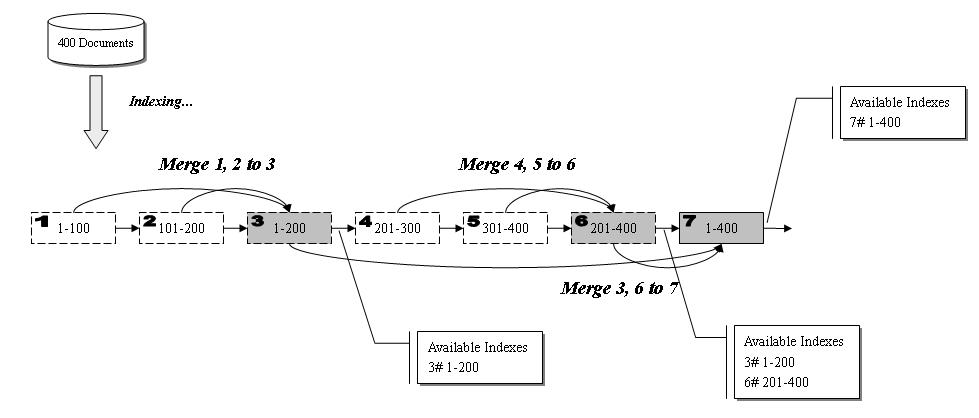
假设我们要对400个Document编制索引,将WEBUS参数设置为每100个文档编成一个索引,每两个索引合并一次。那么首先会生成1#索引,其中包含编号从1到100的Document;接着是2#索引,包含编号从101到200的Document;然后将1#、2#索引合并成3#索引,合并完成之后,1#、2#索引将被删除,3#索引中包含编号从1到200的Document。此时会将3#索引插入到可用索引列表中。继续下去,我们不久就能够得到6#索引,包含编号从201到400的Document。此时可用索引列表中会有两个索引(3#和6#)。这个时候虽然所有Document都编制到索引中去了,但是WEBUS还要继续将3#和6#这两个相同容量的索引合并成一个更大的7#索引,合并完成后同样会删除3#和6#索引,留下7#索引,它包含了编号从1到400全部的Document。此时可用索引列表也会被更新,其中将只有7#索引这一项。
相关信息及WEBUS2.0 SDK下载:继续我的代码,分享我的快乐 - WEBUS2.0
- WEBUS2.0 In Action - 解析索引文件结构(2)
- WEBUS2.0 In Action - 解析索引文件结构(2)
- WEBUS2.0 In Action - 解析索引文件结构(1)
- WEBUS2.0 In Action - 解析索引文件结构(1)
- WEBUS2.0 In Action - 索引操作指南(2)
- WEBUS2.0 In Action - 索引操作指南(1)
- WEBUS2.0 In Action - 创建索引
- WEBUS2.0 In Action - 创建索引
- WEBUS2.0 In Action
- WEBUS2.0 In Action - 搜索操作指南 - (2)
- WEBUS2.0 In Action - [源代码] - C#代码搜索器
- WEBUS2.0 In Action - 开始搜索 [代码示例]
- WEBUS2.0 In Action - 开始搜索 [代码示例]
- WEBUS2.0 In Action - [源代码] - C#代码搜索器
- WEBUS2.0 In Action - 搜索操作指南 - (1)
- WEBUS2.0 In Action - 搜索操作指南 - (3)
- WEBUS2.0 In Action - 搜索操作指南 - (4)
- 4. 解析索引文件结构(2)
- java面试题之银行业务调度系统
- strncmp、strncpy、strncat、strlen库函数的实现
- WEBUS2.0 In Action - 创建索引
- WEBUS2.0 In Action - 开始搜索 [代码示例]
- WEBUS2.0 In Action - 解析索引文件结构(1)
- WEBUS2.0 In Action - 解析索引文件结构(2)
- 我的嵌入式学习之路——笔记计划
- Database system concept笔记(3)
- vs2012编译的程序在XP下运行提示无法定位输入点XXXXX到kernel32.dll
- Database system concept笔记(4)
- 找工作之面试题练习2
- base.css
- 百度——LBS.云 v2.0——云存储扩展字段——Android
- PostgreSQL字符串处理函数


