内存_页的使用
来源:互联网 发布:php array shift函数 编辑:程序博客网 时间:2024/05/01 23:41
转载自:http://blog.csdn.net/vanbreaker/article/details/7624628
Linux内核内存管理的一项重要工作就是如何在频繁申请释放内存的情况下,避免碎片的产生。Linux采用伙伴系统解决外部碎片的问题,采用slab解决内部碎片的问题,在这里我们先讨论外部碎片问题。避免外部碎片的方法有两种:一种是之前介绍过的利用非连续内存的分配;另外一种则是用一种有效的方法来监视内存,保证在内核只要申请一小块内存的情况下,不会从大块的连续空闲内存中截取一段过来,从而保证了大块内存的连续性和完整性。显然,前者不能成为解决问题的普遍方法,一来用来映射非连续内存线性地址空间有限,二来每次映射都要改写内核的页表,进而就要刷新TLB,这使得分配的速度大打折扣,这对于要频繁申请内存的内核显然是无法忍受的。因此Linux采用后者来解决外部碎片的问题,也就是著名的伙伴系统。
什么是伙伴系统?
伙伴系统的宗旨就是用最小的内存块来满足内核的对于内存的请求。在最初,只有一个块,也就是整个内存,假如为1M大小,而允许的最小块为64K,那么当我们申请一块200K大小的内存时,就要先将1M的块分裂成两等分,各为512K,这两分之间的关系就称为伙伴,然后再将第一个512K的内存块分裂成两等分,各位256K,将第一个256K的内存块分配给内存,这样就是一个分配的过程。下面我们结合示意图来了解伙伴系统分配和回收内存块的过程。
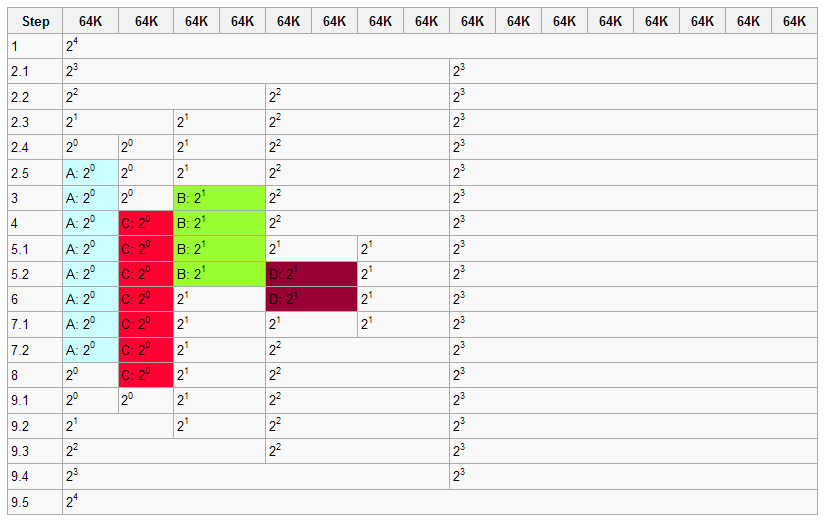
1 初始化时,系统拥有1M的连续内存,允许的最小的内存块为64K,图中白色的部分为空闲的内存块,着色的代表分配出去了得内存块。
2 程序A申请一块大小为34K的内存,对应的order为0,即2^0=1个最小内存块
2.1 系统中不存在order 0(64K)的内存块,因此order 4(1M)的内存块分裂成两个order 3的内存块(512K)
2.2 仍然没有order 0的内存块,因此order 3的内存块分裂成两个order 2的内存块(256K)
2.3 仍然没有order 0的内存块,因此order 2的内存块分裂成两个order 1的内存块(128K)
2.4 仍然没有order 0的内存块,因此order 1的内存块分裂成两个order 0的内存块(64K)
2.5 找到了order 0的内存块,将其中的一个分配给程序A,现在伙伴系统的内存为一个order 0的内存块,一个order
1的内存块,一个order 2的内存块以及一个order 3的内存块
3 程序B申请一块大小为66K的内存,对应的order为1,即2^1=2个最小内存块,由于系统中正好存在一个order 1的内
存块,所以直接用来分配
4 程序C申请一块大小为35K的内存,对应的order为0,同样由于系统中正好存在一个order 0的内存块,直接用来分
配
5 程序D申请一块大小为67K的内存,对应的order为1
5.1 系统中不存在order 1的内存块,于是将order 2的内存块分裂成两块order 1的内存块
5.2 找到order 1的内存块,进行分配
6 程序B释放了它申请的内存,即一个order 1的内存块
7 程序D释放了它申请的内存
7.1 一个order 1的内存块回收到内存当中
7.2由于该内存块的伙伴也是空闲的,因此两个order 1的内存块合并成一个order 2的内存块
8 程序A释放了它申请的内存,即一个order 0的内存块
9 程序C释放了它申请的内存
9.1 一个order 0的内存块被释放
9.2 两个order 0伙伴块都是空闲的,进行合并,生成一个order 1的内存块m
9.3 两个order 1伙伴块都是空闲的,进行合并,生成一个order 2的内存块
9.4 两个order 2伙伴块都是空闲的,进行合并,生成一个order 3的内存块
9.5 两个order 3伙伴块都是空闲的,进行合并,生成一个order 4的内存块
相关的数据结构
在前面的文章中已经简单的介绍过struct zone这个结构,对于每个管理区都有自己的struct zone,而struct zone中的struct free_area则是用来描述该管理区伙伴系统的空闲内存块的
<mmzone.h>
- struct zone {
- ...
- ...
- struct free_area free_area[MAX_ORDER];
- ...
- ...
- }
struct zone {... ...struct free_areafree_area[MAX_ORDER];......}
<mmzone.h>
- struct free_area {
- struct list_head free_list[MIGRATE_TYPES];
- unsigned long nr_free;
- };
struct free_area {struct list_headfree_list[MIGRATE_TYPES];unsigned longnr_free;};
free_area共有MAX_ORDER个元素,其中第order个元素记录了2^order的空闲块,这些空闲块在free_list中以双向链表的形式组织起来,对于同等大小的空闲块,其类型不同,将组织在不同的free_list中,nr_free记录了该free_area中总共的空闲内存块的数量。MAX_ORDER的默认值为11,这意味着最大内存块的大小为2^10=1024个页框。对于同等大小的内存块,每个内存块的起始页框用于链表的节点进行相连,这些节点对应的着struct page中的lru域
- struct page {
- ...
- ...
- struct list_head lru; /* Pageout list, eg. active_list
- * protected by zone->lru_lock !
- */
- ...
- }
struct page {......struct list_head lru;/* Pageout list, eg. active_list * protected by zone->lru_lock ! */...}
连接示意图如下:
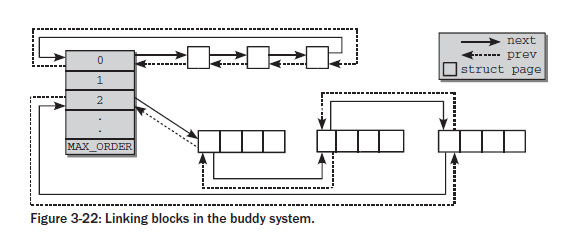
在2.6.24之前的内核版本中,free_area结构中只有一个free_list数组,而从2.6.24开始,free_area结构中存有MIGRATE_TYPES个free_list,这些数组是根据页框的移动性来划分的,为什么要进行这样的划分呢?实际上也是为了减少碎片而提出的,我们考虑下面的情况:

图中一共有32个页,只分配出了4个页框,但是能够分配的最大连续内存也只有8个页框(因为伙伴系统分配出去的内存必须是2的整数次幂个页框),内核解决这种问题的办法就是将不同类型的页进行分组。分配出去的页面可分为三种类型:
- 不可移动页(Non-movable pages):这类页在内存当中有固定的位置,不能移动。内核的核心分配的内存大多属于这种类型
- 可回收页(Reclaimable pages):这类页不能直接移动,但可以删除,其内容页可以从其他地方重新生成,例如,映射自文件的数据属于这种类型,针对这种页,内核有专门的页面回收处理
- 可移动页:这类页可以随意移动,用户空间应用程序所用到的页属于该类别。它们通过页表来映射,如果他们复制到新的位置,页表项也会相应的更新,应用程序不会注意到任何改变。
假如上图中大部分页都是可移动页,而分配出去的四个页都是不可移动页,由于不可移动页插在了其他类型页的中间,就导致了无法从原本空闲的连续内存区中分配较大的内存块。考虑下图的情况:
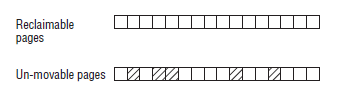
将可回收页和不可移动页分开,这样虽然在不可移动页的区域当中无法分配大块的连续内存,但是可回收页的区域却没有受其影响,可以分配大块的连续内存。
内核对于迁移类型的定义如下:
<mmzone.h>
- #define MIGRATE_UNMOVABLE 0
- #define MIGRATE_RECLAIMABLE 1
- #define MIGRATE_MOVABLE 2
- #define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */
- #define MIGRATE_RESERVE 3
- #define MIGRATE_ISOLATE 4 /* can't allocate from here */
- #define MIGRATE_TYPES 5
#define MIGRATE_UNMOVABLE 0#define MIGRATE_RECLAIMABLE 1#define MIGRATE_MOVABLE 2#define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */#define MIGRATE_RESERVE 3#define MIGRATE_ISOLATE 4 /* can't allocate from here */#define MIGRATE_TYPES 5
前三种类型已经介绍过
MIGRATE_PCPTYPES是per_cpu_pageset,即用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目
MIGRATE_RESERVE是在前三种的列表中都没用可满足分配的内存块时,就可以从MIGRATE_RESERVE分配
MIGRATE_ISOLATE用于跨越NUMA节点移动物理内存页,在大型系统上,它有益于将物理内存页移动到接近于是用该页最频繁地CPU
MIGRATE_TYPES表示迁移类型的数目
当一个指定的迁移类型所对应的链表中没有空闲块时,将会按以下定义的顺序到其他迁移类型的链表中寻找
- static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
- [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
- [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
- [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
- [MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */
- };
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */};伙伴系统的初始化主要是初始化之前介绍的伙伴系统涉及到的数据结构,并且把系统初始化时由bootmem allocator管理的低端内存以及系统的高端内存释放到伙伴系统中去。其中有些和zone相关的域在前面<<Linux节点和内存管理区的初始化>>中已经有所介绍。
在start_kernel()-->paging_init()-->zone_sizes_init()-->free_area_init_nodes()-->free_area_init_node()-->free_area_init_core()-->init_currently_empty_zone()-->zone_init_free_lists()中,free_area的相关域都被初始化
- static void __meminit zone_init_free_lists(struct zone *zone)
- {
- int order, t;
- for_each_migratetype_order(order, t) {
- /*链表初始化为空链表*/
- INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
- /*内存块数量初始化为0*/
- zone->free_area[order].nr_free = 0;
- }
- }
static void __meminit zone_init_free_lists(struct zone *zone){int order, t;for_each_migratetype_order(order, t) {/*链表初始化为空链表*/INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);/*内存块数量初始化为0*/zone->free_area[order].nr_free = 0;}}
for_each_migratetype_order(order, t)就是两个嵌套的for循环
- #define for_each_migratetype_order(order, type) \
- for (order = 0; order < MAX_ORDER; order++) \
- for (type = 0; type < MIGRATE_TYPES; type++)
#define for_each_migratetype_order(order, type) \for (order = 0; order < MAX_ORDER; order++) \for (type = 0; type < MIGRATE_TYPES; type++)
start_kernel()-->mm_init()-->mem_init(),负责统计所有可用的低端内存和高端内存,并释放到伙伴系统中
<Init_32.c>
- void __init mem_init(void)
- {
- int codesize, reservedpages, datasize, initsize;
- int tmp;
- pci_iommu_alloc();
- #ifdef CONFIG_FLATMEM
- BUG_ON(!mem_map);
- #endif
- /* this will put all low memory onto the freelists */
- /*销毁bootmem分配器,释放bootmem分配器管理的空闲页框和bootmem的位图所占用的页框,
- 并计入totalram_pages*/
- totalram_pages += free_all_bootmem();
- reservedpages = 0;
- for (tmp = 0; tmp < max_low_pfn; tmp++)
- /*
- * Only count reserved RAM pages:
- */
- if (page_is_ram(tmp) && PageReserved(pfn_to_page(tmp)))
- reservedpages++;
- /*处理高端内存页框*/
- set_highmem_pages_init();
- codesize = (unsigned long) &_etext - (unsigned long) &_text;
- datasize = (unsigned long) &_edata - (unsigned long) &_etext;
- initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;
- printk(KERN_INFO "Memory: %luk/%luk available (%dk kernel code, "
- "%dk reserved, %dk data, %dk init, %ldk highmem)\n",
- nr_free_pages() << (PAGE_SHIFT-10),
- num_physpages << (PAGE_SHIFT-10),
- codesize >> 10,
- reservedpages << (PAGE_SHIFT-10),
- datasize >> 10,
- initsize >> 10,
- (unsigned long) (totalhigh_pages << (PAGE_SHIFT-10))
- );
- printk(KERN_INFO "virtual kernel memory layout:\n"
- " fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
- #ifdef CONFIG_HIGHMEM
- " pkmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
- #endif
- " vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"
- " lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"
- " .init : 0x%08lx - 0x%08lx (%4ld kB)\n"
- " .data : 0x%08lx - 0x%08lx (%4ld kB)\n"
- " .text : 0x%08lx - 0x%08lx (%4ld kB)\n",
- FIXADDR_START, FIXADDR_TOP,
- (FIXADDR_TOP - FIXADDR_START) >> 10,
- #ifdef CONFIG_HIGHMEM
- PKMAP_BASE, PKMAP_BASE+LAST_PKMAP*PAGE_SIZE,
- (LAST_PKMAP*PAGE_SIZE) >> 10,
- #endif
- VMALLOC_START, VMALLOC_END,
- (VMALLOC_END - VMALLOC_START) >> 20,
- (unsigned long)__va(0), (unsigned long)high_memory,
- ((unsigned long)high_memory - (unsigned long)__va(0)) >> 20,
- (unsigned long)&__init_begin, (unsigned long)&__init_end,
- ((unsigned long)&__init_end -
- (unsigned long)&__init_begin) >> 10,
- (unsigned long)&_etext, (unsigned long)&_edata,
- ((unsigned long)&_edata - (unsigned long)&_etext) >> 10,
- (unsigned long)&_text, (unsigned long)&_etext,
- ((unsigned long)&_etext - (unsigned long)&_text) >> 10);
- /*
- * Check boundaries twice: Some fundamental inconsistencies can
- * be detected at build time already.
- */
- #define __FIXADDR_TOP (-PAGE_SIZE)
- #ifdef CONFIG_HIGHMEM
- BUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
- BUILD_BUG_ON(VMALLOC_END > PKMAP_BASE);
- #endif
- #define high_memory (-128UL << 20)
- BUILD_BUG_ON(VMALLOC_START >= VMALLOC_END);
- #undef high_memory
- #undef __FIXADDR_TOP
- #ifdef CONFIG_HIGHMEM
- BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE > FIXADDR_START);
- BUG_ON(VMALLOC_END > PKMAP_BASE);
- #endif
- BUG_ON(VMALLOC_START >= VMALLOC_END);
- BUG_ON((unsigned long)high_memory > VMALLOC_START);
- if (boot_cpu_data.wp_works_ok < 0)
- test_wp_bit();
- save_pg_dir();
- /*将前3GB线性地址(即用户地址空间)对应的pgd全局目录项清空*/
- zap_low_mappings(true);
- }
void __init mem_init(void){int codesize, reservedpages, datasize, initsize;int tmp;pci_iommu_alloc();#ifdef CONFIG_FLATMEMBUG_ON(!mem_map);#endif/* this will put all low memory onto the freelists */ /*销毁bootmem分配器,释放bootmem分配器管理的空闲页框和bootmem的位图所占用的页框, 并计入totalram_pages*/totalram_pages += free_all_bootmem();reservedpages = 0;for (tmp = 0; tmp < max_low_pfn; tmp++)/* * Only count reserved RAM pages: */if (page_is_ram(tmp) && PageReserved(pfn_to_page(tmp)))reservedpages++;/*处理高端内存页框*/set_highmem_pages_init();codesize = (unsigned long) &_etext - (unsigned long) &_text;datasize = (unsigned long) &_edata - (unsigned long) &_etext;initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;printk(KERN_INFO "Memory: %luk/%luk available (%dk kernel code, ""%dk reserved, %dk data, %dk init, %ldk highmem)\n",nr_free_pages() << (PAGE_SHIFT-10),num_physpages << (PAGE_SHIFT-10),codesize >> 10,reservedpages << (PAGE_SHIFT-10),datasize >> 10,initsize >> 10,(unsigned long) (totalhigh_pages << (PAGE_SHIFT-10)) );printk(KERN_INFO "virtual kernel memory layout:\n"" fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"#ifdef CONFIG_HIGHMEM" pkmap : 0x%08lx - 0x%08lx (%4ld kB)\n"#endif" vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"" lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"" .init : 0x%08lx - 0x%08lx (%4ld kB)\n"" .data : 0x%08lx - 0x%08lx (%4ld kB)\n"" .text : 0x%08lx - 0x%08lx (%4ld kB)\n",FIXADDR_START, FIXADDR_TOP,(FIXADDR_TOP - FIXADDR_START) >> 10,#ifdef CONFIG_HIGHMEMPKMAP_BASE, PKMAP_BASE+LAST_PKMAP*PAGE_SIZE,(LAST_PKMAP*PAGE_SIZE) >> 10,#endifVMALLOC_START, VMALLOC_END,(VMALLOC_END - VMALLOC_START) >> 20,(unsigned long)__va(0), (unsigned long)high_memory,((unsigned long)high_memory - (unsigned long)__va(0)) >> 20,(unsigned long)&__init_begin, (unsigned long)&__init_end,((unsigned long)&__init_end - (unsigned long)&__init_begin) >> 10,(unsigned long)&_etext, (unsigned long)&_edata,((unsigned long)&_edata - (unsigned long)&_etext) >> 10,(unsigned long)&_text, (unsigned long)&_etext,((unsigned long)&_etext - (unsigned long)&_text) >> 10);/* * Check boundaries twice: Some fundamental inconsistencies can * be detected at build time already. */#define __FIXADDR_TOP (-PAGE_SIZE)#ifdef CONFIG_HIGHMEMBUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE> FIXADDR_START);BUILD_BUG_ON(VMALLOC_END> PKMAP_BASE);#endif#define high_memory (-128UL << 20)BUILD_BUG_ON(VMALLOC_START>= VMALLOC_END);#undef high_memory#undef __FIXADDR_TOP#ifdef CONFIG_HIGHMEMBUG_ON(PKMAP_BASE + LAST_PKMAP*PAGE_SIZE> FIXADDR_START);BUG_ON(VMALLOC_END> PKMAP_BASE);#endifBUG_ON(VMALLOC_START>= VMALLOC_END);BUG_ON((unsigned long)high_memory> VMALLOC_START);if (boot_cpu_data.wp_works_ok < 0)test_wp_bit();save_pg_dir();/*将前3GB线性地址(即用户地址空间)对应的pgd全局目录项清空*/zap_low_mappings(true);}
free_all_bootmem()的核心函数在<<bootmem allocator>>中已有介绍,这里不再列出
<Highmem_32.c>
- void __init set_highmem_pages_init(void)
- {
- struct zone *zone;
- int nid;
- for_each_zone(zone) {/*遍历每个管理区*/
- unsigned long zone_start_pfn, zone_end_pfn;
- if (!is_highmem(zone))/*判断是否是高端内存管理区*/
- continue;
- /*记录高端内存管理区的起始页框号和结束页框号*/
- zone_start_pfn = zone->zone_start_pfn;
- zone_end_pfn = zone_start_pfn + zone->spanned_pages;
- nid = zone_to_nid(zone);
- printk(KERN_INFO "Initializing %s for node %d (%08lx:%08lx)\n",
- zone->name, nid, zone_start_pfn, zone_end_pfn);
- /*将高端内存的页框添加到伙伴系统*/
- add_highpages_with_active_regions(nid, zone_start_pfn,
- zone_end_pfn);
- }
- /*将释放到伙伴系统的高端内存页框数计入totalram_pages*/
- totalram_pages += totalhigh_pages;
- }
void __init set_highmem_pages_init(void){struct zone *zone;int nid;for_each_zone(zone) {/*遍历每个管理区*/unsigned long zone_start_pfn, zone_end_pfn;if (!is_highmem(zone))/*判断是否是高端内存管理区*/continue;/*记录高端内存管理区的起始页框号和结束页框号*/zone_start_pfn = zone->zone_start_pfn;zone_end_pfn = zone_start_pfn + zone->spanned_pages;nid = zone_to_nid(zone);printk(KERN_INFO "Initializing %s for node %d (%08lx:%08lx)\n",zone->name, nid, zone_start_pfn, zone_end_pfn);/*将高端内存的页框添加到伙伴系统*/add_highpages_with_active_regions(nid, zone_start_pfn, zone_end_pfn);}/*将释放到伙伴系统的高端内存页框数计入totalram_pages*/totalram_pages += totalhigh_pages;}
- void __init add_highpages_with_active_regions(int nid, unsigned long start_pfn,
- unsigned long end_pfn)
- {
- struct add_highpages_data data;
- data.start_pfn = start_pfn;
- data.end_pfn = end_pfn;
- /*遍历所有的活动区,调用add_highpages_word_fn()来处理每个活动区*/
- work_with_active_regions(nid, add_highpages_work_fn, &data);
- }
void __init add_highpages_with_active_regions(int nid, unsigned long start_pfn, unsigned long end_pfn){struct add_highpages_data data;data.start_pfn = start_pfn;data.end_pfn = end_pfn;/*遍历所有的活动区,调用add_highpages_word_fn()来处理每个活动区*/work_with_active_regions(nid, add_highpages_work_fn, &data);}
- <SPAN style="FONT-SIZE: 12px">void __init work_with_active_regions(int nid, work_fn_t work_fn, void *data)
- {
- int i;
- int ret;
- for_each_active_range_index_in_nid(i, nid) {
- ret = work_fn(early_node_map[i].start_pfn,
- early_node_map[i].end_pfn, data);
- if (ret)
- break;
- }
- }</SPAN>
<span style="font-size:12px">void __init work_with_active_regions(int nid, work_fn_t work_fn, void *data){int i;int ret;for_each_active_range_index_in_nid(i, nid) {ret = work_fn(early_node_map[i].start_pfn, early_node_map[i].end_pfn, data);if (ret)break;}}</span>
- <SPAN style="FONT-SIZE: 12px">static int __init add_highpages_work_fn(unsigned long start_pfn,
- unsigned long end_pfn, void *datax)
- {
- int node_pfn;
- struct page *page;
- unsigned long final_start_pfn, final_end_pfn;
- struct add_highpages_data *data;
- data = (struct add_highpages_data *)datax;
- /*得到合理的起始结束页框号*/
- final_start_pfn = max(start_pfn, data->start_pfn);
- final_end_pfn = min(end_pfn, data->end_pfn);
- if (final_start_pfn >= final_end_pfn)
- return 0;
- /*遍历活动区的页框*/
- for (node_pfn = final_start_pfn; node_pfn < final_end_pfn;
- node_pfn++) {
- if (!pfn_valid(node_pfn))
- continue;
- page = pfn_to_page(node_pfn);
- add_one_highpage_init(page, node_pfn);/*将该页框添加到伙伴系统*/
- }
- return 0;
- }
- </SPAN>
<span style="font-size:12px">static int __init add_highpages_work_fn(unsigned long start_pfn, unsigned long end_pfn, void *datax){int node_pfn;struct page *page;unsigned long final_start_pfn, final_end_pfn;struct add_highpages_data *data;data = (struct add_highpages_data *)datax;/*得到合理的起始结束页框号*/final_start_pfn = max(start_pfn, data->start_pfn);final_end_pfn = min(end_pfn, data->end_pfn);if (final_start_pfn >= final_end_pfn)return 0;/*遍历活动区的页框*/for (node_pfn = final_start_pfn; node_pfn < final_end_pfn; node_pfn++) {if (!pfn_valid(node_pfn))continue;page = pfn_to_page(node_pfn);add_one_highpage_init(page, node_pfn);/*将该页框添加到伙伴系统*/}return 0;}</span>
- <SPAN style="FONT-SIZE: 12px">static void __init add_one_highpage_init(struct page *page, int pfn)
- {
- ClearPageReserved(page);
- init_page_count(page);/*count初始化为1*/
- __free_page(page); /*释放page到伙伴系统*/
- totalhigh_pages++; /*高端内存的页数加1*/
- }</SPAN>
<span style="font-size:12px">static void __init add_one_highpage_init(struct page *page, int pfn){ClearPageReserved(page);init_page_count(page);/*count初始化为1*/__free_page(page); /*释放page到伙伴系统*/totalhigh_pages++; /*高端内存的页数加1*/}</span>
__free_page()中涉及到的具体操作在后面介绍伙伴系统释放页面时再做分析
在free_area_init_core()-->memmap_init()(-->memmap_init_zone() )-->set_pageblock_migratetype(),将每个pageblock的起始页框对应的struct zone当中的pageblock_flags代表的位图相关区域标记为可移动的,表示该pageblock为可移动的,也就是说内核初始化伙伴系统时,所有的页都被标记为可移动的
- <SPAN style="FONT-SIZE: 12px">void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
- unsigned long start_pfn, enum memmap_context context)
- {
- struct page *page;
- unsigned long end_pfn = start_pfn + size;
- unsigned long pfn;
- struct zone *z;
- if (highest_memmap_pfn < end_pfn - 1)
- highest_memmap_pfn = end_pfn - 1;
- z = &NODE_DATA(nid)->node_zones[zone];
- for (pfn = start_pfn; pfn < end_pfn; pfn++) {
- /*
- * There can be holes in boot-time mem_map[]s
- * handed to this function. They do not
- * exist on hotplugged memory.
- */
- if (context == MEMMAP_EARLY) {
- if (!early_pfn_valid(pfn))
- continue;
- if (!early_pfn_in_nid(pfn, nid))
- continue;
- }
- page = pfn_to_page(pfn);
- set_page_links(page, zone, nid, pfn);
- mminit_verify_page_links(page, zone, nid, pfn);
- init_page_count(page);
- reset_page_mapcount(page);
- SetPageReserved(page);
- /*
- * Mark the block movable so that blocks are reserved for
- * movable at startup. This will force kernel allocations
- * to reserve their blocks rather than leaking throughout
- * the address space during boot when many long-lived
- * kernel allocations are made. Later some blocks near
- * the start are marked MIGRATE_RESERVE by
- * setup_zone_migrate_reserve()
- *
- * bitmap is created for zone's valid pfn range. but memmap
- * can be created for invalid pages (for alignment)
- * check here not to call set_pageblock_migratetype() against
- * pfn out of zone.
- */
- /*如果pfn处在合理的范围,并且该pfn是一个pageblock的起始页框号*/
- if ((z->zone_start_pfn <= pfn)
- && (pfn < z->zone_start_pfn + z->spanned_pages)
- && !(pfn & (pageblock_nr_pages - 1)))
- set_pageblock_migratetype(page, MIGRATE_MOVABLE);/*将页框对应的位图域标记为可移动的*/
- INIT_LIST_HEAD(&page->lru);
- #ifdef WANT_PAGE_VIRTUAL
- /* The shift won't overflow because ZONE_NORMAL is below 4G. */
- if (!is_highmem_idx(zone))
- set_page_address(page, __va(pfn << PAGE_SHIFT));
- #endif
- }
- }
- </SPAN>
<span style="font-size:12px">void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,unsigned long start_pfn, enum memmap_context context){struct page *page;unsigned long end_pfn = start_pfn + size;unsigned long pfn;struct zone *z;if (highest_memmap_pfn < end_pfn - 1)highest_memmap_pfn = end_pfn - 1;z = &NODE_DATA(nid)->node_zones[zone];for (pfn = start_pfn; pfn < end_pfn; pfn++) {/* * There can be holes in boot-time mem_map[]s * handed to this function. They do not * exist on hotplugged memory. */if (context == MEMMAP_EARLY) {if (!early_pfn_valid(pfn))continue;if (!early_pfn_in_nid(pfn, nid))continue;}page = pfn_to_page(pfn);set_page_links(page, zone, nid, pfn);mminit_verify_page_links(page, zone, nid, pfn);init_page_count(page);reset_page_mapcount(page);SetPageReserved(page);/* * Mark the block movable so that blocks are reserved for * movable at startup. This will force kernel allocations * to reserve their blocks rather than leaking throughout * the address space during boot when many long-lived * kernel allocations are made. Later some blocks near * the start are marked MIGRATE_RESERVE by * setup_zone_migrate_reserve() * * bitmap is created for zone's valid pfn range. but memmap * can be created for invalid pages (for alignment) * check here not to call set_pageblock_migratetype() against * pfn out of zone. */ /*如果pfn处在合理的范围,并且该pfn是一个pageblock的起始页框号*/if ((z->zone_start_pfn <= pfn) && (pfn < z->zone_start_pfn + z->spanned_pages) && !(pfn & (pageblock_nr_pages - 1)))set_pageblock_migratetype(page, MIGRATE_MOVABLE);/*将页框对应的位图域标记为可移动的*/INIT_LIST_HEAD(&page->lru);#ifdef WANT_PAGE_VIRTUAL/* The shift won't overflow because ZONE_NORMAL is below 4G. */if (!is_highmem_idx(zone))set_page_address(page, __va(pfn << PAGE_SHIFT));#endif}}</span>
- <SPAN style="FONT-SIZE: 12px">static void set_pageblock_migratetype(struct page *page, int migratetype)
- {
- /*如果没有开启移动性分类,则所有页都要标记为不可移动的*/
- if (unlikely(page_group_by_mobility_disabled))
- migratetype = MIGRATE_UNMOVABLE;
- set_pageblock_flags_group(page, (unsigned long)migratetype,
- PB_migrate, PB_migrate_end);
- }
- </SPAN>
<span style="font-size:12px">static void set_pageblock_migratetype(struct page *page, int migratetype){/*如果没有开启移动性分类,则所有页都要标记为不可移动的*/if (unlikely(page_group_by_mobility_disabled))migratetype = MIGRATE_UNMOVABLE; set_pageblock_flags_group(page, (unsigned long)migratetype,PB_migrate, PB_migrate_end);}</span>
- void set_pageblock_flags_group(struct page *page, unsigned long flags,
- int start_bitidx, int end_bitidx)
- {
- struct zone *zone;
- unsigned long *bitmap;
- unsigned long pfn, bitidx;
- unsigned long value = 1;
- zone = page_zone(page);
- pfn = page_to_pfn(page);
- /*得到位图的起始地址,即zone->pageblock_flags*/
- bitmap = get_pageblock_bitmap(zone, pfn);
- /*得到pfn对应的位图区域的偏移量*/
- bitidx = pfn_to_bitidx(zone, pfn);
- VM_BUG_ON(pfn < zone->zone_start_pfn);
- VM_BUG_ON(pfn >= zone->zone_start_pfn + zone->spanned_pages);
- /*每个页都需要3个bit来表征其移动性,也就是从start_bitidx到end_bitidx共3位*/
- for (; start_bitidx <= end_bitidx; start_bitidx++, value <<= 1)
- if (flags & value)/*通过flags和value相与确定相关的位是否为1*/
- __set_bit(bitidx + start_bitidx, bitmap);
- else
- __clear_bit(bitidx + start_bitidx, bitmap);
- }
void set_pageblock_flags_group(struct page *page, unsigned long flags,int start_bitidx, int end_bitidx){struct zone *zone;unsigned long *bitmap;unsigned long pfn, bitidx;unsigned long value = 1;zone = page_zone(page);pfn = page_to_pfn(page);/*得到位图的起始地址,即zone->pageblock_flags*/bitmap = get_pageblock_bitmap(zone, pfn);/*得到pfn对应的位图区域的偏移量*/bitidx = pfn_to_bitidx(zone, pfn);VM_BUG_ON(pfn < zone->zone_start_pfn);VM_BUG_ON(pfn >= zone->zone_start_pfn + zone->spanned_pages);/*每个页都需要3个bit来表征其移动性,也就是从start_bitidx到end_bitidx共3位*/for (; start_bitidx <= end_bitidx; start_bitidx++, value <<= 1)if (flags & value)/*通过flags和value相与确定相关的位是否为1*/__set_bit(bitidx + start_bitidx, bitmap);else__clear_bit(bitidx + start_bitidx, bitmap);}前面已经介绍了伙伴系统的原理和Linux伙伴系统的数据结构,现在来看伙伴系统是如何来分配页面的。实际上,伙伴系统分配页面的算法并不复杂,但是由于考虑到分配内存时要尽量减少碎片的产生(涉及迁移机制)以及当内存不足时需要采取各种更为积极的手段,使得内核分配页面的相关函数完整地分析起来比较复杂庞大。在这里,我们只关注分配时最一般的情况,而其他情况的处理在以后单独拿出来讨论。
我们从__alloc_pages_nodemask()这个函数开始分析,所有的分配页面的函数最终都会落到这个函数上面,它是伙伴系统的入口。
- <SPAN style="FONT-SIZE: 12px">struct page *
- __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
- struct zonelist *zonelist, nodemask_t *nodemask)
- {
- /*根据gfp_mask确定分配页所处的管理区*/
- enum zone_type high_zoneidx = gfp_zone(gfp_mask);
- struct zone *preferred_zone;
- struct page *page;
- /*根据gfp_mask得到迁移类分配页的型*/
- int migratetype = allocflags_to_migratetype(gfp_mask);
- gfp_mask &= gfp_allowed_mask;
- lockdep_trace_alloc(gfp_mask);
- might_sleep_if(gfp_mask & __GFP_WAIT);
- if (should_fail_alloc_page(gfp_mask, order))
- return NULL;
- /*
- * Check the zones suitable for the gfp_mask contain at least one
- * valid zone. It's possible to have an empty zonelist as a result
- * of GFP_THISNODE and a memoryless node
- */
- if (unlikely(!zonelist->_zonerefs->zone))
- return NULL;
- /* The preferred zone is used for statistics later */
- /*从zonelist中找到zone_idx与high_zoneidx相同的管理区,也就是之前认定的管理区*/
- first_zones_zonelist(zonelist, high_zoneidx, nodemask, &preferred_zone);
- if (!preferred_zone)
- return NULL;
- /* First allocation attempt */
- page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
- zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,
- preferred_zone, migratetype);
- if (unlikely(!page))
- /*第一次分配失败的话则会用通过一条低速路径来进行第二次分配,包括唤醒页换出守护进程等等*/
- page = __alloc_pages_slowpath(gfp_mask, order,
- zonelist, high_zoneidx, nodemask,
- preferred_zone, migratetype);
- trace_mm_page_alloc(page, order, gfp_mask, migratetype);
- return page;
- }</SPAN>
<span style="font-size:12px">struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,struct zonelist *zonelist, nodemask_t *nodemask){/*根据gfp_mask确定分配页所处的管理区*/enum zone_type high_zoneidx = gfp_zone(gfp_mask);struct zone *preferred_zone;struct page *page;/*根据gfp_mask得到迁移类分配页的型*/int migratetype = allocflags_to_migratetype(gfp_mask);gfp_mask &= gfp_allowed_mask;lockdep_trace_alloc(gfp_mask);might_sleep_if(gfp_mask & __GFP_WAIT);if (should_fail_alloc_page(gfp_mask, order))return NULL;/* * Check the zones suitable for the gfp_mask contain at least one * valid zone. It's possible to have an empty zonelist as a result * of GFP_THISNODE and a memoryless node */if (unlikely(!zonelist->_zonerefs->zone))return NULL;/* The preferred zone is used for statistics later *//*从zonelist中找到zone_idx与high_zoneidx相同的管理区,也就是之前认定的管理区*/first_zones_zonelist(zonelist, high_zoneidx, nodemask, &preferred_zone);if (!preferred_zone)return NULL;/* First allocation attempt */page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,zonelist, high_zoneidx, ALLOC_WMARK_LOW|ALLOC_CPUSET,preferred_zone, migratetype);if (unlikely(!page))/*第一次分配失败的话则会用通过一条低速路径来进行第二次分配,包括唤醒页换出守护进程等等*/page = __alloc_pages_slowpath(gfp_mask, order,zonelist, high_zoneidx, nodemask,preferred_zone, migratetype);trace_mm_page_alloc(page, order, gfp_mask, migratetype);return page;}</span>- 首先要做的就是找到指定的分配管理区,管理区的编号保存在high_zoneidx中
- 然后就是尝试第一次分配,流程是从指定的管理区开始扫描管理区-->找到充足的管理区-->从指定的迁移类型链表中分配内存-->如果在指定迁移类型中找不到则到其他的迁移类型中去寻找
- 如果第二步在各个区域都找不到可以满足分配的内存了,那么说明管理区的内存已经确实不够了,于是开始启用一条慢速的途径来分配,包括尝试去换出一些不经常使用的页等等,内核会在这次分配中表现得更为积极,其中的细节涉及到了其他一些复杂的东西,以后再做分析
- static struct page *
- get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,
- struct zonelist *zonelist, int high_zoneidx, int alloc_flags,
- struct zone *preferred_zone, int migratetype)
- {
- struct zoneref *z;
- struct page *page = NULL;
- int classzone_idx;
- struct zone *zone;
- nodemask_t *allowednodes = NULL;/* zonelist_cache approximation */
- int zlc_active = 0; /* set if using zonelist_cache */
- int did_zlc_setup = 0; /* just call zlc_setup() one time */
- /*获取管理区的编号*/
- classzone_idx = zone_idx(preferred_zone);
- zonelist_scan:
- /*
- * Scan zonelist, looking for a zone with enough free.
- * See also cpuset_zone_allowed() comment in kernel/cpuset.c.
- */
- /*从认定的管理区开始遍历,直到找到一个拥有足够空间的管理区,
- 例如,如果high_zoneidx对应的ZONE_HIGHMEM,则遍历顺序为HIGHMEM-->NORMAL-->DMA,
- 如果high_zoneidx对应ZONE_NORMAL,则遍历顺序为NORMAL-->DMA*/
- for_each_zone_zonelist_nodemask(zone, z, zonelist,
- high_zoneidx, nodemask) {
- if (NUMA_BUILD && zlc_active &&
- !zlc_zone_worth_trying(zonelist, z, allowednodes))
- continue;
- /*检查给定的内存域是否属于该进程允许运行的CPU*/
- if ((alloc_flags & ALLOC_CPUSET) &&
- !cpuset_zone_allowed_softwall(zone, gfp_mask))
- goto try_next_zone;
- BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
- if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
- unsigned long mark;
- int ret;
- /*通过alloc_flags来确定是使用何种水印,pages_min?pages_low?pages_high?
- 选择了一种水印,就要求分配后的空闲不低于该水印才能进行分配*/
- mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
- /*如果管理区的水位线处于正常水平,则在该管理区进行分配*/
- if (zone_watermark_ok(zone, order, mark,
- classzone_idx, alloc_flags))
- goto try_this_zone;
- if (zone_reclaim_mode == 0)
- goto this_zone_full;
- /*下面这部分都是针对NUMA架构的申请页面回收*/
- ret = zone_reclaim(zone, gfp_mask, order);
- switch (ret) {
- case ZONE_RECLAIM_NOSCAN:/*没有进行回收*/
- /* did not scan */
- goto try_next_zone;
- case ZONE_RECLAIM_FULL: /*没有找到可回收的页面*/
- /* scanned but unreclaimable */
- goto this_zone_full;
- default:
- /* did we reclaim enough */
- if (!zone_watermark_ok(zone, order, mark,
- classzone_idx, alloc_flags))
- goto this_zone_full;
- }
- }
- try_this_zone:/*分配2^order个页*/
- page = buffered_rmqueue(preferred_zone, zone, order,
- gfp_mask, migratetype);
- if (page)
- break;
- this_zone_full:
- if (NUMA_BUILD)
- zlc_mark_zone_full(zonelist, z);
- try_next_zone:
- if (NUMA_BUILD && !did_zlc_setup && nr_online_nodes > 1) {
- /*
- * we do zlc_setup after the first zone is tried but only
- * if there are multiple nodes make it worthwhile
- */
- allowednodes = zlc_setup(zonelist, alloc_flags);
- zlc_active = 1;
- did_zlc_setup = 1;
- }
- }
- if (unlikely(NUMA_BUILD && page == NULL && zlc_active)) {
- /* Disable zlc cache for second zonelist scan */
- zlc_active = 0;
- goto zonelist_scan;
- }
- return page;
- }
static struct page *get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,struct zonelist *zonelist, int high_zoneidx, int alloc_flags,struct zone *preferred_zone, int migratetype){struct zoneref *z;struct page *page = NULL;int classzone_idx;struct zone *zone;nodemask_t *allowednodes = NULL;/* zonelist_cache approximation */int zlc_active = 0;/* set if using zonelist_cache */int did_zlc_setup = 0;/* just call zlc_setup() one time *//*获取管理区的编号*/classzone_idx = zone_idx(preferred_zone);zonelist_scan:/* * Scan zonelist, looking for a zone with enough free. * See also cpuset_zone_allowed() comment in kernel/cpuset.c. */ /*从认定的管理区开始遍历,直到找到一个拥有足够空间的管理区, 例如,如果high_zoneidx对应的ZONE_HIGHMEM,则遍历顺序为HIGHMEM-->NORMAL-->DMA, 如果high_zoneidx对应ZONE_NORMAL,则遍历顺序为NORMAL-->DMA*/for_each_zone_zonelist_nodemask(zone, z, zonelist,high_zoneidx, nodemask) {if (NUMA_BUILD && zlc_active &&!zlc_zone_worth_trying(zonelist, z, allowednodes))continue;/*检查给定的内存域是否属于该进程允许运行的CPU*/if ((alloc_flags & ALLOC_CPUSET) &&!cpuset_zone_allowed_softwall(zone, gfp_mask))goto try_next_zone;BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {unsigned long mark;int ret; /*通过alloc_flags来确定是使用何种水印,pages_min?pages_low?pages_high? 选择了一种水印,就要求分配后的空闲不低于该水印才能进行分配*/mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];/*如果管理区的水位线处于正常水平,则在该管理区进行分配*/if (zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags))goto try_this_zone;if (zone_reclaim_mode == 0)goto this_zone_full;/*下面这部分都是针对NUMA架构的申请页面回收*/ret = zone_reclaim(zone, gfp_mask, order);switch (ret) {case ZONE_RECLAIM_NOSCAN:/*没有进行回收*//* did not scan */goto try_next_zone;case ZONE_RECLAIM_FULL: /*没有找到可回收的页面*//* scanned but unreclaimable */goto this_zone_full;default:/* did we reclaim enough */if (!zone_watermark_ok(zone, order, mark,classzone_idx, alloc_flags))goto this_zone_full;}}try_this_zone:/*分配2^order个页*/page = buffered_rmqueue(preferred_zone, zone, order,gfp_mask, migratetype);if (page)break;this_zone_full:if (NUMA_BUILD)zlc_mark_zone_full(zonelist, z);try_next_zone:if (NUMA_BUILD && !did_zlc_setup && nr_online_nodes > 1) {/* * we do zlc_setup after the first zone is tried but only * if there are multiple nodes make it worthwhile */allowednodes = zlc_setup(zonelist, alloc_flags);zlc_active = 1;did_zlc_setup = 1;}}if (unlikely(NUMA_BUILD && page == NULL && zlc_active)) {/* Disable zlc cache for second zonelist scan */zlc_active = 0;goto zonelist_scan;}return page;}- 从指定的管理区开始按照zonelist中定义的顺序来遍历管理区
- 如果该管理区的水位线正常,则调用buffered_rmqueue()在该管理区中分配
- 如果管理区的水位线过低,则在NUMA架构下会申请页面回收
- <SPAN style="FONT-SIZE: 12px">static inline
- struct page *buffered_rmqueue(struct zone *preferred_zone,
- struct zone *zone, int order, gfp_t gfp_flags,
- int migratetype)
- {
- unsigned long flags;
- struct page *page;
- int cold = !!(gfp_flags & __GFP_COLD);
- int cpu;
- again:
- cpu = get_cpu();
- if (likely(order == 0)) {/*order为0,即要求分配一个页*/
- struct per_cpu_pages *pcp;
- struct list_head *list;
- pcp = &zone_pcp(zone, cpu)->pcp;/*获取本地CPU对应的pcp*/
- list = &pcp->lists[migratetype];/*获取和迁移类型对应的链表*/
- local_irq_save(flags);
- /*如果链表为空,则表示没有可分配的页,需要从伙伴系统中分配2^batch个页给list*/
- if (list_empty(list)) {
- pcp->count += rmqueue_bulk(zone, 0,
- pcp->batch, list,
- migratetype, cold);
- if (unlikely(list_empty(list)))
- goto failed;
- }
- if (cold)/*如果是需要冷页,则从链表的尾部获取*/
- page = list_entry(list->prev, struct page, lru);
- else /*如果是需要热页,则从链表的头部获取*/
- page = list_entry(list->next, struct page, lru);
- list_del(&page->lru);
- pcp->count--;
- } else {
- if (unlikely(gfp_flags & __GFP_NOFAIL)) {
- /*
- * __GFP_NOFAIL is not to be used in new code.
- *
- * All __GFP_NOFAIL callers should be fixed so that they
- * properly detect and handle allocation failures.
- *
- * We most definitely don't want callers attempting to
- * allocate greater than order-1 page units with
- * __GFP_NOFAIL.
- */
- WARN_ON_ONCE(order > 1);
- }
- spin_lock_irqsave(&zone->lock, flags);
- /*从管理区的伙伴系统中选择合适的内存块进行分配*/
- page = __rmqueue(zone, order, migratetype);
- spin_unlock(&zone->lock);
- if (!page)
- goto failed;
- __mod_zone_page_state(zone, NR_FREE_PAGES, -(1 << order));
- }
- __count_zone_vm_events(PGALLOC, zone, 1 << order);
- zone_statistics(preferred_zone, zone);
- local_irq_restore(flags);
- put_cpu();
- VM_BUG_ON(bad_range(zone, page));
- if (prep_new_page(page, order, gfp_flags))
- goto again;
- return page;
- failed:
- local_irq_restore(flags);
- put_cpu();
- return NULL;
- }
- </SPAN>
<span style="font-size:12px">static inlinestruct page *buffered_rmqueue(struct zone *preferred_zone,struct zone *zone, int order, gfp_t gfp_flags,int migratetype){unsigned long flags;struct page *page;int cold = !!(gfp_flags & __GFP_COLD);int cpu;again:cpu = get_cpu();if (likely(order == 0)) {/*order为0,即要求分配一个页*/struct per_cpu_pages *pcp;struct list_head *list;pcp = &zone_pcp(zone, cpu)->pcp;/*获取本地CPU对应的pcp*/list = &pcp->lists[migratetype];/*获取和迁移类型对应的链表*/local_irq_save(flags);/*如果链表为空,则表示没有可分配的页,需要从伙伴系统中分配2^batch个页给list*/if (list_empty(list)) {pcp->count += rmqueue_bulk(zone, 0,pcp->batch, list,migratetype, cold);if (unlikely(list_empty(list)))goto failed;}if (cold)/*如果是需要冷页,则从链表的尾部获取*/page = list_entry(list->prev, struct page, lru);else /*如果是需要热页,则从链表的头部获取*/page = list_entry(list->next, struct page, lru); list_del(&page->lru);pcp->count--;} else {if (unlikely(gfp_flags & __GFP_NOFAIL)) {/* * __GFP_NOFAIL is not to be used in new code. * * All __GFP_NOFAIL callers should be fixed so that they * properly detect and handle allocation failures. * * We most definitely don't want callers attempting to * allocate greater than order-1 page units with * __GFP_NOFAIL. */WARN_ON_ONCE(order > 1);}spin_lock_irqsave(&zone->lock, flags);/*从管理区的伙伴系统中选择合适的内存块进行分配*/page = __rmqueue(zone, order, migratetype);spin_unlock(&zone->lock);if (!page)goto failed;__mod_zone_page_state(zone, NR_FREE_PAGES, -(1 << order));}__count_zone_vm_events(PGALLOC, zone, 1 << order);zone_statistics(preferred_zone, zone);local_irq_restore(flags);put_cpu();VM_BUG_ON(bad_range(zone, page));if (prep_new_page(page, order, gfp_flags))goto again;return page;failed:local_irq_restore(flags);put_cpu();return NULL;}</span>
- 该函数分两种情况进行处理,一种是只要求分配单个页框,另一种是要求分配多个连续页框
- 对于单个页面,内核选择从每CPU页框高速缓存中分配,它的核心描述结构也是MIGRATE_TYPES个链表,只不过链表中的元素都是单个页。这些页分为热页和冷页,所谓热页就是还处在CPU高速缓存中的页,相反,冷页就是不存在于高速缓存中的页。对于单个页框的申请,分配热页可以提高效率。需要注意的是,越靠近链表头的页越热,越靠近链表尾的页越冷,因为每次释放单个页框的时候,页框是插入到链表的头部的,也就是说靠近头部的页框是最近才释放的,因此最有可能存在于高速缓存当中
- 对于连续的页框分配,通过调用__rmqueue()来完成分配
- <SPAN style="FONT-SIZE: 12px">static struct page *__rmqueue(struct zone *zone, unsigned int order,
- int migratetype)
- {
- struct page *page;
- retry_reserve:
- page = __rmqueue_smallest(zone, order, migratetype);
- /*如果分配失败并且迁移类型不是MIGRATE_RESERVE(如果是MIGRATE_RESERVE,
- 则表明已经没有其他的迁移类型可供选择了)*/
- if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {
- page = __rmqueue_fallback(zone, order, migratetype);
- /*
- * Use MIGRATE_RESERVE rather than fail an allocation. goto
- * is used because __rmqueue_smallest is an inline function
- * and we want just one call site
- */
- if (!page) {
- migratetype = MIGRATE_RESERVE;
- goto retry_reserve;
- }
- }
- trace_mm_page_alloc_zone_locked(page, order, migratetype);
- return page;
- }
- </SPAN>
<span style="font-size:12px">static struct page *__rmqueue(struct zone *zone, unsigned int order,int migratetype){struct page *page;retry_reserve:page = __rmqueue_smallest(zone, order, migratetype);/*如果分配失败并且迁移类型不是MIGRATE_RESERVE(如果是MIGRATE_RESERVE, 则表明已经没有其他的迁移类型可供选择了)*/if (unlikely(!page) && migratetype != MIGRATE_RESERVE) {page = __rmqueue_fallback(zone, order, migratetype);/* * Use MIGRATE_RESERVE rather than fail an allocation. goto * is used because __rmqueue_smallest is an inline function * and we want just one call site */if (!page) {migratetype = MIGRATE_RESERVE;goto retry_reserve;}}trace_mm_page_alloc_zone_locked(page, order, migratetype);return page;}</span>
- 首先按照指定的迁移类型,调用__rmqueue_smallest()来分配对应的内存块,该函数是伙伴系统的算法体现
- 如果分配失败,则说明指定的迁移类型中没有充足的内存来满足分配,这时就要按fallbacks中定义的顺序从其他的迁移链表中寻找了,__rmqueue_fallback()函数较为复杂,体现了利用迁移类型来避免碎片的思想,后面单独拿出来分析
- static inline
- struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
- int migratetype)
- {
- unsigned int current_order;
- struct free_area * area;
- struct page *page;
- /* Find a page of the appropriate size in the preferred list */
- for (current_order = order; current_order < MAX_ORDER; ++current_order) {
- /*获取和现在的阶数对应的free_area*/
- area = &(zone->free_area[current_order]);
- /*和迁移类型对应的free_list为空则不执行下面的内容*/
- if (list_empty(&area->free_list[migratetype]))
- continue;
- /*得到满足要求的页块中的第一个页描述符*/
- page = list_entry(area->free_list[migratetype].next,
- struct page, lru);
- list_del(&page->lru);
- rmv_page_order(page);/*将page的private域设为0*/
- area->nr_free--; /*内存块数减1*/
- /*进行拆分(在current_order>order的情况下)*/
- expand(zone, page, order, current_order, area, migratetype);
- return page;
- }
- return NULL;
- }
static inlinestruct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype){unsigned int current_order;struct free_area * area;struct page *page;/* Find a page of the appropriate size in the preferred list */for (current_order = order; current_order < MAX_ORDER; ++current_order) {/*获取和现在的阶数对应的free_area*/area = &(zone->free_area[current_order]);/*和迁移类型对应的free_list为空则不执行下面的内容*/if (list_empty(&area->free_list[migratetype]))continue; /*得到满足要求的页块中的第一个页描述符*/page = list_entry(area->free_list[migratetype].next,struct page, lru);list_del(&page->lru);rmv_page_order(page);/*将page的private域设为0*/area->nr_free--; /*内存块数减1*//*进行拆分(在current_order>order的情况下)*/expand(zone, page, order, current_order, area, migratetype);return page;}return NULL;}- static inline void expand(struct zone *zone, struct page *page,
- int low, int high, struct free_area *area,
- int migratetype)
- {
- unsigned long size = 1 << high;/*order为high的页块对应的页框数*/
- /*申请的order为low,实际分配的块对应的order为high
- 如果high大于low则要将大块进行拆分,并且将拆分后的伙伴块添加到下一级order的块链表中去*/
- while (high > low) {
- area--;/*area减1得到下一级order对应的area*/
- high--;/*high减1表明进行了一次拆分*/
- size >>= 1;/*拆分一次size就要除以2*/
- VM_BUG_ON(bad_range(zone, &page[size]));
- /*通过size来定位拆分后的伙伴块的起始页框描述符,
- 并将其作为第一个块添加到下一级order的块链表中*/
- list_add(&page[size].lru, &area->free_list[migratetype]);
- area->nr_free++;/*该order区域的块数加1*/
- set_page_order(&page[size], high);/*设定private域为high*/
- }
- }
static inline void expand(struct zone *zone, struct page *page,int low, int high, struct free_area *area,int migratetype){unsigned long size = 1 << high;/*order为high的页块对应的页框数*//*申请的order为low,实际分配的块对应的order为high 如果high大于low则要将大块进行拆分,并且将拆分后的伙伴块添加到下一级order的块链表中去*/while (high > low) {area--;/*area减1得到下一级order对应的area*/high--;/*high减1表明进行了一次拆分*/size >>= 1;/*拆分一次size就要除以2*/VM_BUG_ON(bad_range(zone, &page[size]));/*通过size来定位拆分后的伙伴块的起始页框描述符,并将其作为第一个块添加到下一级order的块链表中*/list_add(&page[size].lru, &area->free_list[migratetype]);area->nr_free++;/*该order区域的块数加1*/set_page_order(&page[size], high);/*设定private域为high*/}} 只需要注意一点,一个块的定位可以由块首的起始页对应的描述符和order(size)来定位,因此只需要将一个块的第一个页描述符链入相应的链表就可以了。
Linux内存释放函数之间的调用关系如下图所示

可以看到,落脚点是__free_pages()这个函数,它执行的工作的流程图如下图所示

下面是该函数的具体代码
- void __free_pages(struct page *page, unsigned int order)
- {
- if (put_page_testzero(page)) {/*判断页没有被使用*/
- trace_mm_page_free_direct(page, order);
- if (order == 0)/*单页则释放到每CPU页框高速缓存中*/
- free_hot_page(page);
- else /*多页则释放到伙伴系统*/
- __free_pages_ok(page, order);
- }
- }
void __free_pages(struct page *page, unsigned int order){if (put_page_testzero(page)) {/*判断页没有被使用*/trace_mm_page_free_direct(page, order);if (order == 0)/*单页则释放到每CPU页框高速缓存中*/free_hot_page(page);else /*多页则释放到伙伴系统*/__free_pages_ok(page, order);}}
确定页是空闲的后,再判断要释放多少个页面,如果是单个页面则将该页作为热页释放到pcp中,如果是多页则释
放到伙伴系统中
- void free_hot_page(struct page *page)
- {
- trace_mm_page_free_direct(page, 0);
- free_hot_cold_page(page, 0);
- }
void free_hot_page(struct page *page){trace_mm_page_free_direct(page, 0);free_hot_cold_page(page, 0);}
free_hot_page是free_hot_cold_page的封装
- static void free_hot_cold_page(struct page *page, int cold)
- {
- struct zone *zone = page_zone(page);
- struct per_cpu_pages *pcp;
- unsigned long flags;
- int migratetype;
- int wasMlocked = __TestClearPageMlocked(page);
- kmemcheck_free_shadow(page, 0);
- if (PageAnon(page))
- page->mapping = NULL;
- if (free_pages_check(page))
- return;
- if (!PageHighMem(page)) {
- debug_check_no_locks_freed(page_address(page), PAGE_SIZE);
- debug_check_no_obj_freed(page_address(page), PAGE_SIZE);
- }
- arch_free_page(page, 0);
- kernel_map_pages(page, 1, 0);
- /*获取对应的pcp结构*/
- pcp = &zone_pcp(zone, get_cpu())->pcp;
- /*获取迁移类型*/
- migratetype = get_pageblock_migratetype(page);
- set_page_private(page, migratetype);
- local_irq_save(flags);
- if (unlikely(wasMlocked))
- free_page_mlock(page);
- __count_vm_event(PGFREE);
- /*
- * We only track unmovable, reclaimable and movable on pcp lists.
- * Free ISOLATE pages back to the allocator because they are being
- * offlined but treat RESERVE as movable pages so we can get those
- * areas back if necessary. Otherwise, we may have to free
- * excessively into the page allocator
- */
- /*只有不可移动页,可回收页和可移动页才能放到每CPU页框高速缓存中,如果
- 迁移类型不属于这个范围,则要将该页释放回伙伴系统*/
- if (migratetype >= MIGRATE_PCPTYPES) {
- if (unlikely(migratetype == MIGRATE_ISOLATE)) {
- free_one_page(zone, page, 0, migratetype);
- goto out;
- }
- migratetype = MIGRATE_MOVABLE;
- }
- if (cold)/*冷页插入表尾*/
- list_add_tail(&page->lru, &pcp->lists[migratetype]);
- else /*热页插入表头*/
- list_add(&page->lru, &pcp->lists[migratetype]);
- pcp->count++;
- /*如果pcp中的页面数超过了high,则释放2^batch个单页给伙伴系统*/
- if (pcp->count >= pcp->high) {
- free_pcppages_bulk(zone, pcp->batch, pcp);
- pcp->count -= pcp->batch;
- }
- out:
- local_irq_restore(flags);
- put_cpu();
- }
static void free_hot_cold_page(struct page *page, int cold){struct zone *zone = page_zone(page);struct per_cpu_pages *pcp;unsigned long flags;int migratetype;int wasMlocked = __TestClearPageMlocked(page);kmemcheck_free_shadow(page, 0);if (PageAnon(page))page->mapping = NULL;if (free_pages_check(page))return;if (!PageHighMem(page)) {debug_check_no_locks_freed(page_address(page), PAGE_SIZE);debug_check_no_obj_freed(page_address(page), PAGE_SIZE);}arch_free_page(page, 0);kernel_map_pages(page, 1, 0);/*获取对应的pcp结构*/pcp = &zone_pcp(zone, get_cpu())->pcp;/*获取迁移类型*/migratetype = get_pageblock_migratetype(page);set_page_private(page, migratetype);local_irq_save(flags);if (unlikely(wasMlocked))free_page_mlock(page);__count_vm_event(PGFREE);/* * We only track unmovable, reclaimable and movable on pcp lists. * Free ISOLATE pages back to the allocator because they are being * offlined but treat RESERVE as movable pages so we can get those * areas back if necessary. Otherwise, we may have to free * excessively into the page allocator */ /*只有不可移动页,可回收页和可移动页才能放到每CPU页框高速缓存中,如果 迁移类型不属于这个范围,则要将该页释放回伙伴系统*/if (migratetype >= MIGRATE_PCPTYPES) {if (unlikely(migratetype == MIGRATE_ISOLATE)) {free_one_page(zone, page, 0, migratetype);goto out;}migratetype = MIGRATE_MOVABLE;}if (cold)/*冷页插入表尾*/list_add_tail(&page->lru, &pcp->lists[migratetype]);else /*热页插入表头*/list_add(&page->lru, &pcp->lists[migratetype]);pcp->count++;/*如果pcp中的页面数超过了high,则释放2^batch个单页给伙伴系统*/if (pcp->count >= pcp->high) {free_pcppages_bulk(zone, pcp->batch, pcp);pcp->count -= pcp->batch;}out:local_irq_restore(flags);put_cpu();}
伙伴系统的分支__free_pages_ok()先对释放的页做了些检查,然后具体的释放通过调用free_one_page()-->__free_one_page()来完成
- static inline void __free_one_page(struct page *page,
- struct zone *zone, unsigned int order,
- int migratetype)
- {
- unsigned long page_idx;
- if (unlikely(PageCompound(page)))
- if (unlikely(destroy_compound_page(page, order)))
- return;
- VM_BUG_ON(migratetype == -1);
- /*得到页框在所处最大块中的偏移*/
- page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1);
- VM_BUG_ON(page_idx & ((1 << order) - 1));
- VM_BUG_ON(bad_range(zone, page));
- /*只要阶数小于MAX_ORDER-1就有合并的机会*/
- while (order < MAX_ORDER-1) {
- unsigned long combined_idx;
- struct page *buddy;
- /*找到page所处块对应的伙伴块*/
- buddy = __page_find_buddy(page, page_idx, order);
- /*如果伙伴块不是空闲的则不执行下面的合并操作*/
- if (!page_is_buddy(page, buddy, order))
- break;
- /* Our buddy is free, merge with it and move up one order. */
- list_del(&buddy->lru);/*将伙伴块从块链表中删除*/
- zone->free_area[order].nr_free--;
- rmv_page_order(buddy);
- /*计算出合并块的起始页框的偏移*/
- combined_idx = __find_combined_index(page_idx, order);
- /*得到合并块的起始页描述符*/
- page = page + (combined_idx - page_idx);
- page_idx = combined_idx;/*修改块的起始页偏移*/
- order++;/*阶数加1表明合并完成*/
- }
- /*重新设置块的阶数*/
- set_page_order(page, order);
- /*将新块添加到对应的链表中*/
- list_add(&page->lru,
- &zone->free_area[order].free_list[migratetype]);
- zone->free_area[order].nr_free++;
- }
static inline void __free_one_page(struct page *page,struct zone *zone, unsigned int order,int migratetype){unsigned long page_idx;if (unlikely(PageCompound(page)))if (unlikely(destroy_compound_page(page, order)))return;VM_BUG_ON(migratetype == -1);/*得到页框在所处最大块中的偏移*/page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1);VM_BUG_ON(page_idx & ((1 << order) - 1));VM_BUG_ON(bad_range(zone, page));/*只要阶数小于MAX_ORDER-1就有合并的机会*/while (order < MAX_ORDER-1) {unsigned long combined_idx;struct page *buddy;/*找到page所处块对应的伙伴块*/buddy = __page_find_buddy(page, page_idx, order);/*如果伙伴块不是空闲的则不执行下面的合并操作*/if (!page_is_buddy(page, buddy, order))break;/* Our buddy is free, merge with it and move up one order. */list_del(&buddy->lru);/*将伙伴块从块链表中删除*/zone->free_area[order].nr_free--;rmv_page_order(buddy);/*计算出合并块的起始页框的偏移*/combined_idx = __find_combined_index(page_idx, order);/*得到合并块的起始页描述符*/page = page + (combined_idx - page_idx);page_idx = combined_idx;/*修改块的起始页偏移*/order++;/*阶数加1表明合并完成*/}/*重新设置块的阶数*/set_page_order(page, order);/*将新块添加到对应的链表中*/list_add(&page->lru,&zone->free_area[order].free_list[migratetype]);zone->free_area[order].nr_free++;}
这里面涉及到两个辅助函数,_page_find_buddy()用来找到是释放块的伙伴,如果找到了一个空闲的伙伴块要通过_find_combined_index()用来定位合并块的起始页框,因为一个块的伙伴块有可能在该块的前面,也有可能在该块的后面,这两个函数的实现非常简洁巧妙,全是通过位操作来实现的
- static inline struct page *
- __page_find_buddy(struct page *page, unsigned long page_idx, unsigned int order)
- {
- unsigned long buddy_idx = page_idx ^ (1 << order);
- return page + (buddy_idx - page_idx);
- }
static inline struct page *__page_find_buddy(struct page *page, unsigned long page_idx, unsigned int order){unsigned long buddy_idx = page_idx ^ (1 << order);return page + (buddy_idx - page_idx);}
- <SPAN style="FONT-SIZE: 12px">static inline unsigned long
- __find_combined_index(unsigned long page_idx, unsigned int order)
- {
- return (page_idx & ~(1 << order));
- }</SPAN>
<span style="font-size:12px">static inline unsigned long__find_combined_index(unsigned long page_idx, unsigned int order){return (page_idx & ~(1 << order));}</span>
我们可以通过一个简单的情形来模拟一下这个过程,假设现在有一个将要释放的页,它的order为0,page_idx为10
则先计算它的伙伴 10^(1<<0) = 11,然后计算合并后的起始页偏移为10&~(1<<0) = 10,现在就得到了一个order为1的块,起始页偏移为10,它的伙伴为10^(1<<1)=8,合并后的起始页偏移为10&~(1<<1)=8,如此推导下去,我们可以通过下图和下表更清晰地分析这个过程


其中pi代表page_idx, ci代表combined_idx
从2.6.32.25开始,linux在伙伴管理系统中引入迁移类型(migrate type)这么一个概念,用于避免系统在长期运行过程中产生碎片。关于迁移类型的一些概念在介绍伙伴系统的数据结构的时候有提到过(见<<Linux伙伴系统(一)>>),不过考虑到它较为复杂,因此在解析分配页的过程中没有介绍迁移类型是如何工作的,在这里将这部分拿出来单独作为一个部分进行分析。
在分析具体的代码前,再来说一下为什么要引入迁移类型。我们都知道伙伴系统是针对于解决外碎片的问题而提出的,那么为什么还要引入这样一个概念来避免碎片呢?我们注意到,碎片一般是指散布在内存中的小块内存,由于它们已经被分配并且插入在大块内存中,而导致无法分配大块的连续内存。而伙伴系统把内存分配出去后,要再回收回来并且重新组成大块内存,这样一个过程必须建立两个伙伴块必须都是空闲的这样一个基础之上,如果其中有一个伙伴不是空闲的,甚至是其中的一个页不是空闲的,都会导致无法分配一块连续的大块内存。我们再引用之前上过的一个例子来看这个问题:

图中,如果15对应的页是空闲的,那么伙伴系统可以分配出连续的16个页框,而由于15这一个页框被分配出去了,导致最多只能分配出8个连续的页框。假如这个页还会被回收回伙伴系统,那么至少在这段时间内产生了碎片,而如果更糟的,如果这个页用来存储一些内核永久性的数据而不会被回收回来,那么碎片将永远无法消除,这意味着15这个页所处的最大内存块永远无法被连续的分配出去了。假如上图中被分配出去的页都是不可移动的页,那么就可以拿出一段内存,专门用于分配不可移动页,虽然在这段内存中有碎片,但是避免了碎片散布到其他类型的内存中。在系统中所有的内存都被标识为可移动的!也就是说一开始其他类型都没有属于自己的内存,而当要分配这些类型的内存时,就要从可移动类型的内存中夺取一部分过来,这样可以根据实际情况来分配其他类型的内存。现在我们就来看看伙伴系统分配页时,当指定的迁移类型的内存不足时,系统是如何做的
- <SPAN style="FONT-SIZE: 12px">/* Remove an element from the buddy allocator from the fallback list */
- static inline struct page *
- __rmqueue_fallback(struct zone *zone, int order, int start_migratetype)
- {
- struct free_area * area;
- int current_order;
- struct page *page;
- int migratetype, i;
- /* Find the largest possible block of pages in the other list */
- /*从最大的内存块链表开始遍历阶数,内核倾向于尽量找到大的内存块来满足分配*/
- for (current_order = MAX_ORDER-1; current_order >= order;
- --current_order) {
- for (i = 0; i < MIGRATE_TYPES - 1; i++) {/*根据fallbacks中定义的顺序遍历后面的迁移类型*/
- migratetype = fallbacks[start_migratetype][i];
- /* MIGRATE_RESERVE handled later if necessary */
- if (migratetype == MIGRATE_RESERVE)
- continue;
- area = &(zone->free_area[current_order]);
- if (list_empty(&area->free_list[migratetype]))
- continue;
- /*取块首的页*/
- page = list_entry(area->free_list[migratetype].next,
- struct page, lru);
- area->nr_free--;
- /*
- * If breaking a large block of pages, move all free
- * pages to the preferred allocation list. If falling
- * back for a reclaimable kernel allocation, be more
- * agressive about taking ownership of free pages
- */
- /*pageblock_order定义着内核认为的大块内存究竟是多大*/
- /*如果 1.当前得到的块是一个比较大的块,即阶数大于pageblock_order/2=5
- 或者 2.之前指定的迁移类型为可回收页
- 或者 3.没有启用迁移分组机制*/
- if (unlikely(current_order >= (pageblock_order >> 1)) ||
- start_migratetype == MIGRATE_RECLAIMABLE ||
- page_group_by_mobility_disabled) {
- unsigned long pages;
- /*试图将当前页所处的最大内存块移到之前指定的迁移类型对应的链表中,
- 只有空闲页才会移动,所以真正可移动的页数pages可能小于2^pageblock_order*/
- pages = move_freepages_block(zone, page,
- start_migratetype);
- /* Claim the whole block if over half of it is free */
- /*移动的页面数大于大内存块的一半,则修改整个块的迁移类型*/
- if (pages >= (1 << (pageblock_order-1)) ||
- page_group_by_mobility_disabled)
- set_pageblock_migratetype(page,
- start_migratetype);
- migratetype = start_migratetype;
- }
- /* Remove the page from the freelists */
- list_del(&page->lru);
- rmv_page_order(page);
- /* Take ownership for orders >= pageblock_order */
- /*如果current_order大于等于10,则将超出的部分的迁移类型设为start_migratetype*/
- if (current_order >= pageblock_order)
- change_pageblock_range(page, current_order,
- start_migratetype);
- /*拆分,这里注意的是如果之前改变了migratetype,则会将拆分的伙伴块添加到新的迁移类型链表中*/
- expand(zone, page, order, current_order, area, migratetype);
- trace_mm_page_alloc_extfrag(page, order, current_order,
- start_migratetype, migratetype);
- return page;
- }
- }
- return NULL;
- }
- </SPAN>
<span style="font-size:12px">/* Remove an element from the buddy allocator from the fallback list */static inline struct page *__rmqueue_fallback(struct zone *zone, int order, int start_migratetype){struct free_area * area;int current_order;struct page *page;int migratetype, i;/* Find the largest possible block of pages in the other list *//*从最大的内存块链表开始遍历阶数,内核倾向于尽量找到大的内存块来满足分配*/for (current_order = MAX_ORDER-1; current_order >= order;--current_order) { for (i = 0; i < MIGRATE_TYPES - 1; i++) {/*根据fallbacks中定义的顺序遍历后面的迁移类型*/migratetype = fallbacks[start_migratetype][i];/* MIGRATE_RESERVE handled later if necessary */if (migratetype == MIGRATE_RESERVE)continue;area = &(zone->free_area[current_order]);if (list_empty(&area->free_list[migratetype]))continue;/*取块首的页*/page = list_entry(area->free_list[migratetype].next,struct page, lru);area->nr_free--;/* * If breaking a large block of pages, move all free * pages to the preferred allocation list. If falling * back for a reclaimable kernel allocation, be more * agressive about taking ownership of free pages */ /*pageblock_order定义着内核认为的大块内存究竟是多大*/ /*如果 1.当前得到的块是一个比较大的块,即阶数大于pageblock_order/2=5 或者 2.之前指定的迁移类型为可回收页 或者 3.没有启用迁移分组机制*/if (unlikely(current_order >= (pageblock_order >> 1)) ||start_migratetype == MIGRATE_RECLAIMABLE ||page_group_by_mobility_disabled) {unsigned long pages;/*试图将当前页所处的最大内存块移到之前指定的迁移类型对应的链表中,只有空闲页才会移动,所以真正可移动的页数pages可能小于2^pageblock_order*/pages = move_freepages_block(zone, page,start_migratetype);/* Claim the whole block if over half of it is free *//*移动的页面数大于大内存块的一半,则修改整个块的迁移类型*/if (pages >= (1 << (pageblock_order-1)) ||page_group_by_mobility_disabled)set_pageblock_migratetype(page,start_migratetype);migratetype = start_migratetype;}/* Remove the page from the freelists */list_del(&page->lru);rmv_page_order(page);/* Take ownership for orders >= pageblock_order *//*如果current_order大于等于10,则将超出的部分的迁移类型设为start_migratetype*/if (current_order >= pageblock_order)change_pageblock_range(page, current_order,start_migratetype); /*拆分,这里注意的是如果之前改变了migratetype,则会将拆分的伙伴块添加到新的迁移类型链表中*/expand(zone, page, order, current_order, area, migratetype);trace_mm_page_alloc_extfrag(page, order, current_order,start_migratetype, migratetype);return page;}}return NULL;}</span>
- 首先我们看到的不寻常的一点就是,for循环优先遍历大的内存块,也就是说优先分配大内存块,这似乎和伙伴系统优先分配小内存块的原则相违背,但是仔细想想这样做其实就是为了避免在新的迁移类型中引入碎片。如何说?现在假如A类型内存不足,向B类型求援,假设只从B中分配一块最适合的小块,OK,那么过会儿又请求分配A类型内存,又得向B类型求援,这样来来回回从B类型中一点一点的分配内存将会导致B类型的内存四处都散布碎片,如果这些内存一直得不到释放……内核已经不敢想象了……B类型可能会因为A类型而引入的碎片导致其再也分配不出大的内存块了。出于这种原因,内核选择直接分配一块最大的内存块给A,你们爱怎么打怎么闹随便你们,反正都是在A类型中进行,只要不拖累我B类型就可以了
- 当请求分配的内存比较大时或者最初的请求类型为可回收类型时,会表现得更加积极,也就是我前面所说的将对应的最大内存块搬到最初的请求类型对应的链表中。我的理解是,这里判断一个比较大的内存类型的条件是用来和前面优先遍历大内存块的for循环相呼应的,也就是说假如得到的内存块是一个比较小的内存块,那就说明该内存类型自己也没有大块可分配的连续内存了,因此就不执行搬迁工作。而对于可回收类型的内存要执行搬迁是因为在一些时候,内核可能会非常频繁地申请小块可回收类型的内存。
- 当搬迁的内存的大于大块内存的一半时,将彻底将这块内存化为己有,也就是说将这片大块内存区对应的页类型标识位图区域标识成最初申请的内存类型。
用<<深入Linux内核架构>>上的一段话作为总结,“实际上,在启动期间分配可移动内存区的情况较少,那么分配器有很高的几率分配长度最大的内存区,并将其从可移动列表转换到不可移动列表。由于分配的内存区长度是最大的,因此不会向可移动内存中引入碎片。总而言之,这种做法避免了启动期间内核分配的内存(经常在系统的整个运行时间都不释放)散布到物理内存各处,从而使其他类型的内存分配免受碎片的干扰,这也是页可移动性分组框架的最重要目标之一
- 内存_页的使用
- 内存_页的初始化
- [libxml2]_[C/C++]_[使用libxml2读取内存的xml片段]
- 内存_内存管理的不同阶段
- 04_查看Android内存使用情况
- 内存_页框回收
- banner的使用_
- 操作系统_内存管理_程序的装入和链接
- 黑马程序员_ 变量的内存分析
- C++对象的内存布局_
- 85_线程导致的内存泄漏
- [Cocoa]_[初级]_[NSThread的使用]
- 内存_内存管理
- 内存_内存池
- c语言中较常见的由内存分配引起的错误_内存越界_内存未初始化_内存太小_结构体隐含指针
- c语言中较常见的由内存分配引起的错误_内存越界_内存未初始化_内存太小_结构体隐含指针
- 内存_浅谈C++中内存泄漏的检测
- 内存_浅谈C++中内存泄漏的检测
- IOCP+WinSock2新函数打造高性能SOCKET池
- 【工具】show_space
- 音视频即时通讯应用
- The Best Questions for Would-be C++ Programmers, Part 2
- stm32库函数GPIO_PinRemapConfig分析
- 内存_页的使用
- scala对map的操作
- Android FileObserver
- javax.persistence.TransactionRequiredException: no transaction is in progress
- Android项目proguard代码混淆遇到的一系列问题,外部jar,Gson包等
- N-Queens II
- 作业
- sqlldr和外部表使用记录
- 如何清除Windows共享登录的用户名密码记录


