Scanner vs. StringTokenizer vs. String.Split
来源:互联网 发布:淘宝网广告形式 编辑:程序博客网 时间:2024/06/18 08:39
They're essentially horses for courses.
Scanneris designed for cases where you need to parse a string, pulling out data of different types. It's very flexible, but arguably doesn't give you the simplest API for simply getting an array of strings delimited by a particular expression.
String.split()andPattern.split()give you an easy syntax for doing the latter, but that's essentially all that they do. If you want to parse the resulting strings, or change the delimiter halfway through depending on a particular token, they won't help you with that.
StringTokenizeris even more restrictive thanString.split(), and also a bit fiddlier to use. It is essentially designed for pulling out tokens delimited by fixed substrings. Because of this restriction, it's about twice as fast asString.split(). It also predates the regular expressions API, of whichString.split()is a part.
You'll note from my timings that String.split() can still tokenize thousands of strings in a few milliseconds on a typical machine. In addition, it has the advantage over StringTokenizer that it gives you the output as a string array, which is usually what you want. Using an Enumeration, as provided by StringTokenizer, is too "syntactically fussy" most of the time. From this point of view,StringTokenizer is a bit of a waste of space nowadays, and you may as well just useString.split().
As noted in our introduction to the String.split() method, the latter is around twice as slow as a bog-standard StringTokenizer, although it is more flexible.
Compiling the pattern
Using String.split() is convenient as you can tokenise and get the result in a single line. But it is sub-optimal in that it must recompile the regular expression each time. A possible gain is to compile the pattern once, then call Pattern.split():
Pattern p = Pattern.compile("\\s+");...String[] toks = p.split(str);However, the benefit of compiling the pattern becomes marginal the more tokens there are in the string being tokenised. The graph below shows the time taken on one test system (2GHz Pentium running JDK 1.6.0 under Windows) to tokenise 10,000 random strings consisting of between 1 and 19 5-character tokens separated by a single space1.
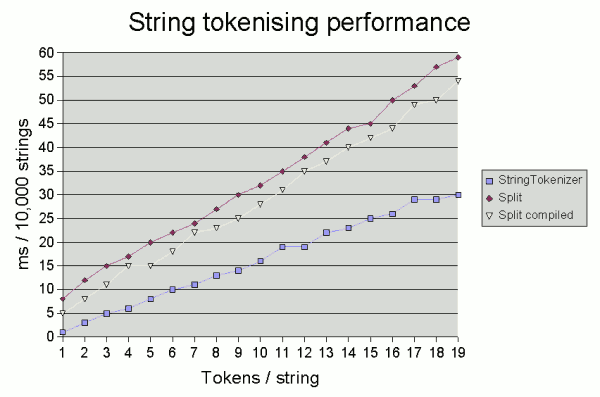
Now, what these results highlight is that whatever method you use, there's also no need to panic unless you're doing a lot of tokenisation: even the fairly extreme case of tokenising 10,000 19-token strings took just 60 milliseconds. However, if you are doing a serious amount of tokenising (for example, in some of my corpus linguistics work, I frequently process corpora consisting of millions of words and occasionally shaving time off the "nuts and bolts" of parsing can be useful), then the good old StringTokenizer may still be worth using for performance reasons. If you can cope with its restrictions, of course. The results above suggest that compiling the pattern is comparatively most beneficial if you are tokenising a large number of strings each with few tokens.
转自:stackoverflow.com/questions/691184/scanner-vs-stringtokenizer-vs-string-split
- Scanner vs. StringTokenizer vs. String.Split
- Scanner vs. StringTokenizer vs. String.Split
- String.split VS StringTokenizer
- StringTokenizer类与String.split()的区别
- String.split()和StringTokenizer(string str,string delim)构造函数
- String VS StringBuffer VS StringBuilder
- C# string vs String
- String的substring、split, StringTokenizer 截取字符串性能比较
- String的substring、split, StringTokenizer 截取字符串性能比较
- String的substring、split,外加StringTokenizer三者截取字符
- String 的 split、subString,外加StringTokenizer之性能比较
- String类的split()方法与StringTokenizer方法
- string+vs String.format ,append vs AppendFormat
- <string>VS<string.h>VS<cstring>
- String(+) vs StringBuffer(append)
- String vs StringBuilder
- string VS char
- StringBuffer VS String
- IOS几种简单有效的数组排序方法
- import maven projects 卡死,抛出GC overhead limit exceeded
- autolayout自动布局详解
- 设计模式之(三)Proxy模式
- 判断字符串是否为布尔型、浮点型、整型...
- Scanner vs. StringTokenizer vs. String.Split
- LCD-驱动基础
- 单例模式
- php分页类
- 2013 ACM/ICPC Asia Regional Nanjing Online( hdu 4749)
- PHP写入txt文件换行
- JBOSS中配置JNDI数据源
- php数据库操作类
- YII 框架 第八天(4) 显示sql语句执行时间


