信息论学习总结(一)基础知识 博客分类: Machine Learning information theory信息论机器学习 我们考虑一下一个离散的随机变量x,当我们观察到它的一个值,能给我们带来
来源:互联网 发布:黑帽seo 流量劫持 编辑:程序博客网 时间:2024/05/16 05:30
信息论学习总结(一)基础知识
- 博客分类:
- Machine Learning
information theory信息论机器学习
我们考虑一下一个离散的随机变量x,当我们观察到它的一个值,能给我们带来多少信息呢?这个信息量可以看做是我们观察到x的这个值带来的惊讶程度。我们被告知一个不太可能发生的事发生了要比告知一个非常可能发生的事发生,我们获得信息要多。
所以信息量的多少依赖于概率分布p(x),所以我们可以用关于p(x)的一个函数来建模信息量h(x).那什么函数模型适合表达呢?
我们观察两个相互独立的事件x,y,我们观察它得到的信息量,要和单独观察他们得到的信息量之和相等。即
h(x,y) = h(x) + h(y)
而两个独立的时间x,y的概率关系:
p(x,y) = p(x) p(y)
基于上面的观察,信息量必须和p(x)的log函数相关。
所以我们得到:
=-log_{2}p(x))
加上负号,可以保证信息量大于等于0。注意一个小概率事件,具有更高的信息量。
log的底数选择并没有限制。信息论中大多都采用2,传输这些信息量需要的2进制位数。
如果我们想传输这个随机变量的值,我们传输的平均信息量,可以表示为关于分布
p(x)的期望:
=-\sum_{x}p(x)log_{2}p(x))
这个表达式被称为信息熵。
在机器学习中,采用比较多的是自然对数形式,
这样
=-\sum_{x}p(x)\ln{p(x)})
对x=0的情况,由于

所以我们让p(x)ln(x) = 0
如果对这些信息进行编码传输,我们希望概率大的使用较长的编码,概率小的我们采用较长的编码。最大熵能够达到最小长度的编码,关于熵和最短编码长度的关系,可以参考shannon的Noiseless coding theorem。
熵用来描述指定随机变量的状态,所需要的平均信息。
如果我们想最大化熵,我们利用拉格朗日乘子:
}+\lambda(\sum_i{p{(x_i)}-1))
我们可以得=1/M)
取得最大值,其中M是x状态数。
如果我们有一个联合分布p(x,y),如果x已经知道,那么指定y的值还需要的信息量,
可以通过-ln p(y|x)来描述,所以平均还需要的信息量,可以表示为:
\ln{p(y|x)}dydx})
被称为条件熵。我们利用乘法规则,可以得到:
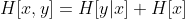
相对熵和互信息:
考虑一个未知的分布p(x),假设我们使用了一个近似的分布q(x)来建模它,
如果我们使用q(x)来构建一个编码模式,用来传输x的值。那么额外需要多指定的信息:
=-\int{p(x)ln{q(x)}}dx-(-\int{p(x)ln{p(x)}}dx)=-\int{p(x)ln\{\frac{q(x)}{p(x)}\}}dx)
这个式子被称为相对熵或者Kullback-Leibler divergence
相对熵描述了p(x)和q(x)两个分布的差异程度。注意:
\ne{KL(q||p)})
我们考虑联合分布p(x,y),如果x,y相互独立,那么p(x,y)=p(x)p(y)
如果他们不相互独立,那么我们想知道他们的相关程度,我们可以使用KL divergence来度量:
=KL(p(x,y)||p(x)p(y))=-\iint{p(x,y)ln{\frac{p(x)p(y)}{p(x,y)}}dxdy)
这个表达式被称为变量x,y的互信息。从KL divergence的属性我们知道I(x,y)>= 0
当且仅当x和y相互独立时,等号成立。
我们使用加法和乘法规则得到互信息是相对于条件熵的:
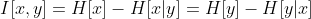
所以信息量的多少依赖于概率分布p(x),所以我们可以用关于p(x)的一个函数来建模信息量h(x).那什么函数模型适合表达呢?
我们观察两个相互独立的事件x,y,我们观察它得到的信息量,要和单独观察他们得到的信息量之和相等。即
h(x,y) = h(x) + h(y)
而两个独立的时间x,y的概率关系:
p(x,y) = p(x) p(y)
基于上面的观察,信息量必须和p(x)的log函数相关。
所以我们得到:
加上负号,可以保证信息量大于等于0。注意一个小概率事件,具有更高的信息量。
log的底数选择并没有限制。信息论中大多都采用2,传输这些信息量需要的2进制位数。
如果我们想传输这个随机变量的值,我们传输的平均信息量,可以表示为关于分布
p(x)的期望:
这个表达式被称为信息熵。
在机器学习中,采用比较多的是自然对数形式,
这样
对x=0的情况,由于
所以我们让p(x)ln(x) = 0
如果对这些信息进行编码传输,我们希望概率大的使用较长的编码,概率小的我们采用较长的编码。最大熵能够达到最小长度的编码,关于熵和最短编码长度的关系,可以参考shannon的Noiseless coding theorem。
熵用来描述指定随机变量的状态,所需要的平均信息。
如果我们想最大化熵,我们利用拉格朗日乘子:
我们可以得
取得最大值,其中M是x状态数。
如果我们有一个联合分布p(x,y),如果x已经知道,那么指定y的值还需要的信息量,
可以通过-ln p(y|x)来描述,所以平均还需要的信息量,可以表示为:
被称为条件熵。我们利用乘法规则,可以得到:
相对熵和互信息:
考虑一个未知的分布p(x),假设我们使用了一个近似的分布q(x)来建模它,
如果我们使用q(x)来构建一个编码模式,用来传输x的值。那么额外需要多指定的信息:
这个式子被称为相对熵或者Kullback-Leibler divergence
相对熵描述了p(x)和q(x)两个分布的差异程度。注意:
我们考虑联合分布p(x,y),如果x,y相互独立,那么p(x,y)=p(x)p(y)
如果他们不相互独立,那么我们想知道他们的相关程度,我们可以使用KL divergence来度量:
这个表达式被称为变量x,y的互信息。从KL divergence的属性我们知道I(x,y)>= 0
当且仅当x和y相互独立时,等号成立。
我们使用加法和乘法规则得到互信息是相对于条件熵的:
- 信息论学习总结(一)基础知识 博客分类: Machine Learning information theory信息论机器学习 我们考虑一下一个离散的随机变量x,当我们观察到它的一个值,能给我们带来
- [机器学习]信息论(Information theory)的一些point
- 机器学习中的一些信息论 information theory
- CS281: Advanced Machine Learning 第二节 information theory 信息论
- 信息论(Information theory)的一些知识点
- 干货丨谷歌Tensorflow一岁啦,它能给我们带来怎样的改变?
- 希望学习期间能给我们带来快乐,就像VI工具一样,分享一个配置文件吧
- 点net学习一:点net是什么,它给我们带来了什么
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节1.6,Information Theory信息论简介
- Machine Learning第六讲[应用机器学习的建议] --(三)建立一个垃圾邮件分类器
- Docker学习总结(6)——通过 Docker 化一个博客网站来开启我们的 Docker 之旅
- 英语学习可以给我们带来什么
- 一个基于信息论的人生观
- Machine Learning分类总结 和机器学习的四个等级
- 一个美国青年给我们的震撼
- 一个牛人给我们的建议
- 当我们试图复制一个复杂值的时候
- 选择排序
- 怎么使用PHP和MySQL创建个性的网站分页
- poj 3469
- 移动web开发,html头部规范
- 一个统计文件字数的小程序
- 信息论学习总结(一)基础知识 博客分类: Machine Learning information theory信息论机器学习 我们考虑一下一个离散的随机变量x,当我们观察到它的一个值,能给我们带来
- java多线程选择实现Runnable接口而不是直接继承Thread类的原因
- 在6410上挂载NFS服务器
- 构造函数为什么不能是虚函数
- 洪涝灾害研究方法总结
- distinct用法注意事项和q''
- 自由的大学
- 程序设计方法(一):结构化、基于对象、面向对象、基于接口
- hdu1088 Write a simple HTML Browser


