在 Rails 中使用 Solr 做全文搜尋
来源:互联网 发布:c语言字符串拼接 编辑:程序博客网 时间:2024/06/06 01:14
做網站常免不了使用全文搜尋的功能,很多時候我們會選擇方便快速的 Google Custom Search ,但搜尋的結果差強人意,因此我們會更希望能擁有自己的搜尋引擎。
Solr & Sunspot
Solr 是一套建立在 Lucene 搜尋引擎的工具,不用煩惱如何去操作複雜的 Lucene ,只需要透過 HTTP Request 來跟 Solr 溝通就好,非常的簡單易用,在 Rails 使用比簡單還要更簡單,因為我們有 sunspot_rails ,你不需要下載 Slor 來編譯執行他,因為 sunspot_rails 這套 gem 已經幫你包在裡面了,你只需要如同往常的將他加到 Gemfile ,然後 bundle install ,最後啟動它就完成了他所需要的動作,簡單到覺得寫篇文章來講彷彿都侮辱了他。
設定及啟動 Solr:
使用 sunspot_rails 非常簡單:
在你的 Gemfile:
1gem 'sunspot_rails'然後:
1$ bundle installSolr 本身跑在一個獨立的 proccess ,因此我們需要啟動它:
1$ rake sunspot:solr:start當然你也可以停止它,將 start 換成 stop 就好:
1$ rake sunspot:solr:stop當你啟動了 Solr Server ,你會發現 solr 複製了一些檔案到你 Rails 下一個 Solr 的目錄,這是因為 Solr 將搜尋的 index 都放在這個檔案目錄中,這樣一來就算你重新啟動 Server 也仍然會保留你的 index 。
 solr
solr
建立搜尋
假設我今天要在部落格使用 Solr ,在我的 Rails 專案中我建立一個 scaffold 的 post,有 title 與 content 的 fields:
12rails g scaffold post title:string text:contentrake db:migrate再來我們要在 Post 的 model 中設定讓 Solr 對 Title 做 index:
1234567class Post < ActiveRecord::Base validates_presence_of :title, :content searchable do text :title endend在 Solr 中只有 text 欄位是做全文搜尋,其他如 time、integer、boolean…等其他欄位都只能用來作排序/過濾/限制的選項而已。
在 controller 中我們也需要建立一個 search 的 Action 讓人可以做搜尋:
12345678910 def search @posts = Post.search do keywords params[:query] end.results respond_to do |format| format.html { render :action => "index" } format.xml { render :xml => @posts } end end在 View 中我們也加入一個搜尋的欄位:
12345<%= form_tag search_posts_path, :method => :get do %> <p> <%= text_field_tag :query, params[:query] %> <%= submit_tag "搜尋" %> </p><% end %>來看看成果:
搜尋前:
 solr index
solr index
搜尋後:
 solr results
solr results
超簡單的吧!
加入現有的內容並 Reindex
若是我們想要加入一個 field 也變為搜尋的內容該怎麼辦? Solr 提供你一個 reindex 的功能可以方便你達成,首先先將你想要加入搜尋的 field 加到 model 中:
1234567class Post < ActiveRecord::Base validates_presence_of :title, :content searchable do text :title, :content endend這時候 Solr 就會將未來所有的 content 也加入 index 的範圍內,但我們還需要將已經產生的 content 也做 index,因此我們執行:
1$ rake sunspot:reindexSolr 便會自動幫我們將所有內容做 index ,我們現在搜尋便會加入了 content 的內容:
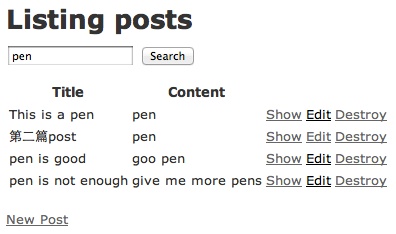 solr content search
solr content search
真是太方便了!!
斷字系統
只要是碰到搜尋免不了就有語言的問題,也會碰到斷字的問題,像剛剛的搜尋中,搜尋 pen 會有結果,但是搜尋 ‘pe’ 或是 ‘en’ 就會看不到任何結果,這個問題我們只要簡單的設定一下 Solr 就可以解決了,還記得在你啟動 Solr 的時候在你 Rails 的目錄下也建立了 Solr 的資料夾,現在我們要去設定 RAILS_ROOT/solr/conf/schema.xml 這支檔案,找到下面這個片段(大約在62行):
1234567<fieldType name="text" class="solr.TextField" omitNorms="false"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StandardFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer></fieldType>改成:
1234567891011121314<fieldType name="text" class="solr.TextField" omitNorms="false"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StandardFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.NGramFilterFactory" minGramSize="2" maxGramSize="15"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StandardFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer></fieldType>在這裡我們設定讓 Solr 對最少2個字元最大15個字元做 index,例如以單字 Character 來說就會對 ‘Ch’、’ar’、’ra’、’Cha’…都做 index,這時重新啟動你的 Solr 並重新 index:
123rake sunspot:solr:stoprake sunspot:solr:startrake sunspot:reindex這時候你的搜尋結果就會依照我們剛剛的設定生效了:
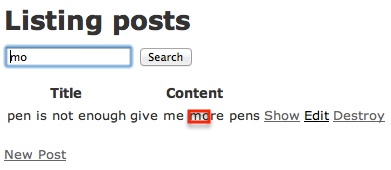 solr result
solr result
如果你想要讓所有 index 只從字首開始算,那麼將剛剛設定中的 solr.NGramFilterFactory 改為 solr.EdgeNGramFilterFactory 就可以了,更多的斷字設定建議妳可以參考 Solr 的 Wiki
如果想讓你的 Solr 支援中文也很簡單,你只要將設定中的 tokenizer 替換成你想要使用的分詞系統就可以了, Solr 本身內建簡單的 CJK 分詞系統,你只要將原先的 StandardTokenizerFactory 替換掉:
1<tokenizer class="solr.StandardTokenizerFactory"/>換成:
1<tokenizer class="solr.CJKTokenizerFactory"/>一樣照上面的流程重新啟動 Solr 並做 reindex 的動作就可以看到結果了:
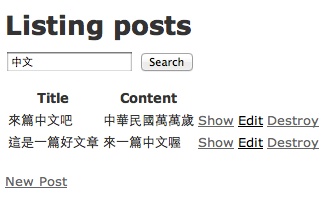 Solr CJK
Solr CJK
Solr 非常強大卻又非常簡單,有很多的特異功能你可以去使用,建議你可以將它的 Wiki好好看過,快速的設定也可以參考 sunspot_rails 的 Github 上的說明。
參考:
- Github: sunspot_rails
- Solr Wiki
- 在 Rails 中使用 Solr 做全文搜尋
- java中solr全文检索的使用
- 【Rails】在Rails中使用Gravatar
- 【Rails】在Rails中使用Gravatar
- 全文检索solr在商城案例中的使用
- 在 Rails 中使用 JavaScript
- 在 Rails 中使用 Webpack
- 使用solr搭建全文检索
- PHP使用Solr全文搜索引擎
- 在Ruby On Rails项目中使用Redis做缓存数据库
- 在Sql Server中使用全文检索
- 在全文索引中同义词的使用
- 在全文索引中同义词的使用
- 在全文索引中同义词的使用
- 在mysql中使用全文索引
- 在Ruby on Rails中使用FCKeditor
- Rails 在javascript中使用ruby对象
- 在rails中使用FusionCharts生成报表
- 现代名图专为填补市场空白
- 常见数据结构查找、插入、删除、遍历性能比较 常见排序算法的比较(图)
- 使用for..in时会遍历对象原型中的自定义属性
- wince5.0 中兴3G模块驱动分析
- FastDFS
- 在 Rails 中使用 Solr 做全文搜尋
- win7下安装vc6.0(sp5,sp6补丁安装)
- php过滤xml中的特殊字符
- 简单步骤开启Linux telnet服务
- __FUNCSIG__、__FUNCDNAME__、__FUNCTION__、__func__、__PRETTY_FUNCTION__
- HttpModule与HttpHandler详解
- 年华细碎,遗漏的半夏锦年
- springMVC基础上的hibernate与c3p0整合案例
- 窗口样式:禁止最大化,不能拖动边框以改变窗口大小


