高效的数据结构和经典算法
来源:互联网 发布:e4a数据库怎么破解 编辑:程序博客网 时间:2024/06/10 06:27
本文介绍了常用的高效数据结构,包括bloom filter、跳跃表、trie树、线段树、B树、KD树、树状数组、并查集、红黑树和约瑟夫环问题。全部是简要的描述,建立在大家都对这些数据结构有一定的了解基础上,快速的复习。如果想要继续深入研究请看参考文献后面的详细讲述。还有手动开方的方法(这个简单方便):
1 Bloom filter
Bloom filter是由Howard Bloom在1970年提出的二进制向量数据结构,它可以快速的判定一个元素是不是存在该集合之中。它的答案有可能在集合内(可能错误)、不在集合内(一定不在),它是牺牲了正确率换取时间和空间的一种方法。
是一种改进的哈希函数,如果一个元素对应的k个点均为1则认为该元素存在在集合之中,反之认为不在集合之中。
我们可以得到

现在令f≤є,可以推出,具体推导见参考文献4。有时候我会再继续深入的研究的。

2 跳跃表
跳跃表是一种随机化的数据结构,由 由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出,这种数据结构以有序的方式在层次化的链表中保存元素,它的效率可以和平衡树媲美--- 查找、删除、添加等操作都在指数的期望下在对数期望下完成。并且相对于平衡树来说,跳跃表的是先要简单得多。

跳跃表主要由3部分组成,表头(负责跳跃表节点指针)、层(保存着元素值,以及多层)、表尾(全部由NULL组成)。
跳跃表的链满足如下条件:
(1) 每个链必须包含链两个元素-+∞ 和 -∞.
(2)S0包含所有的元素,并且所有的连表中的元素按照升序排列。
(3)每条链中集合必须包含序数较小的链的元素的集合。
(4)层i中的元素按照某个固定的概率p出现在层i+1中。平均起来,每个元素都在1/(1-p)中出现。而最高层重的元素在O(LOG(1/pn))个列表中出现。
3 trie树
字典树又称为单词查找树,是哈希树的一种变种,主要应用于字符串的快速检索,统计和保存。可以使用公共前缀来节省存储空间,并且相对于哈希表可以有更高效的查找和比对。Trie树的核心思想是空间换取时间,不过在字符串存储的时候使用字典树也可以压缩存储空间的。
应用字符串的快速检索、排序和公共前缀查找。
4 线段树
线段树是一种很特殊的数据结构,是静态建立的,平衡类似平衡二叉树。每个节点代表一个线段,每个元节点代表长度为1的线段。线段树空间复杂度为O(L),插入一个线段和删除一个线段的复杂度为O(logn)。将线段(a,b)插入到线段(l,r)之中,令mid=(l+r)/2。如果a<mid那么将序列也插入到节点的左儿子中,如果b>mid那么将节点也插入到节点的右儿子之中。
线段树的典型应用是查询记录线段是否被覆盖,和查询覆盖的线段长度。
5 B-树 B+,B*树
B-树:
B树是一种平衡的多路查找树,在文件系统中主要作为文件的索引。也多用在数据库索引中。因为外存较慢,而且使用二叉树很容易造成频繁的I/O读写,现在可以引入多叉树来改变这种情况的。
我们还是从二叉树如何过渡到B树讲起吧,B树与红黑树最大的不同在于,B树的节点可以有很多子女,从几个到几千个。可是N各节点的B树的高度也是O(lgn),但是也可能比红黑树小很多,因为它可以有很多个分支。
B-树,简称B树的性质:

1. 根节点至少有两个子女。
2. 每个非根节点所包含的直接点的数目在m/2到m之间。
3. 一个包含n[x]个关键字的内节点x,有n[x+1]个子女。
4. 根节点至少包含两个孩子,如果它不是一个叶子节点。
5. 所有叶子节点在同一层,并且包含节点信息。
B-树的搜索性质:
由于限制了除根节点之外的节点至少包含M/2各节点,保证了节点的利用率。其底层搜索的性能为:

由于有M/2的限制,再插入节点时,如果节点已满,需要将节点分裂为两个各占M/2的节点。删除节点时,需要将两个不足M/2的节点进行合并。
B+树:
B+树的性质:
B+树是B-树的一种变体,也是一种多路搜索树。
1. 其定义与B-树相同。
2. 除了非叶子节点的子树指针与关键字个数相同。
3. 非叶子节点的子树指针P[i],指向关键字属于[K[i], K[i+1])的子树。
4. 所有叶子节点增加一个指针。
5. 所有的关键字都在叶子节点出现。
此时不可能在非叶子节点命中,非叶子节点只相当于是索引。更加适合文件索引系统。
B*树:
B*树的性质:
1. B*树飞叶子节点的关键字数目至少为(2/3)*M,即使用率更高。
2. 插入后树分裂方式不同。
B+树当一个节点满时,分配一个新节点,并将元节点中的1/2数据复制到新的电接点,最哦后在父节点中增加新节点的指针。B+树的分裂只影响原节点和父节点,而不会影响兄弟节点,所以它不需要指向兄弟指针。
B*树当一个节点满时,如果它的下一个兄弟节点未满,那么将一部分数据已送到兄弟节点中。再在源节点中插入关键字。如果兄弟节点也满了,则在源节点与兄弟节点之间增加新节点,个复制1/3的数据到新节点,并在父节点增加新的节点指针。
所以B*树分配新节点的概率比B+树更低,空间利用率更高。
6 KD树
看完R树,再回来看KD树就觉得很好玩。KD树是二叉树的高维空间扩展,而R树是B树的高维空间扩展,所以简单很多的了。
KD树的构建过程如下图所示:

1. 确定方差,选取划分的维度。
2. 选取划分维度的中位数为划分点,将数据进行划分。
3. 分别构建左右子树。很好玩的是KD树,有父节点的指针。
KD树的插入:
插入,选取划分维度插入。
KD树的删除:
使用被删除节点的左子树的最右节点,或者右子树的最左节点来替换要删除的节点。
7 R树
R树在数据库领域中功绩显著,它很好的解决了高维空间的搜索问题。举个例子:如何查找20英里以内的所有餐厅?R树就很好的解决了这个问题,它把B树的思想很好的扩展到了高维空间。采用了B树分割空间的思想,并在添加、删除等操作的时候合并和分裂子节点,保证书的平衡性。因此R树就是一颗用来存储高维数据的平衡树。
在高维空间时,选取一个最小边界矩形来存储这个矩形覆盖的那些数据。叶子节点包含数据项,非叶子节点只包含边界数据。示例图如下:
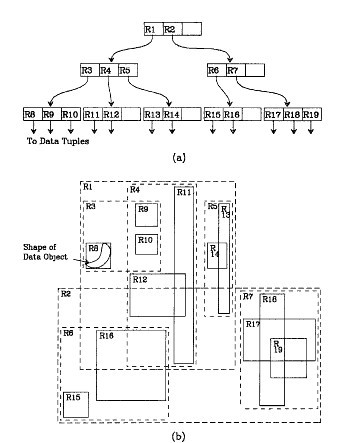
R树的性质:
1. 除非它是根节点之外,所有的叶子节点包含m至M个记录索引。所以根节点的叶子节点所具有的记录的个数小于m,通常m=M/2。
2. 对于所有的在叶子中 存储的记录,I是最小的可以在空间中完全覆盖这些记录的矩形。
3. 每一个非叶子节点拥有m-M个孩子节点,除非它是根节点。
4. 对于在非叶子节点上的每一条目,i是最小的可以在空间哇会给你完全覆盖这些条目所代表的点的矩形。
5. 所有的叶子节点都位于同一层,因此R成为平衡树。
8 树状数组
树状数组是动态维护一个动态数组的区域和的一个很重要的数据结构。插入、删除和修改数组元素之后的维护操作时间复杂度都是O(logn)。
有事我们需要维护和求数组的前缀和或者某一段区间的和。如果我们维护一个数组:
S[i] = A[1] + A[2] + ...... + A[i]。
我们可以发现,如果改变了A[i]之后,A[i], S[i], S[i+1], .... , S[n]都会发生变化。
可以说每次修改A[i]之后,调整前缀和S需要最坏 O(n)的时间。
当n非常大的时候,程序也会变的非常慢。
因此我们引入树状数组,它的修改与求和都是O(logn)的,效率非常高。
理论:树状数组的示例图如下:
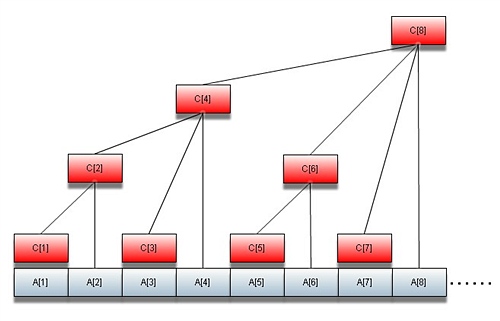
如图所示:红色的矩阵表示的数组C[]就是树状数组。
这里,C[i]表示A[i-2^k+1]到A[i]的和,其中k则是i在二进制末尾0的个数。或者i使用2的幂次方和表示时的最小指数。
当然利用位运算,我们可以直接得到2^k=i&(i^(i-1))。
同时,我们也不难发现,这个k就是该节点在书中的高度,因而这个树的高度不会超过logn。
所以我们在修改A[i]的时候,可以从C[i]往节点一路上溯,调整这条路上所有的C[]即可。
这个操作的复杂度在最坏的情况下是树的高度即为O(logn)。
另外再求数列的前n项的和,只需要找到n以前所有最大子树,把其根节点的C加起来即可。不难发现,这些子树的数目是n在二进制是的1的个数,或者是把n展开成2的幂次方和时的项数,因此求和的复杂度也是O(logn)。
其中计算2^k,有一个快速的计算公式 2^k=i&(i^(i-1))。
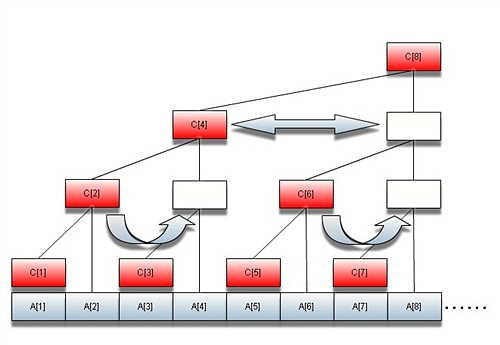
另外如果我们将树进行反转,既可以得到完全二叉树。该二叉树的性质,后续再继续补充。
求解前n项的和:
int sum(int end){
int sum=0;
while(end>0){
sum += in[end];
end -= Lowbit(end);
}
return sum;
}
9 并查集
并查集是一种树形数据结构,用于处理一些不相交的集合。其实我看了很多文章说的很玄乎,其实就是倒序的树索引。支持两个十分快速的工作:
1) 合并两个并不相交的集合。
2) 判断两个元素是否属于一个集合。

优化:
并查集的优化有:路径压缩(可以减少路径的深度)和rank合并。复杂度:O(n*α(n)),其中α(x),对于x=宇宙中原子数之和,α(x)不大于4。
10 红黑树
红黑树的性质:
1. 节点都是红色的或者黑色的。
2. 根节点是黑色的。
3. 每个叶子节点是黑色的。
4. 每个红色节点的两个子节点都是黑色的。
5. 从一节点到任意叶子节点包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质:从根节点到叶子节点的最长路径不多于最短可能路径的两倍长。
11 约瑟夫环
问题:有n个人(编号0~n-1),从0开始报数,报数为m-1的退出。剩下的人从0开始继续报数,直到最后一个剩余的人为获胜者。求问胜利者的编号。
我们首先对第一次报数,和第一次报数完成后的第二次报数进行计算。
首先计算k=m%n。
那么第一次报数完毕之后,剩余n-1个人,他们的编号为:
k k+1 k+2 ... n-2 n-1 0 1 2 3 ... k-2 并且这次报数,从k开始报0.
现在我们把他们的编号做一下转换:
k --> 0
k+1 ---> 1
k+2 ---> 2
.....
.....
k-2 ---> n-2
k-1 ---> n-1
变换之后变成了n-1个人报数的子问题,假如我们知道这个子问题的解:例如x是最终的胜利者,那么我们根据上面这个表就可以把这个x变回n个人的情况。变回去的公式记为:x'=(x+k)%n。
同样的对于n-1,和n-2个人的情况是同样的。
那么我们可以得到递推公式:
f[1]=0
f[i]=(f[i-1]+m)%i; ( i>1 )
对于约瑟夫环问题,首先想到的是可以构建环形链表,通过遍历环形链表来计算。可是这样费时费空间。
如果我们对这个问题进行深入的研究发现,我们可以通过将问题进行计算后转化为数学问题,通过转化为子问题来简化计算的。
12 顺序统计树
其实树的节点包含了,当前子树包含多少个元素,并且子树中多少个元素比该节点的元素取值大的。因此我们在计算逆序对的时候就可以很快的计算的。
13 KMP
想了很久,原来KMP是利用待匹配数组的子串和该数组的前缀和后缀信息来加速比对过程,在比对不匹配的时候计算下一个跳跃匹配的地址的。
首先举一个例子来说明KMP是如何计算跳跃的数目的:
例如在计算KMP数组中的,待匹配串为“ababa”,那么在这个字符串中,满足即是自身的真后缀,也是自身的最长前缀为"aba",我们假设这个特殊的字符长度为L,显然L=3。因此我们在已经匹配到"ababa",并且下一个匹配不成功的时候可以直接向后跳2位。这个就是KMP算法的原理。
因此我们可以直接计算next数组。
位置i
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
前缀next[i]
0
0
0
0
1
2
3
1
2
3
4
5
6
7
4
0
子串
a
g
c
t
a
g
c
a
g
c
t
a
g
c
t
g
未完待续,LZ会在随后将这数据结构的具体分析补上。等LZ闲了,把代码一一给写出来,奉献给大家。
14 欧拉回路和欧拉环
欧拉环:图中经过每条边一次且仅一次的环。
欧拉路径:途中经过每条边一次且仅有一次的路径。
欧拉图:有至少一个欧拉环的图。
半欧拉图:没有欧拉环,但有至少一条欧拉路径的图。
目前只看了无向图和有向图的欧拉回路判定,这个比较容易理解的。
无向图:
当且仅当图时连通的,并且所有的节点度数都是偶数。一个无向图是半欧拉图当且仅当该图示连通的并且只有2个点的度数是奇数。
有向图:
当且仅当该图的基图是连通的并且所有的点的入度等于初读;一个有向图是半欧拉图当且仅当该图的基图是连通的切有且只有一个点的入度比出度少1,有且只有一个点的入度比出度多1,其余的入度等于出度。
混合图:(解法很有意思,也很复杂)
15 手动开方的方法
有一种开放的方法简单易行,并且容易快速记住和推导,简直是居家旅行必备良方。它就是反馈开方,反馈开方的递推公式如下(将A=()):

它的推导过程如下:
A=(x+y)^k=....=忽略x二次以上的。
我们可以得到 A= x^k + kx^(k-1)y
我们于是可以求解得到y,并且将A^1/k带入即可求解得到最终的迭代公式,碉堡了。
特别的:
手动开平方:X(n + 1) = Xn + (A / Xn − Xn)1 / 2.
手动开立方:X(n+1)=Xn+(A/X^2-Xn)1/3
参考文献:
B-树、B+树http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
Bloom Filter 详解: http://blog.csdn.net/jiaomeng/article/details/1495500
KD树详解:http://blog.csdn.net/zhouxuguang236/article/details/7898272
海量数据处理之Bloom Filter: http://blog.csdn.net/v_july_v/article/details/6685894
KMP算法next数组:http://www.cnblogs.com/10jschen/archive/2012/08/21/2648451.html
KMP算法(理解超赞,适合初学者)http://billhoo.blog.51cto.com/2337751/411486
欧拉回路和欧拉环:http://blog.chinaunix.net/uid-26380419-id-3164913.html
手动迭代开方:http://blog.sina.com.cn/s/blog_566d8c290101lpmx.html
- 高效的数据结构和经典算法
- 数据结构和经典算法
- 经典数据结构和算法
- 【算法结构】一些经典的算法和数据结构的问题
- 数据结构和算法经典书籍
- 经典数据结构和算法回顾
- 经典数据结构和算法回顾
- 数据结构和算法经典书籍
- 数据结构若干经典问题和算法 (收藏)
- 数据结构和算法经典文章汇总
- Java 数据结构和经典算法经验总结
- 经典数据结构 [ Hash算法 ]
- 经典数据结构 [ Hash算法 ]
- java 数据结构经典算法
- 算法:经典数据结构题
- 以前和同学俩做的一套比较经典的数据结构算法Flash教学课件
- 《算法爱好者》三个经典面试题高效版(有更高效的请留言)
- 算法入门经典第六章数据结构—树和二叉树-1.二叉树的编号
- 关于 jar包中MANIFEST.MF 写法
- 能说明你的Javascript技术很烂的五个原因
- 使用 live555 直播来自 v4l2 的摄像头图像
- 7zip命令行调用
- [Git] 远程重命名项目分支
- 高效的数据结构和经典算法
- flex+blazeds+java+spring后台消息推送,有界面维护
- 关于UIView的autoresizingMask属性的研究
- SQLServer2008中报实例错误。
- SVN基本操作汇总
- Linux内核中64位除法函数do_di
- unity3d学习笔记(十二)--刀光剑影的制作
- 配置连接池连接Oarcle RAC集群
- 每天进步一点点——swift对象副本修复之简单理解


