打造高性能日志系统
来源:互联网 发布:the walk知乎 编辑:程序博客网 时间:2024/04/28 02:54
前言
说起日志系统, 大家都不陌生, 每次线上出了问题, 大家通常都会第一时间抓log回来进行分析, 很多时候这些log是我们恢复现场的重要途径也可能成为了唯一手段, 所以重要性不言而喻. 市面上的开源日志系统有很多, 如log4cxx, log4cpp, glog等等, 最终目的都只有一个 -- 写日志. 于是如何优雅,高效,安全的写日志是大家的一致需求.
说起优雅, 这里我指的是风格上的优雅, 也有指接口使用上的优雅, 这些库都下了不少功夫也几乎奠定了行业标准, 比如自定义format, log level, 灵活的config file.
说起安全, 这里指线程安全, 不能一条log被打散分成了多节穿插在多条log中间, 这样的日志就完全没有可读性, 几乎无用了.
说起高效, 大家各显神通, 从系统接口上的选取, 设计模型上的斟酌, 再到代码级别的优化.
好了, 废话不多说了, 介绍了一些大体情况后, 本篇将会讲述使用Thread Caching模型来编写高效的日志系统. 文章将会分为几个部分:
- 需求分析
- 设计模型
- 流程分析
- 测试结果
- 代码优化
- 总结
好了, 那我们开始吧 :D
需求分析首先我们要明确一些目的, 在保证优雅安全的前提下尽可能的快速, 这是前提, 否则一切都是空谈. 那是不是越快越好那? 这个问题我们先留在后面进行分析.
明确前提的情况下, 我们先来看看传统经典的模型是什么样的. 下图是一个传统异步写入的模型:
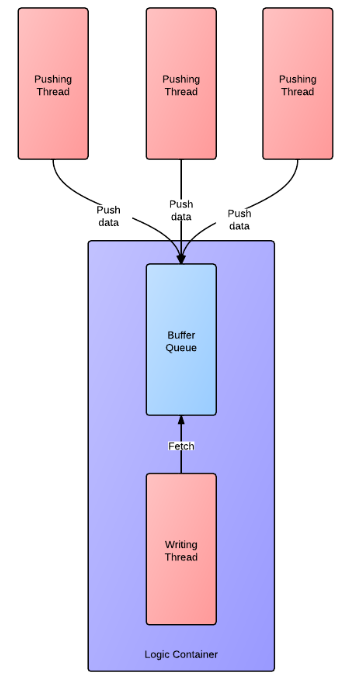
采用异步接口主要为了避免磁盘IO阻塞导致逻辑线程阻塞, 阻塞现象在生产环境中是不可容忍的问题.
多线程方面, 通常使用加锁保证写入日志安全性, 防止log被打散. 但这也造成了性能的损失, 性能损失会随着每条log写入时间的长短以及有多少个线程同时写共同影响.
现在我们来整理一下需求, 接下来要做的日志系统需要满足以下几点要求:
- 提供异步接口.
- 线程安全.
- 完全无锁化.
设计模型
为了满足线程安全还要实现无锁, 传统的模型无法满足, 我们仔细分析一下传统模型的思路 -- 当多个线程同时写日志时, 数据被压入一个buffer队列中, 此时buffer跟后台线程在逻辑上通常联系到一起, 认为是一个整体看待, 后台线程的职责为被动接受数据并写入磁盘, 此时的模型为多个生产者一个消费者, 必然导致加锁. 换个思路, 化被动为主动, 如果为每个线程分配一块自己的buffer, 而后台线程主动的去每个thread buffer中取数据, 再写入磁盘, 此时的模型以buffer为中心, 总是保持一个生产者跟一个消费者. 接触过lockfree队列的同学们应该都清楚, 在这种模型下, buffer的push和pop操作都可以做到无锁(这里的无锁是真正的不使用锁操作, 而不是CAS那种无锁).

OK, 似乎胜利的曙光正在向我们靠近, 不过也别高兴的太早, 我们还有一些技术关键点需要克服:
- 多个用户线程push数据, 采用何种方式通知fetcher(这里我暂且将后台取数据的线程叫fetcher), 而且需要做到尽量公平的取走每个buffer中的数据, 而不造成对待不均的问题?
- 当用户线程退出时, 此时thread buffer中还有数据, 何时优雅的释放掉资源?
- 用户线程的buffer queue size是定长还是变长? 如何应对用户线程push log数据速度过快?
对于问题1: 在linux kernel2.6.22之后引入了一个叫做eventfd的feature, 可以使用这个feature为每个用户thread创建一个event fd, 每次push log时对该event fd绑定的value加一即可, 在fethcer中使用epoll/select监控这些event fd, 发生变化时, fetcher即被激活, 并读取活动的event fd中的value, 此时这个value即为要取的message数量. 这样我们是严格按照接到的通知从指定的buffer中读取指定数目的log message, 不会一直读下去(比如读到空为止, 如果这个user thread一直活跃而且拼命的写log, 我们的fetcher就变成他一个人的奴隶了), 这样的方式即可保证更大限度的公平读取.
对于问题2: 如果thread buffer中没有数据, 我们直接释放资源即可, 麻烦就出在如果还有数据的这种情况, 解决方案这里给出2种:
- 增加一个标志位, 如果user thread退出, 这个标志位置true. 接下来我们需要在fetcher中增加一段检测逻辑, 在每次fetch完这个队列给定数目的message后去检查一次这个标志位是否为true并且此时buffer是否为空, 如果标志位为true, buffer也为空, 则可以安全的释放资源.
- 为每种log行为定义一个protocol id, 并放入log message头部中. 比如 id=0 为push log message, id=1 为user thread退出行为, fetcher先取出log message header, 取出这个id就知道接下来要操作的data是何种行为了, 此时如果拿到了id=1的message, 直接释放资源即可. 这种方案也是我选择的方案, 方便定义和扩展其他行为.
流程分析
经过上面的分析, 我们已经知道了具体的模型, 下面还是来看下具体的流程图, 干巴巴的文字始终不如图来的直观.
1. 异步写流程:
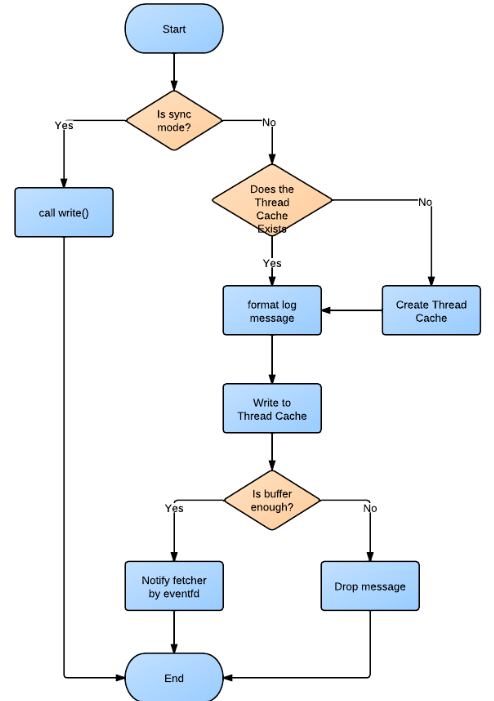
2. Fetcher流程:

这里面一个重要的数据结构即log message. 如下图:

- ID: 1 byte
- Log File Ptr: 4 bytes(in 32bit) / 8 bytes (in 64bit)
- Length: 2 bytes
- Log Message: Length of itself
这里有意思的一个改变就是, 我们像做网络编程一样编写这个日志库, 概念上fetcher好像一个server, user thread作为client, 多个client与server交互通过构造好的protocol. :D
这里或许大家会有疑问, ID只会是一个很小的数据集(当前只用了0和1), 而length又有一个max的limitation为4096 bytes, 所以说ID和Length可以合并在2bytes内, 不过目前这样实现还是出于方便考虑.
测试结果
硬件测试环境:
CPU: Intel Xeon E5645 2.40Gz * 24
MEM: 24G
DISK: 100M+ w/s
程序设置:
Buffer per-thread: 200M, 避免由于buffer满而drop message
Log Message Size: 500 bytes
Total Message : 1,000,000
测试目标: 单纯测试接口调用效率, 如果说因为磁盘瓶颈导致fetcher速度跟不上user push速度, 这又是另外一方面了.
测试结果(图的横轴代表线程数目, 纵轴代表接口调用消耗时间, 越短越好, 单位micro-second):

另外2组数据:
sync writing max speed: 1,549,359 msg/s
sync writing min speed: 493,787 msg/s
async writing max speed: 4,866,937 msg/s
async writing min speed: 1,762,602 msg/s
总体来说, 效果还是很不错的.
ps: 这个测试程序可以做到测试目标机器使用这套log system下的极限异步写入速度(根据fetcher的速度调整, 类似滑动窗口方式调节速率), 以及统计丢失率等.
代码优化
起初刚刚写完的那版效果并不太理想, 经过一步步优化最终还算满意, 简单说说优化的经历. 总体的过程分为2步:
1) 算法/结构/设计上的优化
2) 代码级别的优化
完成第一步, 最重要的就是先找到热点, 下面这张图显示了第一版时的热点所在:
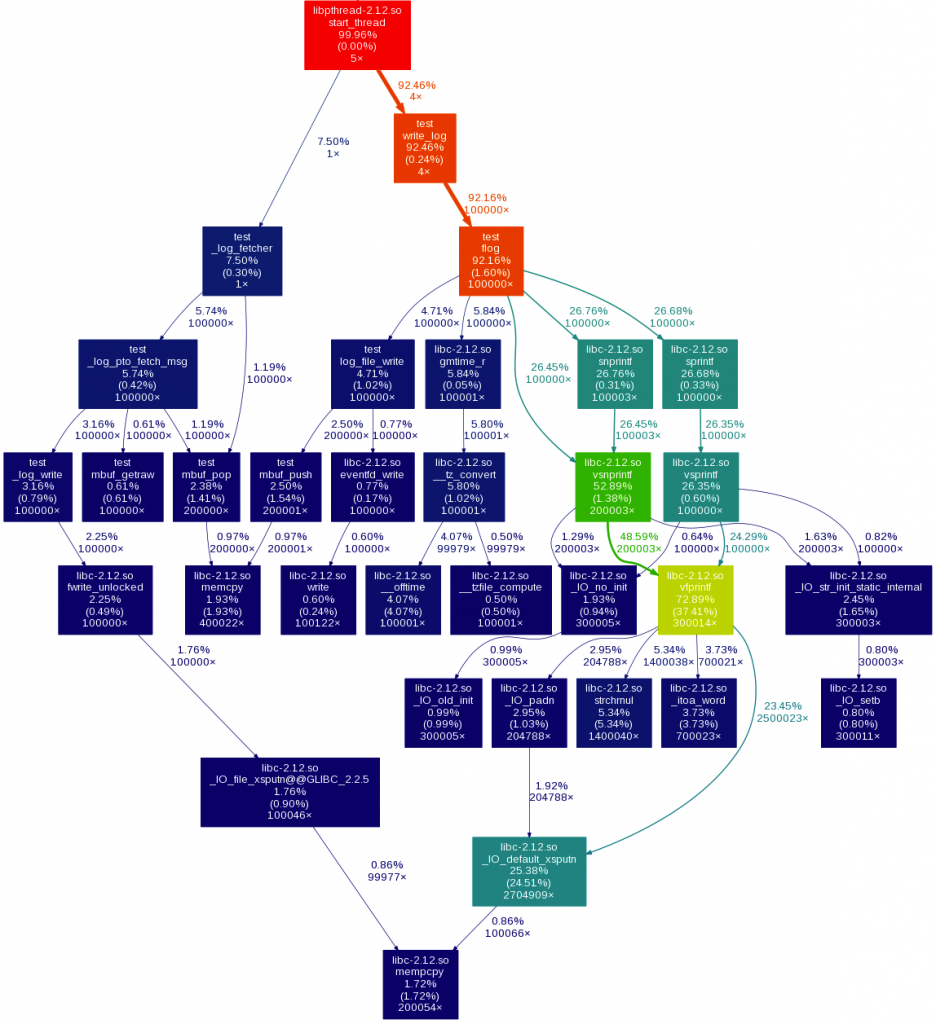
可以看到, 热点在很多次的sprintf, snprintf调用占用了大量时间, 调用这些函数主要做了一些format time和format log message的工作, 减少调用次数将是关键, 目标是合并为一次调用. 通过分析, time在每秒钟内只需format一次, 其他时候直接copy即可. 这样我们只需format一次log message.
经过这种优化再来看看热点图:

现在没有什么主要热点了, 接下来我们开始从code level进行入手. 我们先来看一段引自valgrind document中的话:
On a modern machine, an L1 miss will typically cost around 10 cycles, an LL miss can cost as much as 200 cycles, and a mispredicted branch costs in the region of 10 to 30 cycles. Detailed cache and branch profiling can be very useful for understanding how your program interacts with the machine and thus how to make it faster.
CPU Cache与分支预测的性能损耗值得我们关注, 不过介于CPU Cache的有限, miss的情况必然会发生, 只不过我们根据局部性原理最大限度的利用已经载入Cache的数据即可, 更多不可避免的miss通常也不太好去优化, 不过我这里经验也有限, 暂时也没什么更多可以多聊的, 比较遗憾了. 还是主要集中在分支预测方面给予优化. 所以首先我们需要知道一些事实:
1) 并不是所有的分支都需要动手优化, CPU有自己的预测机制, 通常也都很准确, 已经可以规避大部分miss, 只有小部分会让CPU预测失效
2) 并不是所有靠近if的语句都一定会被编译器安排到靠近if的地方.
3) 即使放在最靠近if地方的语句, 其准确率依然无法保证, 这取决于最终的跳转方式.
基于以上3点, 我们所能做的就是测量哪些是预测失败重灾区, 然后通过优化减少miss. 通常我们有几种solution:
1) 通过table mapping进行跳转优化, 比如将要执行的分支函数都放进一个array中, 根据if的结果直接映射到函数进行跳转. 不过这样的做法会让代码的可读性急剧下降, 零散不堪, 我并不太喜欢这种做法.
2) 通过__builtin_expect提示编译器哪条分支被执行的可能性更大, 编译器会根据该提示将可能性大的分支放在前面, 防止不必要的跳转造成branch miss. 这种手段在kernel中很常见, 我们经常看到的那个likely/unlikely macro就是干这个的. 我比较喜欢这种做法, 可以在不破坏代码结构和逻辑正确性的前提下进行优化.
OK, 我们先起用cachegrind来分析一下cache miss率以及分支预测miss率. 系统调用我们先暂时不去管, 先集中精力看下自己写的code中哪些地方有问题. 通过调用10万次异步写操作观测结果 ( 由于cachegrind生成的结果数据有些多, 我暂时整理出一些重要的 ) 如下所示:
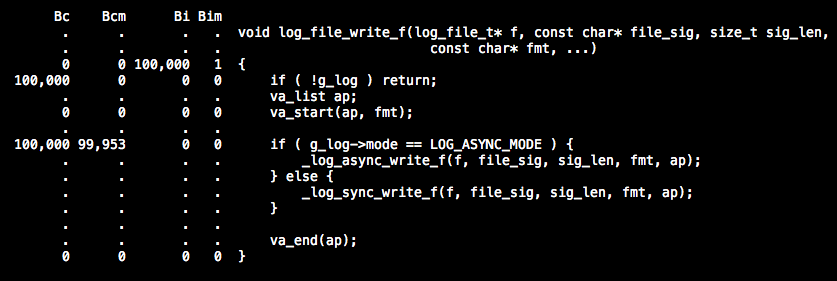
我们发现"if ( g_log->mode == LOG_ASYNC_MODE )" 这句话执行了10万次就有9万多次的branch miss, 但我明明是执行的异步写操作, 而且也将我们认为可能性大的异步调用放在了前面, 可还是出现几乎100%的branch miss, 不禁让人感到奇怪. 原因在哪, 我们通过objdump分析assemble code来看看问题到底出在哪里:

稍微解释下, 第一行就是在判断mode是否等于ASYNC_MODE, 如果是就跳转到1750(_log_async_write_f)去执行_log_async_write_f, 逻辑上来说确实符合我们的希望, 但是结果上来看CPU在这段code上确实失误不少, 并不能准确的判断出跳转到1750的概率更高. 从而导致几乎每次都预测失败并jump走, break了当前流水线.
所以, 我们可以像kernel一样定义2个macros:( 注意在gcc 2.96后才支持)
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
- if ( unlikely( g_log->mode == LOG_SYNC_MODE ) {
- _log_sync_write_f(...);
- } else {
- _log_async_write_f(...);
- }

稍微解释下, 第一行测试一下mode是否为0(即SYNC_MODE的值), 如果成立, 则跳转去执行_log_sync_write_f, 这样会导致break流水线, 不过由于我们是执行异步写操作, 所以这一条不会成立, 进而是后面2条预读的语句总是可以顺利执行, 而后面这2条恰好就是_log_async_write_f函数开始的逻辑, 被编译器直接优化放到这里, 从而做到了减少branch miss. 哈哈, 是不是效果一下子就出来了. 通过cachegrind得到的最终结果, 光这一条改动就减少了0.5%的branch miss. 按照这个思路, 改动几处影响比较恶劣的即可了.
总结
回顾这次coding过程, 不难发现, 单纯比较sync/async接口性能是不一定能说明问题, 单纯从性能来看, sync的接口性能也不一定差, 尤其是在单线程情况下更是不分伯仲, 有时候sync还要比async更快, 那么是什么让我们一定要选择async方式那? 问题就出在磁盘IO的不稳定性上, 尤其是机械硬盘物理上的寻道时间不均, 过热,碎片过多写入效率低下可能导致的卡住一段时间, 如果是sync方式, 这会导致"有可能"block住我们的worker thread, 而一旦出现这种情况, 在生产环境中几乎是0容忍度. 这让我想起了 blocking/non-blocking, sync/async, 我们经常提及的2组词, 但是也经常被我们搞混, sync方式不代表性能一定会很差, 接口一定会是blocking的, 我们一样可以使用non-blocking的方式去操作它, 更好的理解他们, 可能要将这2组词汇分开来看:
blocking/non-blocking意味着接口是否有潜在被block的风险, blocking方式说明一定会存在风险, 但不意味着每次都会出现, 而non-blocking方式则明确表态不会.
而sync/async则代表着处理事务的一种思想, 比如通俗的讲, 交给你一件事情, sync代表在你做这件事的时候我会放下手里的工作, 一直等到你做完为止; 而async代表我告诉你该去做什么后, 我先不去理会你, 该做啥做啥去, 你做完的时候是否通知我, 取决去我的需求.
所以说, 这两种概念有联系, 但也不要简单的混为一滩, 要分开理解对待, 属于两个范畴. 所以sync的方式不一定会慢, 这取决于是否会block, 如果不被block, 通常他会显得更加高效, 而且实现起来也更加清晰, 简单. async方式虽然消除了block带来的影响, 但需要更多的逻辑保证正确性, 多了callback也必然会增加开销, 也导致整体逻辑被拆散, 可读性下降.
综上, 如何取舍, 取决于实际产品, 实际需求, 不可一概而论.
对于这个日志系统, 还是有些不足的, 比如多线程情况下虽然状态稳定, 但却比我的预期要差一点点, 当然, code方面的继续优化还是可以提高表现的, 不过我一直怀疑"伪共享"这种情况在这里到底能产生了多大的影响, 该如何有效测量它, 确是一个让我很好奇的点. 在接下来的工作学习中, 或许可以找到更好的答案. :D
把握每次coding的机会, 点滴进取, 积少成多. :)
- 打造高性能日志系统
- 使用SeasLog打造高性能日志系统
- 用SeasLog打造PHP高性能日志组件
- SeasLog打造PHP项目中的高性能日志组件
- C++ 高性能无锁日志系统
- C++ 高性能无锁日志系统
- 高性能的PHP日志系统 SeasLog
- 高性能PHP日志系统--SeasLog学习
- 如何打造一个高性能、高并发的消息推送系统
- 使用SeasLog打造PHP项目中的高性能日志组件(一)
- 高性能日志服务
- 打造高性能高可靠块存储系统
- strom打造日志处理系统
- 打造基于jQuery的高性能TreeView
- 怎样打造高性能的移动用户体验
- 怎样打造高性能的移动用户体验
- 怎样打造高性能的移动用户体验
- 怎样打造高性能的移动用户体验
- 动态生成html缓存页面
- 文件映射
- OSPF Forward Address Suppressed产生次优路径
- 防盗链
- 面对大公司和小公司,应届毕业生如何选择
- 打造高性能日志系统
- 文件上传、下载
- 安卓系统非常棒终将会统治未来的游戏平台
- code audit读书笔记
- centOS安装wordpress
- C++设计模式之十五--Iterator迭代器模式
- PHP Caching / Cache || FILTERS
- 丑小鸭进化 之 SQL Sever 报错
- Ubuntu 如何获取root权限


