cache 计算关系
来源:互联网 发布:中国物通网靠谱吗 知乎 编辑:程序博客网 时间:2024/05/03 04:15
cache line 计算
1:
一个地址 address = H + M + L = 32位其中,M = 6位,那么M共有2^6 = 64组,取值从0, 1, 2, 3, 4, 5 ... 63。
那么唯一的一个M确定了唯一的cache line .
目前有64路 (64条, 64组, 64 sets) cache line
那么一个地址 a0 = 任意h + m0 ( m0 = 0) + 任意l 将会映射到 cache line 0
那么一个地址 a1 = 任意h + m1 ( m1 = 1) + 任意l 将会映射到 cache line 1
那么一个地址 a2 = 任意h + m2 ( m2 = 2) + 任意l 将会映射到 cache line 2
...
那么一个地址 a62 = 任意h + m62 ( m62 = 62) + 任意l 将会映射到 cache line 62
那么一个地址 a63 = 任意h + m63 ( m63 = 63) + 任意l 将会映射到 cache line 63
2:
对于一个实际的L1 cache (L1 icache / L1 dcache) -- 每个cpu一个H = 20
M = 6
L = 6
L2 cache -- 每个cpu一个
H = 17
M = 9
L = 6
L3 cache -- 所有cpu共享
H = 14
M = 12
L = 6
3:
对于相同的mi, 有2^H种可能映射到同一个cache line那么冲突概率还是挺大的
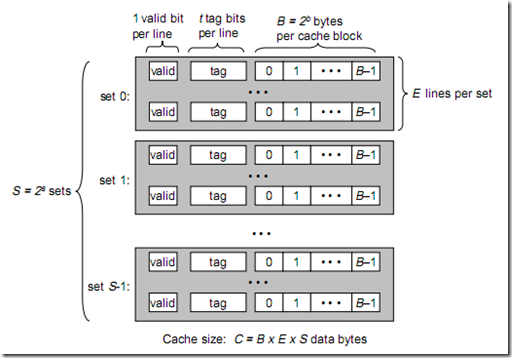
于是每个cache line 增加到E组,也就是每条cache line 有E个备份,冲突概率减小到1/E
实际中
L1 经常是 8 - way
L2 8 - way
L3 12 - way
4:
cache 的size 已经很很大了对于L1, 一路将能达到 4K, 一个page, 8 - way 是 32K
L2, 一路达到 32K, 8 pages, 8 - way = 256 K
L3, 一路达到 256K, 64 pages, 12 -way = 3 M
5:
充分利用cache 能x10倍增加性能
L1 4 周期
L2 10周期
L3 30周期
内存 100周期
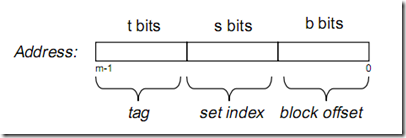
图
t = High
s = Middle
b = Low
E = E
http://www.cnblogs.com/liloke/archive/2011/11/20/2255737.html
cpuID 数据
Processor 1 ID = 0
Number of cores4 (max 8)
Number of threads4 (max 16)
Name Intel Core i5 3470
Codename Ivy Bridge
Specification Intel(R) Core(TM) i5-3470 CPU @ 3.20GHz
Package (platform ID)Socket 1155 LGA (0x1)
CPUID 6.A.9
Extended CPUID6.3A
Core Stepping N0
Technology 22 nm
TDP Limit 77 Watts
Core Speed 1596.3 MHz
Multiplier x Bus Speed16.0 x 99.8 MHz
Stock frequency3200 MHz
Instructions setsMMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, EM64T, VT-x, AES, AVX
L1 Data cache 4 x 32 KBytes, 8-way set associative, 64-byte line size
L1 Instruction cache4 x 32 KBytes, 8-way set associative, 64-byte line size
L2 cache 4 x 256 KBytes, 8-way set associative, 64-byte line size
L3 cache 6 MBytes, 12-way set associative, 64-byte line size
- cache 计算关系
- TLB和cache关系
- 关于Cache的计算
- page cache和buffer cache的关系
- cache后关系型数据库
- TLB和cache的关系
- TLB和cache的关系
- HTTP Cache如何计算Age
- Cache计算的再总结
- Cache缺失率的计算
- 序关系计算问题
- 虚拟内存,MMU/TLB,PAGE,Cache之间关系
- Cache地址与主存地址对应关系
- Cache和主存地址映射关系
- MySQL Query Cache效率的计算
- 关于Cache 计算的出题点
- cache与主存的映射及计算
- Cache与主存地址映像计算
- Linux安装redis 2.6.14
- 使用事件驱动模型实现高效稳定的网络服务器程序
- 图片阴影效果的实现
- 网络流模版(Dinic算法)
- vc动态升级模块的设计与实现[网络中的虚拟实验平台]
- cache 计算关系
- 分析《家园2》《家园》的低效原因
- Tabbar中修改默认tabbaritem选项
- axis2 webservice 调用的三种方式
- 第11周调用函数输出星号图
- i++和++i的区别
- 怎样读好你的研究生?
- 简单模拟Android中AlertDialog的Builder设计模式
- ActiveX交互时浏览器的设置以及ActiveX控件注册的检测


