java数据结构-set
来源:互联网 发布:java web action 编辑:程序博客网 时间:2024/05/22 10:58
Set<String> set = new HashSet<String>(); String a = "1",b = "2",c = "1",d = "3",e = "2"; set.add(a); set.add(b); set.add(c); set.add(d); set.add(e); Iterator it = set.iterator(); while(it.hasNext()){ String s = (String)it.next(); System.out.print(s+","); } System.out.println("一共有对象:"+set.size()+"个"); //打印结果是:3,2,1,一共有对象:3个我们都知道Set是一种最简单的集合,对象的排序无特定的规则,集合里面存放的是对象的引用,所以没有重复的对象,在上面的代码中,程序创建了a、b、c、d、e五个变量,其中a和c,b和e所引用的字符串是一致的,然后向set添加了这5个变量。打印出来的size()只有3个,实际上向集合加入的只有3个对象,在执行Set的add()方法时已经进行了判断这个对象是否存在于集合,如果对象已经存在则不继续执行。
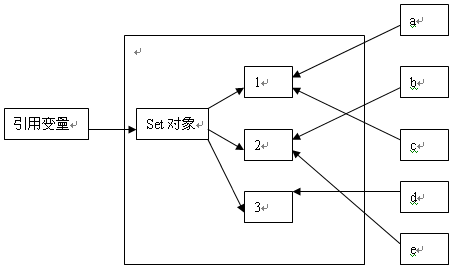
Set的接口有两个实现类,HashSet和TreeSet,HashSet是按照哈希算法来进行存取集合中的对象,存取速度比较快,TreeSet类显示了SortedSet接口,具有排序功能
HashSet
HashSet是按照哈希算法来存取集合中的对象,具有很好的存取和查找性能,当向集合中加入一个对象时,HashSet会调用对象的hashCode()方法来获取哈希码,然后根据这个哈希吗来计算对象在集合中的存放位置。
在Object类中定义了hashCode()和equal(),equal()是按照内存地址比较对象是否相同,如果object1.equal(object1)w为true时,则表明了object1和object2变量实际上引用了同一个对象,那么object1和object2的哈希码也是肯定相同。
稍微的看看HashSet的源码
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { private transient HashMap<E,Object> map; private static final Object PRESENT = new Object(); public HashSet() { map = new HashMap<E,Object>(); } public boolean add(E e) { return map.put(e, PRESENT)==null; } }public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } }
我们会发现我们调用Set的add()方法其实是返回一个transient HashMap.put(e, PRESENT),再跟进HashMap的put(K key, V value)方法进行查看,可以看到int hash = hash(key.hashCode());使用了set.add(key)的key做了一个哈希处理得到一个哈希码,然后再将Entry做了一个遍历,使用equal()方法对讲原有的对象和新添加的对象进行了一个比较,如果出现了true的情况,就直接返回一个oldValue,如果在遍历对比的过程中没有出现ture的情况,则继续一下的步骤modCount++,将对象总数自加,并且继续执行addEntry()的操作,下面涉及HashMap的操作就不继续。
实际上HashSet的底层实现是基于HashMap,所以在此处涉及到Hash算法不展开,详细可以见另一篇《java数据结构-HashMap》
TreeSet
TreeSet类是实现了SortedSet接口,所以能够对集合中的对象进行排序
Set iset = new TreeSet(); iset.add(new Integer(1)); iset.add(new Integer(10)); iset.add(new Integer(5)); iset.add(new Integer(8)); iset.add("2"); Iterator it2 = iset.iterator(); while(it2.hasNext()){ Integer s = (Integer)it2.next(); System.out.print(s+","); } System.out.println("一共有对象:"+iset.size()+"个");//打印出来的结果:1,2,5,8,10,一共有对象:5个
当TreeSet向集合加入一个对象时,会把它插入到有序的对象序列中,TreeSet包括了两种排序方式,自然排序和客户化排序,在默认的情况下使用自然排序。
自然排序
在jdk类库中,有部分类实现了Comparable接口,如Integer,Double等等,Comparable接口有一个compareTo()方法可以进行比较,TreeSet调用对象的compareTo()方法比较集合中对象的大小,然后进行升序排序。如Integer:
public final class Integer extends Number implements Comparable<Integer> { public int compareTo(Integer anotherInteger) { int thisVal = this.value; int anotherVal = anotherInteger.value; return (thisVal<anotherVal ? -1 : (thisVal==anotherVal ? 0 : 1)); } }
基于Comparable的属性,使用自然排序时,只能向TreeSet集合中加入同类型的对象,并且这些对象的类必须实现了Comparable的接口,以下我们尝试向TreeSet集合加入两个不同类型的对象,会发现抛出ClassCastException
Set iset = new TreeSet(); iset.add(new Integer(1)); iset.add(new Integer(8)); iset.add("2");Exception in thread "main" java.lang.ClassCastException: java.lang.Integer
我们再打开TreeSet的源码进行查看
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable { private transient NavigableMap<E,Object> m; private static final Object PRESENT = new Object(); public boolean add(E e) { return m.put(e, PRESENT)==null; } }
NavigableMap为接口,实现类为TreeMap
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable { private final Comparator<? super K> comparator; private transient Entry<K,V> root = null; public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { // TBD: // 5045147: (coll) Adding null to an empty TreeSet should // throw NullPointerException // // compare(key, key); // type check root = new Entry<K,V>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); //此处如果类别不相同可能抛出ClassCastException if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<K,V>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; } }首先判断原始集合是否存在,如果不存在则直接创建,无需比较。
如果原始集合存在的话,先去取出Comparator对象,然后遍历原始集合t,使用parent为临时比较值,逐个使用compare(key, t.key)方法与添加对象key进行比较,决定元素排在集合的left或right。
客户端排序
客户端排序时因为java.util.Comparator<Type>接口提供了具体的排序方式,<Type>指定了被比较对象的类型,Comparator有个compare(Type x,Type y)的方法,用于比较两个对象的大小。
public class NameComparator implements Comparator<Name>{ public int compare(Name n1,Name n2){ if(n1.getName().compareTo(n2.getName())>0) return -1; if(n1.getName().compareTo(n2.getName())<0) return 1; return 0; } public static void main(String[] args) { Set<Name> set = new TreeSet<Name>(new NameComparator()); Name n1 = new Name("ray"); Name n2 = new Name("tom"); Name n3 = new Name("jame"); set.add(n1); set.add(n2); set.add(n3); Iterator it = set.iterator(); while(it.hasNext()){ Name s = (Name)it.next(); System.out.print(s.getName()+","); } System.out.println("一共有对象:"+set.size()+"个"); } }//打印结果是:tom,ray,jame,一共有对象:3个道理与自然排序其实相同,都是通过实现Comparator接口,就不细说了,可能有些说得不对的地方,欢迎指正
- java数据结构-set
- java数据结构-set
- java数据结构-set
- java数据结构-set
- java数据结构02--set
- java数据结构Set与HashSet
- Java数据结构——Set
- JAVA 里的数据结构 Set List Map
- JAVA内置数据结构--set接口与应用
- Java数据结构 List Map Set Collection Collections
- 共同学习Java源代码--数据结构--Set接口
- Java数据结构Collection、Set,List,Map
- Java重要的数据结构Set,List,Map
- Java数据结构之List、Set、Map集合
- Java数据结构详解(五)-Set接口
- java(20):数据结构(3)--Set
- 数据结构-set
- Set数据结构
- 几道笔试题
- Pretree
- PrimeRing
- java数据结构-List
- java数据结构-Comparable&Comparator
- java数据结构-set
- Matrix Factorization(矩阵分解)
- 二进制加法
- 稀疏矩阵
- ireport小试牛刀
- werconcpl.dll加载失败及机箱前耳机插孔故障
- RHCA之学习大纲
- 14-4数组的排序啊
- Data too long for column 'name' at row 1 mysql的抛出异常的解决办法


