adaboost learing
来源:互联网 发布:用c语言输出以下图案 编辑:程序博客网 时间:2024/06/05 10:02
最近在看adaboost,有个ppt讲的不错,将其中重要内容整理一下:
- 1984年Valiant提出PAC(Probably Approximately Correct)学习模型,文中提出强学习和弱学习两个概念。

- 简单的说,
强学习:分类性能强的学习,用强学习得到的分类器称为强分类器。
弱学习:分类性能弱的学习(只比猜测好一点点),用弱学习得到的分类器称为弱分类器。
- Freund的主要贡献:
Freund证明只要足够的数据,就可以通过集成的方式把弱学习转为强学习!
这是一个非常重要的结论,因为:实际运用中,人们根据生产经验可以容易地找到弱学习方法,但是很多情况下要找到强学习方法是很困难的,所以人们常常倾向于找到弱学习然后把它转换为强学习,而Freund证明了这种方式的可行性。
- AdaBoost基本思想
把大量各自“擅长不同领域”的弱分类器线性组合起来,构成一个分类能力很强的强分类器。
弱分类器à专家
所以关键就是:
(1)怎么找到不同领域的专家
AdaBoost通过调整样本权重分布,自动生成不同领域,进而找到专家(弱分类器)。
(2)怎么找到线性组合
AdaBoost根据专家(弱分类器)的错误率大小决定专家意见的采信率(弱分类器权重),把弱分类器线性组合的过程叫提升。
- 如果能找到一种把弱学习转为强学习的“万能”体系,人们就不用为寻找强学习烦恼了!
而Adaboost就是这样一种万能体系!
- 维基百科的算法描述:(copy from wikipedia: http://en.wikipedia.org/wiki/AdaBoost )
Given:
- training set:
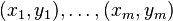 where
where  //m个samples
//m个samples - number of iterations
 //迭代次数T
//迭代次数T
For  :
:
- Initialize
 //初始化权重
//初始化权重
For  :
:
- From the family of weak classifiers ℋ, find the classifier
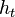 that maximizes the absolute value of the difference of the corresponding weighted error rate
that maximizes the absolute value of the difference of the corresponding weighted error rate 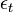 and 0.5 with respect to the distribution
and 0.5 with respect to the distribution  :
:
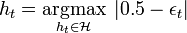
- where
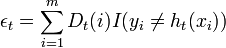 . (I is the indicator function)
. (I is the indicator function)
- If
 , where
, where  is a previously chosen threshold, then stop.
is a previously chosen threshold, then stop. - Choose
 , typically
, typically 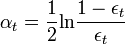 . //计算出来的假设权重
. //计算出来的假设权重 - For :
- Update

- where the denominator,
 , is the normalization factor ensuring that
, is the normalization factor ensuring that  will be a probability distribution.
will be a probability distribution.
Output the final classifier:
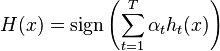
Thus, after selecting an optimal classifier 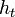 for the distribution
for the distribution 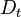 , the examples
, the examples  that the classifier identified correctly are weighted less and those that it identified incorrectly are weighted more. Therefore, when the algorithm is testing the classifiers on the distribution
that the classifier identified correctly are weighted less and those that it identified incorrectly are weighted more. Therefore, when the algorithm is testing the classifiers on the distribution 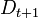 , it will select a classifier that better identifies those examples that the previous classifier missed.
, it will select a classifier that better identifies those examples that the previous classifier missed.
- 而ppt中对这个过程进行了比较简单明了的表述:

- 样本权重分布
不同样本权重分布à不同领域
在某权重分布下具有最小分类错误率的弱分类器à在该领域中的专家
AdaBoost加大被错分的样本权重,减小被正确分类的样本权重,使整个算法“专注”于被错分的样本,找到的具有最小分类错误率的弱分类器,自然是“该领域中的专家”!为什么?
- 目标:最小错误率
样本权重分布被“调整”过,要想达到目标的弱分类器,只能是保证大权重的样本被正确的弱分类器,换言之就是“擅长该领域的专家”。
- 不是对所有专家的意见都采取一样的采信率。分类错误率小的弱分类器权重大,分类错误率大的弱分类器权重小。
- AdaBoost的泛化误差证明比较困难,直到今天也没有一个彻底的公论。但从效果上看,AdaBoost不易过拟合,是一种泛化能力很好的算法。
- Adaboost在人脸检测中的应用:
构造级联分类器:

- 怎么构造级联分类器
关键在于:
(1)设置Node n的目标检测率d和误检率f
(2)训练Node n所用的正样本和训练Node n-1的正样本一样--“正样本一路冲下去”
(3)训练Node n所用的负样本,必须是被前n-1个Node 误检的负样本—“Node n是为不能被前面 n-1个节点正确分类的样本而存在的”

- adaboost learing
- Adaboost
- adaBoost
- adaboost
- Adaboost
- Adaboost
- AdaBoost
- AdaBoost
- AdaBoost
- AdaBoost
- AdaBoost
- AdaBoost
- adaboost
- AdaBoost
- Adaboost
- Adaboost
- AdaBoost
- Adaboost
- 练习:递归求和
- 揭开程序员装 13 行为的面具
- Linux驱动学习8(非阻塞IO的实现--select/poll方法)
- (三)机房收费系统软件需求说明书
- struts2常用标签
- adaboost learing
- 男朋友结婚了新娘不是我
- 模板 STL
- 广播相关汇总
- Android覆盖升级以及apk签名
- android学习——GridView
- 绝不重新定义继承而来的缺省参数值
- C# WinForm多线程---- Control.Invoke
- ant打包时遇到java文件非法字符\65279


