第一届大学生全国数据挖掘邀请赛#的数据集分析
来源:互联网 发布:知豆电动汽车价位 编辑:程序博客网 时间:2024/05/21 16:05
今天下午有点时间,研究了下#第一届大学生全国数据挖掘邀请赛#的数据集,顺便写个酱油贴。
数据集版权归 上海花千树信息科技有限公司 世纪佳缘交友网站 http://www.love21cn.com 所有
此处省略相关废话51句,详细介绍走这边,http://www.statmodelingcompetition.com。
咱们先了解下这次比较的评分标准:
Normalized Discounted Cumulative Gain(NDCG)
有关NDCG评分,具体看这里http://www.statmodelingcompetition.com/explain.html: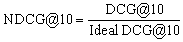
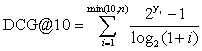
NDCG@10简单来说:
click得1分/msg得2分
取10个你的推荐人(有顺序的哦),对照实际的用户的反馈(rec/click/msg),结合上面的公式,算出你NDCG@10分数。
最理想的情况就是你推荐的每个人,他都发站内消息(注,spammer不算),即NDCG理想得分:1.0,当然这是不可能的,目前排行榜上最高也就.24左右
介绍下下载下来的数据:
data目录:
profile_f.txt,女性会员的资料,203843条数据
profile_m.txt,男性会员的资料,344552条数据
test.txt,
train.txt,原始数据,事实表,格式[USER_ID_A USER_ID_B ROUND ACTION],用户A在第几轮推荐的时候给用户B的反应(不理、点击查看资料、发站内消息)
字段列表.xlsx,这个不要解释,省去废话5字
python目录:(具体看里面的使用方法,这里简单提一下)
evaluate.py,本地计算NDCG分数的脚本
labels_train.txt,由data目录的train.txt数据转换而来,将同一用户的对其他后续人的推荐反馈做的一个聚合,注意,这里已经将推荐轮数给抹掉,分析的时候,推荐轮数可能有点影响。
yourranks.txt,这文件里默认给了一个随机的数据,主要是指导你上传提交的数据格式,每一行,每一列和labels_train.txt的文件里的数据是一一对应的,表示的是labels_train.txt里面的候选人(推荐给用户A的)最合理的推荐顺序(这个其实就是我们需要做的,那个最有可能被用户A看上,当然第一时间推给他,如此。。,注,可能你会奇怪为什么每行的数据不一样,没有办法,因为每一个用户的候选推荐人数列表就是不一样的,有可能是推荐轮数的问题,有可能是给我们的数据的稀疏性造成的,这些都不是问题,只有我们保证前10个,最多20个是非常精确的就行)
使用方法.txt,pass。。。
其实数据挖掘,对数据的理解很重要,并且还需要理解数据之上的业务,然后再建模分析,不断调整优化。
先八卦一下,看哪个人接受的推荐次数最多。
简单对train.txt里面的数据进行处理,得到按推荐次数排序的人员列表:
python脚本:
#!/usr/bin/env pythonfrom operator import itemgetterimport sys word2count={}filehander=open('train.txt')for line in filehander: line=line.strip() word,wordb,count,s = line.split(' ') try: count=int(count) word2count[word]=word2count.get(word,0)+count except ValueError: pass sorted_word2count=sorted(word2count.items(),key=itemgetter(1)) for word,count in sorted_word2count: print '%s\t%s'% (word,count)
结果,按升序:
358896154245813661301360477243198325404442514275226252238146634184503311463---------------此处省略若干行------------3612313652513779908427957062132244836280017566155608361424005893943313202121095690482975971230478713672391291109611642763379051774
找到这条记录:
164276m1216389653129954279719800811333301152240204110910117230111927155168012010333300
参照excel表格,还原下数据,我们来看一下:
Id:164276性别:m注册时间:1216389653(Fri Jul 18 2008 22:00:53 GMT+0800 (China Standard Time))最后登录时间:1299542797(Tue Mar 08 2011 08:06:37 GMT+0800 (China Standard Time))出生年:1980(31岁)生日:0811工作所在地:33(浙江)3301(杭州)征友状态:1(征友进行中)登录次数:5224是否手机验证:0(0:未验证,1:验证,其他,归一化为1,注意这里)学历:20(大专)是否购房:4(独自购房)是否购车:1(暂未购车)婚姻状况:1(未婚)是否有小孩:0(保密,此处有些问题,未婚的一般不会有小孩,处理需注意)职业:9(客户服务/技术支持)照片查看权限:1(所有人可见,这点我觉得权重影响比较大)诚信星标:0(范围:0到5分)民族:1(汉族)身高:172收人:30(5000-1w的区间)是否有头像:1(有,此处需和照片查看权限结合处理)宗教信仰:1(无) 择偶要求最小年龄:19最大年龄:27最低身高:155最高身高:168是否要求星级会员:0(不要求)婚姻状况:1(未婚)学历:20(大专)是否接受更高学历1(ok)是否要求有头像:0(不要求)地区:33浙江子地区:3300
这只是单个的特征而已,只能说明个体,我们要了解整体的情况,这么分析不死人吗,还是先入库吧。
先来Profile表的
CREATE TABLE Profile ( Uid nvarchar(500),sex nvarchar(500),register_time nvarchar(500),last_login nvarchar(500),birth_year nvarchar(500),Birthday nvarchar(500),work_location nvarchar(500),work_sublocation nvarchar(500),STATUS nvarchar(500),login_count nvarchar(500),ms_mobile nvarchar(500),education nvarchar(500),house nvarchar(500),auto nvarchar(500),marriage nvarchar(500),children nvarchar(500),industry nvarchar(500),privacy nvarchar(500),level nvarchar(500),nation nvarchar(500),height nvarchar(500),income nvarchar(500),avatar nvarchar(500),belief nvarchar(500),match_min_age nvarchar(500),match_max_age nvarchar(500),match_min_height nvarchar(500),match_max_height nvarchar(500),match_certified nvarchar(500),match_marriage nvarchar(500),match_education nvarchar(500),match_edu_more_than nvarchar(500),match_avatar nvarchar(500),match_work_location nvarchar(500),match_work_sublocation nvarchar(500) )
导入方法:
sqlserver》建表》数据库右键选择import data》选择数据源:flat file source》选择txt文件》目标表选我们上面定义的表,column自动mapping》导》done
SELECT COUNT(*) FROM [love21cn].[dbo].[Profile] --result-- --548395
其他表类似,建之。。。,典型的星型结构,简单。
入库之后,数据好分析多了,可以发现很多脏数据,需要做些清洗。
先分析下数据吧,看看数据集都有些什么特征:
首先,可以看到,这个数据集都是浙江的会员
地区:浙江、杭州市
分析注册时间(将unixtime转换成datetime):
SELECT DATEADD(s, CONVERT(INT,register_time ), '19700101') AS register_time,DATEADD(s, CONVERT(INT,last_login ), '19700101') AS last_login,* FROM [love21cn].[dbo].[Profile]
截取片段
register_timelast_loginUidsexregister_timelast_loginbirth_yearBirthday2003-10-16 16:00:00.0002003-10-31 16:00:00.0006f10663200001067616000197602022003-10-18 16:00:00.0002004-11-10 16:00:00.00010f10664928001100102400198201012003-10-20 16:00:00.0002005-11-19 09:31:00.00011f10666656001132392660197901012003-10-22 16:00:00.0002011-02-22 14:44:56.00012f10668384001298385896197711152003-10-22 16:00:00.0002004-10-04 16:00:00.00013f10668384001096905600197801012003-10-23 16:00:00.0002009-01-04 10:16:00.00016f10669248001231064160197501012003-10-25 16:00:00.0002004-02-25 16:00:00.00019f10670976001077724800197610222003-10-26 16:00:00.0002004-11-10 16:00:00.00021f10671840001100102400-1-12003-10-29 16:00:00.0002006-09-17 10:19:11.00035f1067443200115848835119760630
从注册时间可以看用户的会员资格,注册时间那么久,还米有找到意中人?神马情况?最后一次登陆时间还是03年,神马意思?
单看上面的数据可以得到一些有用的信息,另外结合评分的数据,创建维度表,根据需要建立各种分析模型,进行分析。
星座,年龄,登陆次数,是否有房,行业。。。这里面大有文章,一个引子,先到这里,希望对你有用。
- 第一届大学生全国数据挖掘邀请赛#的数据集分析
- 数据挖掘 第一课---数据挖掘技术的由来
- 数据挖掘,数据分析
- 数据挖掘,第一面
- 2017年第十届华中地区大学生数学建模邀请赛经典赛B题 基于通讯数据的社群聚类
- 数据分析和数据挖掘的区别
- 数据分析与数据挖掘的区别
- 数据分析与数据挖掘的区别
- 数据挖掘的数据分析方法
- 数据分析、数据挖掘的本质
- 数据分析与数据挖掘的区别
- 数据挖掘的价值:寿险行业数据挖掘应用分析
- 数据挖掘—第一课-知识挖掘的步骤
- 大数据、数据分析、数据挖掘的差别
- 数据挖掘,数据分析好书
- 数据挖掘与数据分析
- 数据分析与数据挖掘
- 数据挖掘与数据分析
- Grails 与 Maven 集成
- 【POJ 1961】
- Highcharts + jQuery + Servlet 实现从后台获取JSON实时刷新图表
- 14周 项目6-字符串操作
- 通常情况下, 多次启动Tomcat或者非正常关闭Myeclipse,但是占用端口的进程没有关闭,也会出现这样的错误。解决方法是关闭javaw.exe进程。
- 第一届大学生全国数据挖掘邀请赛#的数据集分析
- 布尔代数与网页搜索
- UIDynamicItemBehavior-动画效果:增加各种物理特性
- mongodb数据导入导出以及备份恢复
- 不一样的JavaScript(7)——数组
- 轻量级的cookie 插件
- 解决windows输入参数控制台程序输出参数是总是第一个字符问题
- 11.2.0.4 dataguard环境准备
- 修改host脚本


