C++模板学习
来源:互联网 发布:java接口的特点 编辑:程序博客网 时间:2024/04/29 11:44
1. 模板的概念。
我们已经学过重载(Overloading),对重载函数而言,C++的检查机制能通过函数参数的不同及所属类的不同。正确的调用重载函数。例如,为求两个数的最大值,我们定义MAX()函数需要对不同的数据类型分别定义不同重载(Overload)版本。
//函数1.
int max(int x,int y);
{return(x>y)?x:y ;}
//函数2.
float max( float x,float y){
return (x>y)? x:y ;}
//函数3.
double max(double x,double y)
{return (c>y)? x:y ;}
但如果在主函数中,我们分别定义了 char a,b; 那么在执行max(a,b);时 程序就会出错,因为我们没有定义char类型的重载版本。
现在,我们再重新审视上述的max()函数,它们都具有同样的功能,即求两个数的最大值,能否只写一套代码解决这个问题呢?这样就会避免因重载函数定义不 全面而带来的调用错误。为解决上述问题C++引入模板机制,模板定义:模板就是实现代码重用机制的一种工具,它可以实现类型参数化,即把类型定义为参数, 从而实现了真正的代码可重用性。模版可以分为两类,一个是函数模版,另外一个是类模版。
2. 函数模板的写法
函数模板的一般形式如下:
Template <class或者也可以用typename T>
返回类型 函数名(形参表)
{//函数定义体 }
说明: template是一个声明模板的关键字,表示声明一个模板关键字class不能省略,如果类型形参多余一个 ,每个形参前都要加class <类型 形参表>可以包含基本数据类型可以包含类类型.
请看以下程序:
//Test.cpp
#include <iostream>
using std::cout;
using std::endl;
//声明一个函数模版,用来比较输入的两个相同数据类型的参数的大小,class也可以被typename代替,
//T可以被任何字母或者数字代替。
template <class T>
T min(T x,T y)
{ return(x<y)?x:y;}
void main( )
{
int n1=2,n2=10;
double d1=1.5,d2=5.6;
cout<< "较小整数:"<<min(n1,n2)<<endl;
cout<< "较小实数:"<<min(d1,d2)<<endl;
system("PAUSE");
}
程序运行结果:
程序分析:main()函数中定义了两个整型变量n1 , n2 两个双精度类型变量d1 , d2然后调用min( n1, n2); 即实例化函数模板T min(T x, T y)其中T为int型,求出n1,n2中的最小值.同理调用min(d1,d2)时,求出d1,d2中的最小值.
3. 类模板的写法
定义一个类模板:
Template < class或者也可以用typename T >
class类名{
//类定义......
};
说明:其中,template是声明各模板的关键字,表示声明一个模板,模板参数可以是一个,也可以是多个。
例如:定义一个类模板:
// ClassTemplate.h
#ifndef ClassTemplate_HH
#define ClassTemplate_HH
template<typename T1,typename T2>
class myClass{
private:
T1 I;
T2 J;
public:
myClass(T1 a, T2 b);//Constructor
void show();
};
//这是构造函数
//注意这些格式
template <typename T1,typename T2>
myClass<T1,T2>::myClass(T1 a,T2 b):I(a),J(b){}
//这是void show();
template <typename T1,typename T2>
void myClass<T1,T2>::show()
{
cout<<"I="<<I<<", J="<<J<<endl;
}
#endif
// Test.cpp
#include <iostream>
#include "ClassTemplate.h"
using std::cout;
using std::endl;
void main()
{
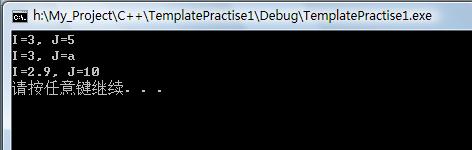
myClass<int,int> class1(3,5);
class1.show();
myClass<int,char> class2(3,'a');
class2.show();
myClass<double,int> class3(2.9,10);
class3.show();
system("PAUSE");
}
最后结果显示:
一般来说,非类型模板参数可以是常整数(包括枚举)或者指向外部链接对象的指针。
那么就是说,浮点数是不行的,指向内部链接对象的指针是不行的。
template<typename T, int MAXSIZE>
class Stack{
Private:
T elems[MAXSIZE];
…
};
Int main()
{
Stack<int, 20> int20Stack;
Stack<int, 40> int40Stack;
…
};
5.使用模板类型
有时模板类型是一个容器或类,要使用该类型下的类型可以直接调用,以下是一个可打印STL中顺序和链的容器的模板函数
template <typename T>
void print(T v)
{
T::iterator itor;
for (itor = v.begin(); itor != v.end(); ++itor)
{
cout << *itor << " ";
}
cout << endl;
}
void main(int argc, char **argv){
list<int> l;
l.push_back(1);
l.push_front(2);
if(!l.empty())
print(l);
vector<int> vec;
vec.push_back(1);
vec.push_back(6);
if(!vec.empty())
print(vec);
}
打印结果

类型推导的隐式类型转换
在决定模板参数类型前,编译器执行下列隐式类型转换:
左值变换
修饰字转换
派生类到基类的转换
见《C++ Primer》([注2],P500)对此主题的完备讨论。
简而言之,编译器削弱了某些类型属性,例如我们例子中的引用类型的左值属性。举例来说,编译器用值类型实例化函数模板,而不是用相应的引用类型。
同样地,它用指针类型实例化函数模板,而不是相应的数组类型。
它去除const修饰,绝不会用const类型实例化函数模板,总是用相应的非 const类型,不过对于指针来说,指针和 const 指针是不同的类型。
底线是:自动模板参数推导包含类型转换,并且在编译器自动决定模板参数时某些类型属性将丢失。这些类型属性可以在使用显式函数模板参数申明时得以保留。
6. 模板的特化
如果我们打算给模板函数(类)的某个特定类型写一个函数,就需要用到模板的特化,比如我们打算用 long 类型调用 max 的时候,返回小的值(原谅我举了不恰当的例子):
template<> // 这代表了下面是一个模板函数
long max<long>( long a, long b ) // 对于 vc 来说,这里的 <long> 是可以省略的
{
return a > b ? b : a;
}
实际上,所谓特化,就是代替编译器完成了对指定类型的特化工作,现代的模板库中,大量的使用了这个技巧。
对于偏特化,则只针对模板类型中部分类型进行特化,如
template<T1, T2>
class MyClass;
template<T1, T2>
class MyCalss<int, T2>//偏特化
7. 仿函数
仿函数这个词经常会出现在模板库里(比如 STL),那么什么是仿函数呢?
顾名思义:仿函数就是能像函数一样工作的东西,请原谅我用东西这样一个代词,下面我会慢慢解释。
void dosome( int i )
这个 dosome 是一个函数,我们可以这样来使用它: dosome(5);
那么,有什么东西可以像这样工作么?
答案1:重载了 () 操作符的对象,因此,这里需要明确两点:
1 仿函数不是函数,它是个类;
2 仿函数重载了()运算符,使得它的对你可以像函数那样子调用(代码的形式好像是在调用比如:
struct DoSome
{
void operator()( int i );
}
DoSome dosome;
这里类(对 C++ 来说,struct 和类是相同的) 重载了 () 操作符,因此它的实例 dosome 可以这样用 dosome(5); 和上面的函数调用一模一样,不是么?所以 dosome 就是一个仿函数了。
实际上还有答案2:
函数指针指向的对象。
typedef void( *DoSomePtr )( int );
typedef void( DoSome )( int );
DoSomePtr *ptr=&func;
DoSome& dosome=*ptr;
dosome(5); // 这里又和函数调用一模一样了。
当然,答案3 成员函数指针指向的成员函数就是意料之中的答案了。
8. 仿函数的用处
不管是对象还是函数指针等等,它们都是可以被作为参数传递,或者被作为变量保存的。因此我们就可以把一个仿函数传递给一个函数,由这个函数根据需要来调用这个仿函数(有点类似回调)。
STL 模板库中,大量使用了这种技巧,来实现库的“灵活”。
比如:
for_each, 它的源代码大致如下:
template< typename Iterator, typename Functor >
void for_each( Iterator begin, Iterator end, Fucntor func )
{
for( ; begin!=end; begin++ )
func( *begin );
}
这个 for 循环遍历了容器中的每一个元素,对每个元素调用了仿函数 func,这样就实现了 对“每个元素做同样的事”这样一种编程的思想。
特别的,如果仿函数是一个对象,这个对象是可以有成员变量的,这就让 仿函数有了“状态”,从而实现了更高的灵活性。
c++模板类
理解编译器的编译模板过程
如何组织编写模板程序
前言
常遇到询问使用模板到底是否容易的问题,我的回答是:“模板的使用是容易的,但组织编写却不容易”。看看我们几乎每天都能遇到的模板类吧,如STL, ATL, WTL, 以及Boost的模板类,都能体会到这样的滋味:接口简单,操作复杂。
我在5年前开始使用模板,那时我看到了MFC的容器类。直到去年我还没有必要自己编写模板类。可是在我需要自己编写模板类时,我首先遇到的事实却是“传统”编程方法(在*.h文件声明,在*.cpp文件中定义)不能用于模板。于是我花费一些时间来了解问题所在及其解决方法。
本文对象是那些熟悉模板但还没有很多编写模板经验的程序员。本文只涉及模板类,未涉及模板函数。但论述的原则对于二者是一样的。
问题的产生
通过下例来说明问题。例如在array.h文件中有模板类array:
// array.h
template <typename T, int SIZE>
class array
{
T data_[SIZE];
array (const array& other);
const array& operator = (const array& other);
public:
array(){};
T& operator[](int i) {return data_[i];}
const T& get_elem (int i) const {return data_[i];}
void set_elem(int i, const T& value) {data_[i] = value;}
operator T*() {return data_;}
};
然后在main.cpp文件中的主函数中使用上述模板:
// main.cpp
#include "array.h"
int main(void)
{
array<int, 50> intArray;
intArray.set_elem(0, 2);
int firstElem = intArray.get_elem(0);
int* begin = intArray;
}
这时编译和运行都是正常的。程序先创建一个含有50个整数的数组,然后设置数组的第一个元素值为2,再读取第一个元素值,最后将指针指向数组起点。
但如果用传统编程方式来编写会发生什么事呢?我们来看看:
将array.h文件分裂成为array.h和array.cpp二个文件(main.cpp保持不变)
// array.h
template <typename T, int SIZE>
class array
{
T data_[SIZE];
array (const array& other);
const array& operator = (const array& other);
public:
array(){};
T& operator[](int i);
const T& get_elem (int i) const;
void set_elem(int i, const T& value);
operator T*();
};
// array.cpp
#include "array.h"
template<typename T, int SIZE> T& array<T, SIZE>::operator [](int i)
{
return data_[i];
}
template<typename T, int SIZE> const T& array<T, SIZE>::get_elem(int i) const
{
return data_[i];
}
template<typename T, int SIZE> void array<T, SIZE>::set_elem(int i, const T& value)
{
data_[i] = value;
}
template<typename T, int SIZE> array<T, SIZE>::operator T*()
{
return data_;
}
编译时会出现3个错误。问题出来了:
为什么错误都出现在第一个地方?
为什么只有3个链接出错?array.cpp中有4个成员函数。
要回答上面的问题,就要深入了解模板的实例化过程。
模板实例化
程序员在使用模板类时最常犯的错误是将模板类视为某种数据类型。所谓类型参量化(parameterized types)这样的术语导致了这种误解。模板当然不是数据类型,模板就是模板,恰如其名:
编译器使用模板,通过更换模板参数来创建数据类型。这个过程就是模板实例化(Instantiation)。
从模板类创建得到的类型称之为特例(specialization)。
模板实例化取决于编译器能够找到可用代码来创建特例(称之为实例化要素,
point of instantiation)。
要创建特例,编译器不但要看到模板的声明,还要看到模板的定义。
模板实例化过程是迟钝的,即只能用函数的定义来实现实例化。
再回头看上面的例子,可以知道array是一个模板,array<int, 50>是一个模板实例 - 一个类型。从array创建array<int, 50>的过程就是实例化过程。实例化要素体现在main.cpp文件中。如果按照传统方式,编译器在array.h文件中看到了模板的声明,但没有模板的定义,这样编译器就不能创建类型array<int, 50>。但这时并不出错,因为编译器认为模板定义在其它文件中,就把问题留给链接程序处理。
现在,编译array.cpp时会发生什么问题呢?编译器可以解析模板定义并检查语法,但不能生成成员函数的代码。它无法生成代码,因为要生成代码,需要知道模板参数,即需要一个类型,而不是模板本身。
这样,链接程序在main.cpp 或 array.cpp中都找不到array<int, 50>的定义,于是报出无定义成员的错误。
至此,我们回答了第一个问题。但还有第二个问题,在array.cpp中有4个成员函数,链接器为什么只报了3个错误?回答是:实例化的惰性导致这种现象。在main.cpp中还没有用上operator[],编译器还没有实例化它的定义。
解决方法
认识了问题,就能够解决问题:
在实例化要素中让编译器看到模板定义。
用另外的文件来显式地实例化类型,这样链接器就能看到该类型。
使用export关键字。
前二种方法通常称为包含模式,第三种方法则称为分离模式。
第一种方法意味着在使用模板的转换文件中不但要包含模板声明文件,还要包含模板定义文件。在上例中,就是第一个示例,在array.h中用行内函数定义了所有的成员函数。或者在main.cpp文件中也包含进array.cpp文件。这样编译器就能看到模板的声明和定义,并由此生成array<int, 50>实例。这样做的缺点是编译文件会变得很大,显然要降低编译和链接速度。
第二种方法,通过显式的模板实例化得到类型。最好将所有的显式实例化过程安放在另外的文件中。在本例中,可以创建一个新文件templateinstantiations.cpp:
// templateinstantiations.cpp
#include "array.cpp"
template class array <int, 50>; // 显式实例化
array<int, 50>类型不是在main.cpp中产生,而是在templateinstantiations.cpp中产生。这样链接器就能够找到它的定义。用这种方法,不会产生巨大的头文件,加快编译速度。而且头文件本身也显得更加“干净”和更具有可读性。但这个方法不能得到惰性实例化的好处,即它将显式地生成所有的成员函数。另外还要维护templateinstantiations.cpp文件。
第三种方法是在模板定义中使用export关键字,剩下的事就让编译器去自行处理了。当我在
Stroustrup的书中读到export时,感到非常兴奋。但很快就发现VC 6.0不支持它,后来又发现根本没有编译器能够支持这个关键字(第一个支持它的编译器要在2002年底才问世)。自那以后,我阅读了不少关于export的文章,了解到它几乎不能解决用包含模式能够解决的问题。欲知更多的export关键字,建议读读Herb Sutter撰写的文章。
结论
要开发模板库,就要知道模板类不是所谓的"原始类型",要用其它的编程思路。本文目的不是要吓唬那些想进行模板编程的程序员。恰恰相反,是要提醒他们避免犯下开始模板编程时都会出现的错误。
//////////////////////////////
http://www.cnblogs.com/xgchang/archive/2004/11/12/63139.aspx
甚至是在定义非内联函数时,模板的头文件中也会放置所有的声明和定义。这似乎违背了通常的头文件规则:“不要在分配存储空间前放置任何东西”,这条规则是为了防止在连接时的多重定义错误。但模板定义很特殊。由template<...>处理的任何东西都意味着编译器在当时不为它分配存储空间,它一直出于等待状态直到被一个模板实例告知。在编译器和连接器的某一处,有一机制能去掉模板的多重定义,所以为了容易使用,几乎总是在头文件中放置全部的模板声明和定义。
为什么C++编译器不能支持对模板的分离式编译
刘未鹏(pongba) /文
首先,C++标准中提到,一个编译单元[translation unit]是指一个.cpp文件以及它所include的所有.h文件,.h文件里的代码将会被扩展到包含它的.cpp文件里,然后编译器编译该.cpp文件为一个.obj文件,后者拥有PE[Portable Executable,即windows可执行文件]文件格式,并且本身包含的就已经是二进制码,但是,不一定能够执行,因为并不保证其中一定有main函数。当编译器将一个工程里的所有.cpp文件以分离的方式编译完毕后,再由连接器(linker)进行连接成为一个.exe文件。
举个例子:
//---------------test.h-------------------//
void f();//这里声明一个函数f
//---------------test.cpp--------------//
#include”test.h”
void f()
{
…//do something
} //这里实现出test.h中声明的f函数
//---------------main.cpp--------------//
#include”test.h”
int main()
{
f(); //调用f,f具有外部连接类型
}
在这个例子中,test. cpp和main.cpp各被编译成为不同的.obj文件[姑且命名为test.obj和main.obj],在main.cpp中,调用了f函数,然而当编译器编译main.cpp时,它所仅仅知道的只是main.cpp中所包含的test.h文件中的一个关于void f();的声明,所以,编译器将这里的f看作外部连接类型,即认为它的函数实现代码在另一个.obj文件中,本例也就是test.obj,也就是说,main.obj中实际没有关于f函数的哪怕一行二进制代码,而这些代码实际存在于test.cpp所编译成的test.obj中。在main.obj中对f的调用只会生成一行call指令,像这样:
call f [C++中这个名字当然是经过mangling[处理]过的]
在编译时,这个call指令显然是错误的,因为main.obj中并无一行f的实现代码。那怎么办呢?这就是连接器的任务,连接器负责在其它的.obj中[本例为test.obj]寻找f的实现代码,找到以后将call f这个指令的调用地址换成实际的f的函数进入点地址。需要注意的是:连接器实际上将工程里的.obj“连接”成了一个.exe文件,而它最关键的任务就是上面说的,寻找一个外部连接符号在另一个.obj中的地址,然后替换原来的“虚假”地址。
这个过程如果说的更深入就是:
call f这行指令其实并不是这样的,它实际上是所谓的stub,也就是一个
jmp 0x23423[这个地址可能是任意的,然而关键是这个地址上有一行指令来进行真正的call f动作。也就是说,这个.obj文件里面所有对f的调用都jmp向同一个地址,在后者那儿才真正”call”f。这样做的好处就是连接器修改地址时只要对后者的call XXX地址作改动就行了。但是,连接器是如何找到f的实际地址的呢[在本例中这处于test.obj中],因为.obj于.exe的格式都是一样的,在这样的文件中有一个符号导入表和符号导出表[import table和export table]其中将所有符号和它们的地址关联起来。这样连接器只要在test.obj的符号导出表中寻找符号f[当然C++对f作了mangling]的地址就行了,然后作一些偏移量处理后[因为是将两个.obj文件合并,当然地址会有一定的偏移,这个连接器清楚]写入main.obj中的符号导入表中f所占有的那一项。
这就是大概的过程。其中关键就是:
编译main.cpp时,编译器不知道f的实现,所有当碰到对它的调用时只是给出一个指示,指示连接器应该为它寻找f的实现体。这也就是说main.obj中没有关于f的任何一行二进制代码。
编译test.cpp时,编译器找到了f的实现。于是乎f的实现[二进制代码]出现在test.obj里。
连接时,连接器在test.obj中找到f的实现代码[二进制]的地址[通过符号导出表]。然后将main.obj中悬而未决的call XXX地址改成f实际的地址。
完成。
然而,对于模板,你知道,模板函数的代码其实并不能直接编译成二进制代码,其中要有一个“具现化”的过程。举个例子:
//----------main.cpp------//
template<class T>
void f(T t)
{}
int main()
{
…//do something
f(10); //call f<int> 编译器在这里决定给f一个f<int>的具现体
…//do other thing
}
也就是说,如果你在main.cpp文件中没有调用过f,f也就得不到具现,从而main.obj中也就没有关于f的任意一行二进制代码!!如果你这样调用了:
f(10); //f<int>得以具现化出来
f(10.0); //f<double>得以具现化出来
这样main.obj中也就有了f<int>,f<double>两个函数的二进制代码段。以此类推。
然而具现化要求编译器知道模板的定义,不是吗?
看下面的例子:[将模板和它的实现分离]
//-------------test.h----------------//
template<class T>
class A
{
public:
void f(); //这里只是个声明
};
//---------------test.cpp-------------//
#include”test.h”
template<class T>
void A<T>::f() //模板的实现,但注意:不是具现
{
…//do something
}
//---------------main.cpp---------------//
#include”test.h”
int main()
{
A<int> a;
a. f(); //编译器在这里并不知道A<int>::f的定义,因为它不在test.h里面
//于是编译器只好寄希望于连接器,希望它能够在其他.obj里面找到
//A<int>::f的实现体,在本例中就是test.obj,然而,后者中真有A<int>::f的
//二进制代码吗?NO!!!因为C++标准明确表示,当一个模板不被用到的时
//侯它就不该被具现出来,test.cpp中用到了A<int>::f了吗?没有!!所以实
//际上test.cpp编译出来的test.obj文件中关于A::f的一行二进制代码也没有
//于是连接器就傻眼了,只好给出一个连接错误
//但是,如果在test.cpp中写一个函数,其中调用A<int>::f,则编译器会将其//具现出来,因为在这个点上[test.cpp中],编译器知道模板的定义,所以能//够具现化,于是,test.obj的符号导出表中就有了A<int>::f这个符号的地
//址,于是连接器就能够完成任务。
}
关键是:在分离式编译的环境下,编译器编译某一个.cpp文件时并不知道另一个.cpp文件的存在,也不会去查找[当遇到未决符号时它会寄希望于连接器]。这种模式在没有模板的情况下运行良好,但遇到模板时就傻眼了,因为模板仅在需要的时候才会具现化出来,所以,当编译器只看到模板的声明时,它不能具现化该模板,只能创建一个具有外部连接的符号并期待连接器能够将符号的地址决议出来。然而当实现该模板的.cpp文件中没有用到模板的具现体时,编译器懒得去具现,所以,整个工程的.obj中就找不到一行模板具现体的二进制代码,于是连接器也黔
/////////////////////////////////
http://dev.csdn.net/develop/article/19/19587.shtm
C++模板代码的组织方式 ——包含模式(Inclusion Model) 选择自 sam1111 的 Blog
关键字 Template Inclusion Model
出处 C++ Template: The Complete Guide
说明:本文译自《C++ Template: The Complete Guide》一书的第6章中的部分内容。最近看到C++论坛上常有关于模板的包含模式的帖子,联想到自己初学模板时,也为类似的问题困惑过,因此翻译此文,希望对初学者有所帮助。
模板代码有几种不同的组织方式,本文介绍其中最流行的一种方式:包含模式。
链接错误
大多数C/C++程序员向下面这样组织他们的非模板代码:
·类和其他类型全部放在头文件中,这些头文件具有.hpp(或者.H, .h, .hh, .hxx)扩展名。
·对于全局变量和(非内联)函数,只有声明放在头文件中,而定义放在点C文件中,这些文件具有.cpp(或者.C, .c, .cc, .cxx)扩展名。
这种组织方式工作的很好:它使得在编程时可以方便地访问所需的类型定义,并且避免了来自链接器的“变量或函数重复定义”的错误。
由于以上组织方式约定的影响,模板编程新手往往会犯一个同样的错误。下面这一小段程序反映了这种错误。就像对待“普通代码”那样,我们在头文件中定义模板:
// basics/myfirst.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
// declaration of template
template <typename T>
void print_typeof (T const&);
#endif // MYFIRST_HPP
print_typeof()声明了一个简单的辅助函数用来打印一些类型信息。函数的定义放在点C文件中:
// basics/myfirst.cpp
#include <iostream>
#include <typeinfo>
#include "myfirst.hpp"
// implementation/definition of template
template <typename T>
void print_typeof (T const& x)
{
std::cout << typeid(x).name() << std::endl;
}
这个例子使用typeid操作符来打印一个字符串,这个字符串描述了传入的参数的类型信息。
最后,我们在另外一个点C文件中使用我们的模板,在这个文件中模板声明被#include:
// basics/myfirstmain.cpp
#include "myfirst.hpp"
// use of the template
int main()
{
double ice = 3.0;
print_typeof(ice); // call function template for type double
}
大部分C++编译器(Compiler)很可能会接受这个程序,没有任何问题,但是链接器(Linker)大概会报告一个错误,指出缺少函数print_typeof()的定义。
这个错误的原因在于,模板函数print_typeof()的定义还没有被具现化(instantiate)。为了具现化一个模板,编译器必须知道哪一个定义应该被具现化,以及使用什么样的模板参数来具现化。不幸的是,在前面的例子中,这两组信息存在于分开编译的不同文件中。因此,当我们的编译器看到对print_typeof()的调用,但是没有看到此函数为double类型具现化的定义时,它只是假设这样的定义在别处提供,并且创建一个那个定义的引用(链接器使用此引用解析)。另一方面,当编译器处理myfirst.cpp时,该文件并没有任何指示表明它必须为它所包含的特殊参数具现化模板定义。
头文件中的模板
解决上面这个问题的通用解法是,采用与我们使用宏或者内联函数相同的方法:我们将模板的定义包含进声明模板的头文件中。对于我们的例子,我们可以通过将#include "myfirst.cpp"添加到myfirst.hpp文件尾部,或者在每一个使用我们的模板的点C文件中包含myfirst.cpp文件,来达到目的。当然,还有第三种方法,就是删掉myfirst.cpp文件,并重写myfirst.hpp文件,使它包含所有的模板声明与定义:
// basics/myfirst2.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
#include <iostream>
#include <typeinfo>
// declaration of template
template <typename T>
void print_typeof (T const&);
// implementation/definition of template
template <typename T>
void print_typeof (T const& x)
{
std::cout << typeid(x).name() << std::endl;
}
#endif // MYFIRST_HPP
这种组织模板代码的方式就称作包含模式。经过这样的调整,你会发现我们的程序已经能够正确编译、链接、执行了。
从这个方法中我们可以得到一些观察结果。最值得注意的一点是,这个方法在相当程度上增加了包含myfirst.hpp的开销。在这个例子中,这种开销并不是由模板定义自身的尺寸引起的,而是由这样一个事实引起的,即我们必须包含我们的模板用到的头文件,在这个例子中是<iostream>和<typeinfo>。你会发现这最终导致了成千上万行的代码,因为诸如<iostream>这样的头文件也包含了和我们类似的模板定义。
这在实践中确实是一个问题,因为它增加了编译器在编译一个实际程序时所需的时间。我们因此会在以后的章节中验证其他一些可能的方法来解决这个问题。但无论如何,现实世界中的程序花一小时来编译链接已经是快的了(我们曾经遇到过花费数天时间来从源码编译的程序)。
抛开编译时间不谈,我们强烈建议如果可能尽量按照包含模式组织模板代码。
另一个观察结果是,非内联模板函数与内联函数和宏的最重要的不同在于:它并不会在调用端展开。相反,当模板函数被具现化时,会产生此函数的一个新的拷贝。由于这是一个自动的过程,编译器也许会在不同的文件中产生两个相同的拷贝,从而引起链接器报告一个错误。理论上,我们并不关心这一点:这是编译器设计者应当关心的事情。实际上,大多数时候一切都运转正常,我们根本就不用处理这种状况。然而,对于那些需要创建自己的库的大型项目,这个问题偶尔会显现出来。
最后,需要指出的是,在我们的例子中,应用于普通模板函数的方法同样适用于模板类的成员函数和静态数据成员,以及模板成员函数。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/look01/archive/2008/11/05/3228134.aspx
浅谈C++模板机制
一、 什么是模板?
1. 模板(Template)可以看做成对于某一类问题一种通用的解决方案,而实现的具体细节则需要根据实际问题对模板做出调整和优化。
2. 如我们在使用Word进行文档处理时,模板决定了文档的基本结构和文档的设置,如果你想要某种风格的文档结构,你可以对模板进行修改。模板提供了更加通用、灵活的解决方案。
3. 在C++中,模板是泛型编程的基础,是创建类和函数的蓝图或公式。
二、 从函数模板谈起
1. 从一个实例出发
假设我们想设计一个函数根据输入参数的类型来返回这个参数的绝对值,如果按照C语言的做法,我们会设计如下几个函数:
int fabsInt(int arg);
double fabsDouble(double arg);
float fabsFloat(float arg);
这样设计出的三个函数虽然函数定义不同,但是完成的功能却是相同的,这样的设计比较麻烦。C++提供了函数模板使得这一问题的解决方案更加通用、灵活。
源代码:
template<typename T>
T fabs(T arg)
{
return arg>0?arg:(-arg);
}
测试:
inta;
doubleb;
floatc;
cout<<"a=";
cin>>a;
cout<<"b=";
cin>>b;
cout<<"c=";
cin>>c;
cout<<"|"<<a<<"|"<<"="<<fabs(a)<<endl;
//执行int fabs(int arg)
cout<<"|"<<b<<"|"<<"="<<fabs(b)<<endl;
//执行double fabs(double arg)
cout<<"|"<<c<<"|"<<"="<<fabs(c)<<endl;
//执行float fabs(float arg)
这样编译器在编译的时候就可以根据传送的参数类型实例化某个函数执行。
1. 定义函数模板的注意事项:
(1)函数模板是一个独立于类型的函数,可以看做一种通用的功能;
(2)模板定义必须以template开始,之后接模板的形参列表且此列表不能为空;
(3)可用typename或class定义模板的类型,两者没有区别。
2. 模板形参的注意事项:
(1)模板形参遵循名字屏蔽规则,如下例:
typedef int T; //T是全局作用域
template<class T> // 此时的T是局部作用域,它屏蔽了全局的T
void fun(constT& val)
{
T temp=val;
//此时temp的类型是具有局部作用域的T,并非int类型
//Todo something
}
(2) 模板的类型不能重复定义,如下例:
template<classT, class T> / /T重复定义
//编译器报错:error C2991: redefinition of template parameter 'T'
void fun(constT& val)
{
T temp=val;
//Todo something
}
3. 实例化
(1)模板实参的推断
在使用函数模板时,编译器通常会自动推断出模板实参,如以上求绝对值的例子。
(2)实例化时形参、实参类型必须匹配
template<typenameT>
T compare(constT& a,const T& b) //此模板函数返回a, b的最大值
{
return a>b?a:b;
}
void main()
{
int a=1;
double b=3;
cout<<compare(a,b); //类型不匹配
//编译器报错:
//error C2782: 'T__cdecl compare(const T &,const T &)' : template parameter 'T' isambiguous
}
原因分析:此模板只有一个类型T,在编译时,编译器最先遇到的实参是a,类型是整型,编译器就将该模板形参解释为整型,此后出现的形参b不能被解释成整型,所以编译器报错。
解决方案一:强制类型转换
cout<<compare(a,int(b));
//将变量b强制转换为整型,但转换后精度损失
或:
cout<<compare(double(a),b);
//此时整型变量a会提升为double型,精度不会损失
解决方案二:修改函数模板
但这样做,可能会违背函数模板设计的初衷,所以我们在使用函数模板时,最好做到形参、实参类型完全匹配。
(3)实例化与函数指针的确定
在C/C++语言中,函数名代表函数的入口地址,那么我们可以将这个地址放在一个指针变量中,这个指针变量就是指向函数的指针,如下代码:
int add(int a, int b); //返回a, b之和
int (*ptrfun)(int a, int b); //ptrfun是指向函数的指针
ptrfun=add; //赋值
ptrfun(1,3); //调用
或者以另一种形式赋值:
int (*ptrfun)(int a, int b)=add;
这里我们写了一个关于加法的函数模板:
template<typename T>
T add(const T &a, const T &b)
{
return a+b;
}
int (*pfun)(const int &a ,const int &b)=add;
//此时编译器在会以整型来实例化函数模板
如果编译器不能从函数指针类型(如上例中的函数指针所指函数有整型参数)推断出函数模板的类型,那么编译器就会报错。如下例:
template<typename T>
T add(const T &a, const T &b)
{
return a+b;
}
//定义重载函数func,注意此这两个func函数的参数分别是指向不同函数的指针
void func(int (*)(const int&, const int&));
//指向两个整型数相加函数
void func(string (*)(const string&, conststring&));
//指向两个字符串连接函数
func(add); //编译器报错
//error C2668: 'func' : ambiguous call to overloadedfunction
原因分析:当执行func(add)时,要进行参数传递,相当于
func=add,此时的func有两种类型,编译器无法推断出模板函数add的类型,所以编译器报错。
4. 函数模板的显式实参的探讨
(1)假如我们想设计一个加法函数模板,函数模板的参数类型可以不同,但返回类型应该是参数类型的最高类型,如
template<typename T1,typename T2>
? add(const T1 &a, const T2 &b);
现在的问题是函数模板add的返回类型是什么?
假如 int a=1; double b=2.11; add(a, b);
我们希望add返回double类型
解决方案:重新定义模板
template<typenameT1,typename T2,typename T3>
T1 add(const T2&a,const T3 &b)
{
return a+b;
}
但此时会出现问题,那就是编译器无法推断出T1的类型,解决方法很简单,我们写下如下代码:

cout<<add<double>(1,2.111)<<endl;
按照以上的提示,输入“<”后第一个类型就是我们希望函数模板返回的类型T1,其他两个是参数类型,可以省略不写,编译器会根据后面实参的类型来推断形参的类型。
(2)解决以上指向函数的指针二义性的方案
void func(int(*)(const int&, const int&));
void func(string(*)(const string&, const string&));
func(add); //编译器报错
解决方案:显式指定实参,如下代码所示
template<typenameT>
T add(const T&a, const T &b)
{
return a+b;
}
void func(int(*ptrfun)(const int& a, const int& b),const int& a, const int&b) //后面两个参数的声明必须写
{
ptrfun=add<int>;
cout<<ptrfun(a,b)<<endl;
}
void func(string(*ptrfun)(const string& a,const string& b),const string& a,conststring& b)
{
ptrfun=add<string>;
cout<<ptrfun(a,b)<<endl;
}
void main()
{
func(add,1,2);
func(add,"hello","world");
}
5. 函数模板与重载函数的探讨
代码实例如下:
int add(int a, intb)
{
cout<<"调用 int add(int a, int b)"<<endl;
return a+b;
}
double add(doublea, double b)
{
cout<<"调用 void fun(double a, double b)"<<endl;
return a+b;
}
template<typename T>
T add(T a,T b)
{
cout<<"调用模板函数"<<endl;
return a+b;
}
在上面的代码中,我们写了三个重载的函数,其中有一个是函数模板,这三个函数都是完成返回两个加数的和。但这样的代码在调用时很容易出错,
cout<<add(1,2);
//绝对匹配,调用int add(int a, int b)
cout<<add(1.0,2.0);
//绝对匹配,调用double add(double a, double b)
cout<<add(1.0,2);//编译器报错
//error C2782: 'T__cdecl add(T,T)' : template parameter 'T' is ambiguous
原因分析:编译器在编译第一、二行代码的时候,能够找到与实参绝对匹配的函数,编译通过,但是编译器在编译第三行代码的时候,它会做出如下检查:
第一步,编译器会找寻有没有与实参绝对匹配的函数,发现没有;
第二步,编译器会找寻能够实例化的函数模板,因为源代码的模板只有一个类型T,而实参提供了两种类型,所以,编译器找不到能够实例化的函数模板。
解决方案:强制类型转换
cout<<add(1.0,static_cast<double>(2));
或cout<<add(static_cast<int>(1.0),2);
在此,当代码中出现重载、函数模板时,我们总结下编译器选择的次序:
(1)选择与实参完全匹配的函数;
(2)选择能够根据实参类型推断出形参的函数模板并实例化;
(3)选择能够根据实参进行隐式转换的函数。
其实第三步一些编译器不支持,如VC6.0
三、 有关类模板的探讨
有了以上对函数模板的认识,我们对类模板的理解就会比较容易了。就像函数模板一样,我们可以把类模板理解为具有一定类型的类(不要与抽象类混淆),而这种类要根据类型来实例化,以完成特定的功能。
从一个有关链表的例子讲解
链表的操作也许我们并不陌生,在C语言中,我们就学习过了,但那时的链表要想实现通用的效果,我们往往在代码中写下如下的语句:typedef int ElemType; 这样我们要想创建一个double类型的链表,只需要修改int为double即可。现在我们用C++的类模板来写一个双向循环链表程序,代码如下所示:
#include <iostream>
#include <cstdlib>
using namespace std;
template<class T>
class DLNode //结点类
{
public:
T data; //数据域
DLNode<T>*lLink; //前驱指针域,指向当前结点的直接前驱
DLNode<T>*rLink; //后继指针域,指向当前结点的直接后继
DLNode(DLNode<T>* left=0,DLNode<T>* right=0):lLink(left),rLink(right)
{
}
DLNode(const T& val,DLNode<T>* left=0,DLNode<T>* right=0)
{
data=val;
lLink=left;
rLink=right;
}
};
const int Max=100;
template<class T>
class DList //双向循环链表类
{
private:
DLNode<T>* head; //头指针
public:
DList()
{
head=0;
}
DList(int N) //N表示要构造的链表长度
{
if(N<=0 || N>Max)
{
cerr<<"参数不合法!"<<endl;
exit(1);
}
head=new DLNode<T>; //生成头结点
DLNode<T>* p;
DLNode<T>* current=head;
int i;
T data;
for(i=0;i<N;i++)
{
cout<<"请输入第"<<i<<"个数据:";
cin>>data;
if(!cin.good())
{
cerr<<"输入不合法!"<<endl;
exit(1);
}
p=new DLNode<T>(data); //生成一个新的结点
current->rLink=p;
p->lLink=current;
current=p;
}
current->rLink=head;
head->lLink=current;
}
bool IsEmpty() const
{
return head==0 || head->rLink==head || head->lLink==head;
}
void Print() const //打印链表
{
if(IsEmpty()) return;
for(DLNode<T>* p=head->rLink;p!=head;p=p->rLink)
{
cout<<p->data<<" ";
}
cout<<endl;
}
int Length() const
{
DLNode<T>*p;
int n=0;
if(IsEmpty()) return 0;
for(p=head->rLink;p!=head;p=p->rLink)
{
n++;
}
return n;
}
DLNode<T>* Search(const T& val) //查找val,函数返回指向val结点的指针
{
DLNode<T>* p;
if(IsEmpty()) return 0;
p=head->rLink;
while(p->data!=val && p!=head) p=p->rLink;
if(p==head) return 0;
else return p;
}
DLNode<T>* Search(int pos) //按元素的位置进行查找
{
if(IsEmpty()) return 0;
if(pos<0)
{
cerr<<"参数错误!"<<endl;
return 0;
}
int i=0;
DLNode<T>* p=head->rLink;
while(i<pos && p!=head)
{
i++;
p=p->rLink;
}
return p;
}
void Insert(int pos,const T &val) //在指定的位置pos后插入值为val的结点
{
if(IsEmpty()) return;
DLNode<T>* p=Search(pos); //寻找插入位置的指针
if(!p) return; //找不到则返回
DLNode<T>* q=new DLNode<T>(val); //q指向要插入的结点
if(!q) return; //存储空间不足则返回
q->rLink=p->rLink; //进行后插
q->lLink=p;
p->rLink->lLink=q;
p->rLink=q;
}
void Removw(int pos,T& val) //移除位置pos的结点,val带回此结点的元素值
{
if(IsEmpty()) return;
DLNode<T>* p=Search(pos); //寻找删除位置的指针
if(!p) return; //找不到则返回
p->lLink->rLink=p->rLink;
p->rLink->lLink=p->lLink;
val=p->data;
delete p;
}
};
测试:
DList<int>L(3); //定义链表
注意:将类模板实例化时,必须提供类型
cout<<L.Length(); //输出链表的长度
int a;
cin>>a;
DLNode<int>*p=L.Search(a); //查找a
cout<<p->data<<endl;
L.Insert(2,18); //在链表的第2个位置后插入18
L.Print();
L.Removw(3,a); //删除链表第3个位置处的结点
L.Print();
在上面的实例代码中,我们将类模板的声明和定义放在同一个cpp文件中。但有时代码量很大时,我们将类模板的声明放在头文件,而实现则放在cpp文件中,如果是这样做,我们的代码就要写成下面的形式:
template<class T> //此行必须要写
bool DList<T>::IsEmpty() const //类型T不能丢失
{
returnhead==0 || head->rLink==head || head->lLink==head;
}
- C++template ;模板学习
- 学习C++模板---模板函数
- C/C++学习之模板
- 学习C++模板---模板类带简单参数
- 学习C++模板---模板类作为基类
- C++primer学习:模板编程(2):类模板的定义
- C++primer学习:模板编成(5):模板实参推断{1}
- C++primer学习:类模板(2)类模板:模板参数,成员模板和控制实例化
- C++Template学习笔记之函数模板
- C/C++学习----第五章 模板
- C++模板 学习要点
- (C/C++学习笔记)函数模板加强
- C++primer学习:模板编程(4)
- C++Primer学习:模板特例化
- STL模板学习之set容器(C/C++)
- 学习C++模板---模板类带简单参数,并且添加缺省参数,特例模板
- C++primer学习:类模板(1):函数模板,模板参数,实例化
- C++-模板
- AJAX ASP.NET ashx用法
- 厨房用具,将吸目无背无侧旁
- Bug管理系统UML2.0建模实例(三)
- Opencv2系列学习笔记10(提取连通区域轮廓)
- 黑马程序员_温习 IO流四 (个人笔记)摘要(打印流PrintWriter(Stream)---序列流SwquenceInputStream----对象流ObjectInputStream(Outp
- C++模板学习
- rotate-list
- Linux磁盘系统基础知识
- vc将彩色图像转换为灰度图像
- 黑马程序员_温习 IO流五 (个人笔记)摘要(字符编码)
- 内核中与驱动相关的内存操作之一(MMU)
- NYOJ 67 三角形面积
- 二进制的表白
- AS3 对JSON的读取和发送


