希尔排序
来源:互联网 发布:未来软件txt下载 编辑:程序博客网 时间:2024/05/16 09:45
算法分析
希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比o(n^2)好一些。由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
优劣
希尔排序是一种按照增量排序的方法。其中增量值是小于n的正整数。
shell排序的基本思想[1]是:
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
可以根据百度百科中提供的图来直观的看一下:
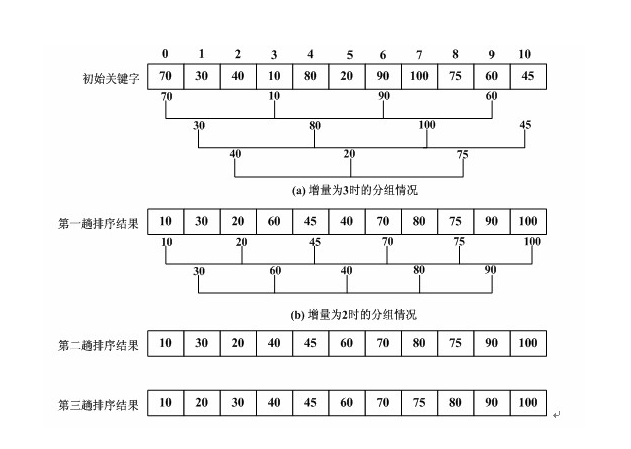
(1)初始增量为3,该数组分为三组分别进行排序。(初始增量值原则上可以任意设置(0<gap<n),没有限制)
(2)将增量改为2,该数组分为2组分别进行排序。
(3)将增量改为1,该数组整体进行排序。
#include<stdio.h>
void main()
{
void shell_sort(int a[], int n) ;
int a[10] ={1,9,3,5,2,8,6,7,0,4};
shell_sort(a,10);
}
void shell_sort(int *x,int n)
{
int h,j,k,t;
for(h=n/2;h>0;h=h/2)/*控制增量*/
{
for(j=h;j<n;j++)/*这个实际上就是直接插入排序*/
{
t=*(x+j);
for(k=j-h;(k>=0 && t<*(x+k)); k-=h)
{
*(x+k+h)=*(x+k);
}
*(x+k+h)=t;
}
}
for(t =0;t<10;t++)
printf("%d ",*x++);
}
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- JavaScript高级程序设计 DOM事件处理 读书笔记
- 计算机核心期刊排名
- Spring3.0 入门进阶(3):基于XML方式的AOP使用
- JMS基础 - 精华版
- Java程序栈信息文件中的秘密(一)
- 希尔排序
- CUSTOM.PLL的使用
- 如何创建自己的库(Jar包)?
- dos基本命令
- Apache与Nginx网络模型
- Jquery mobile 总结(一)
- Oracle 中大数据的处理
- 收縮日誌文件無效?
- 解析XML的几种方式


