linux的配置接口-netlink原理和设计
来源:互联网 发布:js中冒号的作用 编辑:程序博客网 时间:2024/05/16 05:39
refer from http://blog.csdn.net/dog250/article/details/6425664
linux内核是可配置的,配置的方式有好多种呢!对于linux平台上上的开发者和管理员来讲,这几种配置方式可困扰了不少人儿。这里的配置不是指运行中的内核动态的配置,而是指当有新的设备或者内核特性添加进内核的时候,用户需要进行的配置。本文主要列举三种配置方式,最终落实于netlink方式的配置。
1.传统方式
传统方式一般认为是使用ioctl或者系统调用的方式,如果使用ioctl,当我们为设备驱动或者内核本身增加一个新的配置时,需要增加一个新的ioctl命令,这就可能就要修改ioctl的分发代码,类似于为芯片增加一个功能需要增加一个引脚且新布一根线一样,如果使用系统调用的方式,当既有的系统调用无法满足我们的需求时,我们就不得不增加一个新的系统调用,这就意味着需要重新编译内核代码。
2.procfs和sysfs的方式
这两种方式基于文件系统,所有的配置都可以通过文件读写接口完成,主谓宾(定状补最为参数和约束)的配置方式需要操作者记住诸多的选项参数,而sysfs通过文件名(kobject的属性)代替了诸多的选项参数,诸多选项参数需要另一个额外的参数“-h/--help”来展示,而sysfs的方式只要要记住ls命令即可,通过ls列出的文件代表kobject的属性,一般而言,一个好程序员会将-h选项参数所展示的帮助信息体现在文件名上!
然而你增加一个新配置的时候,意味着在去除这个新配置之前,procfs或者sysfs中会永久性的增加一个新的文件或者目录,这样会导致procfs和sysfs的膨胀,还容易引起程序员/管理员的误解,平添了复杂性,再者,即使增加一个再简单不过的配置,你也不得不实现一个proc的entry或者一个kobject(或者其attribute),而对于很多人,这并不是一件容易的事!
3.netlink的方式
netlink机制是一种最适宜的方式,在接口上,它使用socket,很简单,在实现上,它不依赖任何其它的内核业务组件,类似一个扩展的支持多点对多点的管道,在这种管道的任何一端,你都可以随意的加入自己的处理逻辑,形成一条自适应,自给自足的带有端点的通用链路。除了在通信过程中,其余任何时候,netlink都不会在内核中留下任何足迹,除非你想留下!比如一个简单的例子,一个用户进程想告诉内核“XX hello world”,那么它将通过netlink将XX hello world写入内核,然后内核收到之后会根据XX来处理之,如果XX是print的话,那么内核将输出一条hello world,如果XX为laugh at的话,内核将嘲笑你一番,因为你是个菜鸟,或者将hello world发给其它进程也是可以的!完成XX之后,这件事将不留下任何痕迹。
除了在内核态和用户态之间架设了一条通用的链路之外,如果你不希望,netlink不在任何位置留下任何信息。
netlink一般被理解为“内核态和用户态通信的接口”,然而它也可以用作进程间通信的接口,并且这种进程间通信可以基于组而不是基于进程的pid。典型的例子就是设置路由以及其它网络协议栈参数的iproute2工具链,其完全是基于netlink实现的,也就是说你在其源代码中再也看不到诸如ioctl之类的系统调用了。
netlink在使用方面的优势在于其简单性,在设计上的精华在于它的“软化”,还记得软化是什么意思吗?就是将复杂的控制逻辑集中在通信实体的两端而不是链路上,关于软化,典型的例子一般都来自于硬件链路的设计,比如并行链路发展为串行链路,链路本身不再约束任何通信协议相关的控制逻辑,而将控制逻辑集中在链路两端的芯片中,比如串行链路使用帧来传输协议pdu,协议相关的控制全部又帧的格式决定,以往在并行链路上,协议控制逻辑是由链路而不是帧决定的,比如“第x根线路代表数据准备好,第y根线传输同步信息”等。对于netlink而言,其设计十分类似于这种出自于硬件的“软化”思想,不再需要特定的ioctl来实现控制,而将控制集中在netlink套结字的发送和接收端,发送和接收端之间的“netlink链路”对传输的信息还不知情,它仅仅负责传输!
毫不夸张的说,有了netlink,就可以去除一切系统调用了,这里我们把系统调用比喻成“硬连线”的逻辑,每一根或者几根线完成一个特定的控制逻辑,而netlink作为一个“串行的,软化”的逻辑,只在链路上传输“帧”,只在发送方和接收方处理控制逻辑。使用netlink的方式,操纵系统接口的可扩展性将大大增强。
我们可以把操作系统分为若干个模块,大的方面说可以分为:用户空间/内核空间。其中用户空间又可以根据应用分为若干组,同理内核空间也是如此,可以看出,这就是完全基于消息的接口方式,所有消息通过netlink传输,并且,可以超级简单的实现消息的路由和中转,基于中转机制,甚至用户空间进程的IPC都可以完全使用netlink机制。如下图: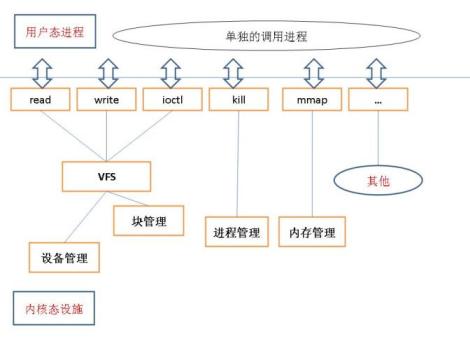
以上为传统的方式
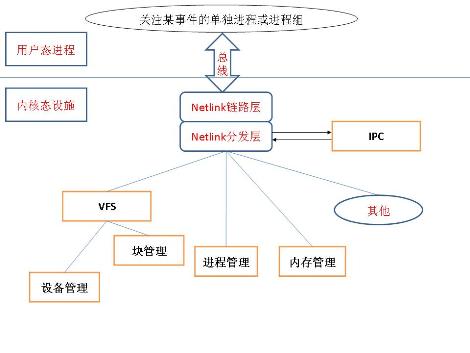
以上为本文预测的netlink方式
使用netlink完成系统调用可以很简单的做到AIO,这完全交给socket来做即可,通过设置socket的block状态即可。比如用户执行一个同步的read调用,需要生成一个netlink套结字,然后设置成阻塞模式,然后通过send发送一个read消息后,recv内核的返回,read消息中包含需要读取的文件的描述符,offset,大小等信息,recv参数中包含用户缓冲区信息...如果执行一个异步的read调用,通过send发送了read消息之后,直接返回,在另一个帮助线程中recv返回后通知主线程即可...
光说不练假把式,为了能说明问题,这里举出一个最简单的例子,这就是使用netlink机制替代发送信号的系统调用kill,内核模块源码如下:
- #include <linux/module.h>
- #include <linux/netlink.h>
- #include <linux/sched.h>
- #include <net/sock.h>
- #include <linux/proc_fs.h>
- #include <asm/siginfo.h>
- #include <linux/signal.h>
- static struct sock *netlink_kill_sock;
- static int flag = 0;
- struct sig_struct_info {
- int pid;
- int sig
- };
- static DECLARE_COMPLETION(exit_completion);
- static void recv_handler(struct sock * sk, int length)
- {
- wake_up(sk->sk_sleep);
- }
- static int process_message_thread(void * data)
- {
- struct sk_buff * skb = NULL;
- struct nlmsghdr * nlhdr = NULL;
- int len;
- DEFINE_WAIT(wait);
- struct sig_struct_info sigi;
- struct siginfo info;
- daemonize("netlink-kill");
- while (flag == 0) {
- prepare_to_wait(netlink_kill_sock->sk_sleep, &wait, TASK_INTERRUPTIBLE);
- schedule();
- finish_wait(netlink_kill_sock->sk_sleep, &wait);
- while ((skb = skb_dequeue(&netlink_kill_sock->sk_receive_queue)) != NULL) {
- struct task_struct *p;
- nlhdr = (struct nlmsghdr *)skb->data;
- len = nlhdr->nlmsg_len - NLMSG_LENGTH(0);
- memset(&sigi, 0, sizeof(struct sig_struct_info));
- memcpy(&sigi, NLMSG_DATA(nlhdr), len);
- info.si_signo = sigi.sig;
- info.si_errno = 0;
- info.si_code = SI_USER;
- info.si_pid = current->tgid;
- info.si_uid = current->uid;
- p = find_task_by_pid(sigi.pid);
- if (p)
- force_sig_info(sigi.sig, &info, p);
- }
- }
- complete(&exit_completion);
- return 0;
- }
- static int __init netlink_kill_init(void)
- {
- netlink_kill_sock = netlink_kernel_create(111, recv_handler);
- if (!netlink_kill_sock) {
- return 1;
- }
- kernel_thread(process_message_thread, NULL, CLONE_KERNEL);
- return 0;
- }
- static void __exit netlink_kill_exit(void)
- {
- flag = 1;
- wake_up(netlink_kill_sock->sk_sleep);
- wait_for_completion(&exit_completion);
- sock_release(netlink_kill_sock->sk_socket);
- }
- module_init(netlink_kill_init);
- module_exit(netlink_kill_exit);
- MODULE_LICENSE("GPL");
用户态代码如下:
- #include <stdio.h>
- #include <stdlib.h>
- #include <unistd.h>
- #include <string.h>
- #include <sys/types.h>
- #include <sys/socket.h>
- #include <linux/netlink.h>
- struct sig_struct_info {
- int pid;
- int sig
- };
- int main(int argc, char * argv[])
- {
- struct sockaddr_nl saddr, daddr;
- struct nlmsghdr *nlhdr = NULL;
- struct msghdr msg;
- struct iovec iov;
- int sd;
- char text_line[MAX_MSGSIZE];
- int ret = -1;
- struct sig_struct_info sigi;
- memset(&sigi, 0, sizeof(sigi));
- sigi.pid=atoi(argv[1]);
- sigi.sig=atoi(argv[2]);
- sd = socket(AF_NETLINK, SOCK_RAW, 111);
- memset(&saddr, 0, sizeof(saddr));
- memset(&daddr, 0, sizeof(daddr));
- saddr.nl_family = AF_NETLINK;
- saddr.nl_pid = getpid();
- saddr.nl_groups = 0;
- bind(sd, (struct sockaddr*)&saddr, sizeof(saddr));
- daddr.nl_family = AF_NETLINK;
- daddr.nl_pid = 0;
- daddr.nl_groups = 0;
- nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_MSGSIZE));
- memcpy(NLMSG_DATA(nlhdr), &sigi, sizeof(sigi));
- memset(&msg, 0 ,sizeof(struct msghdr));
- ...
- iov.iov_base = (void *)nlhdr;
- iov.iov_len = nlhdr->nlmsg_len;
- msg.msg_name = (void *)&daddr;
- msg.msg_namelen = sizeof(daddr);
- msg.msg_iov = &iov;
- msg.msg_iovlen = 1;
- ret = sendmsg(sd, &msg, 0);
- close(sd);
- return 0;
- }
netlink的应用越来越广泛,你可以将其视为一条总线,该总线是通用的,所有的信息都封装为“帧”在这条总线上传输,这些信息包括系统调用,IPC,内核态和用户态的通信等,具体是哪种信息以及该如何处理信息,netlink这条总线是不过问的,它就类似于PCIe总线,msi,read请求,dma请求都在PCIe上跑,具体是哪种帧由帧的格式区分并且仅由端点处理,如果想更加模块块,端点处的处理可以是分层的,PCIe就是这么做的,同样的道理,netlink也可以这么做。
我觉得,既然硬件都软化了,操作系统也应该“软化”,特别是硬件性能大幅提高的今天!!
- linux的配置接口-netlink原理和设计
- Linux的配置接口-netlink原理和设计
- linux的配置接口-netlink原理和设计
- linux的netlink接口详解(上)
- linux的netlink接口详解(中)
- linux的netlink接口详解(下)
- Linux核心接口Netlink
- netlink的内核实现原理 - [linux内核]
- Linux内核学习:netlink的内核实现原理
- Linux内核学习:netlink的内核实现原理
- linux的netlink机制
- linux的netlink机制
- Linux的Netlink机制
- linux的netlink机制
- linux的netlink机制
- linux 下的netlink
- linux的netlink机制
- linux的netlink机制
- 重装mysql
- CDC中的SelectObject
- 关于招人
- 处理The content of the adapter has changed but ListView did not receive a notification异常
- java中list,map使用泛型和不使用的区别
- linux的配置接口-netlink原理和设计
- oracle远程登录解决方法
- Worklight+eclipse+sencha-touch
- Office365教程之跟着五毛哥从零开始学习
- 安卓第一个项目HelloWord!
- First/Follow集合的求法
- 学习笔记-轻量级Java EE:JSP基本知识
- iOS 上下左右手势
- JS实现刷新iframe的方法


