Flickr Tag Recommendation based on Collective Knowledge
来源:互联网 发布:适合iphone的软件 编辑:程序博客网 时间:2024/04/30 16:57
本篇论文包含两个方面:通过对Flickr的统计,对用户如何使用标签和用户提供的标签有哪些种类进行了研究;另一方面,基于前一方面的分析,提出了四种不同的标签推荐策略,可以被用户用来向图片增加标签。结果表明,推荐的关联标签具备效率高、多层次的特点。

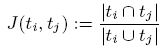
.png)
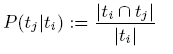
.png)
.png)
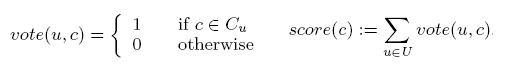
.png)

.png)

.png)
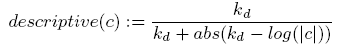
.png)
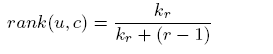
.png)


.png)
1 相关背景
多媒体标注对大规模检索系统来说非常有用。目前基于内容的图片检索系统在不断演进,但是却不能很好的解决人类之间的语义鸿沟。不同的人对同一个图片有不同见解,对同一标注也有不同语义理解。
在利用标签推荐的时候,有两种不同的应用。一种是让用户去对推荐的标签进行选择,一种是推荐的标签直接就存储到系统中丰富图片的索引。
2 用户如何使用标签
1.研究的范围
选择的研究对象是2004-2到2007-6之间的至少有一个用户标签的图片
2.普遍的标签规律
以标签的个数和其出现的频率分别为横纵轴,曲线符合power law。
以图片个数和相应的标签个数分别为横纵轴,曲线符合power law。
为了更好分析标签推荐系统中标签的行为问题,论文中定义了四种不同的类别。第一类是拥有一个tag的图片,大概有15.5million;第二类是拥有2-3个tag的图片,大概有17.5million;第三类是拥有4-6个tag的图片,大概有12million;第三类是有超过6个标签的tag,大概有7million
3.标签分类
为了分析用户标签的内容,利用WordNet的分类对Flickr进行了分类。很多时候,标签可能属于多个分类,这个时候会将标签的分类确定为ranking最高的分类。发现52%的标签可以分类,有48%则不能。通过分类发现,用户不仅仅对图片可见的内容进行标签,在很大程度上会对图片的情景进行拓展,例如地点、时间和动作。
3 标签推荐系统
首先介绍下标签推荐系统,然后解释相应的标签聚合和提取策略。
3.1 基本的标签推荐系统
标签推荐基本分为三步。第一步:收集用户对某一图片(或资源)进行标注的已有标签;第二步:通过tag co-occurrence找寻同时出现的tag;第三步:通过tag的聚合和分级,进行标签推荐。
3.2 tag co-occurrence(tag同现)
tag同现是该论文中进行标签推荐的中最重要的方法。利用不同的方法计算两个tag的同现系数。
①对称方法(Symmetric measures)
可以和Jaccard协同系数一样,用来计算两个对象或tag集之间的相似度
②非对称方法
可以用其中一个tag出现的概率作为tag同现度量
可以理解为,对图片标注了ti的情况下,同样标注tj的概率。(也就是条件概率)
两者的小结:对称方法和非堆成方法相比,对称方法擅长对同等标签进行识别,例如:埃菲尔铁塔、埃菲尔和La埃菲尔铁塔;而非对称方法则能够提供更多维度的可选标签,例如:巴黎、法国、铁塔埃菲尔和欧洲。
3.3 标签聚合和提取(promotion)
有两种不同的聚合策略,基于voting和summing能够达到这个目的,然后通过重新排列(re-ranking)进行提取(promotion)。
三种不同标签的定义:
1)用户定义的标签U:指的是用户向图片指定的一系列标签
2)候选标签Cu:对于任意的u∈U,Cu是同现标签中排名前的m个
3)推荐的标签R:通过标签推荐系统进行推荐的排名前n的最相近的标签
对候选标签C进行聚合,产生最后的推荐标签R。论文中定义了两种聚合策略,第一种是基于voting,这种策略没有考虑候选标签的同现值;第二种是基于summing策略,考虑用同现值产生分级。两种情况中,都会产生排行前m个的同现标签。
Vote。为每个在C中的c有一个score,如果c属于Cu,则其score会加1。计算公式如下:
Sum。该策略考虑所有候选的标签列表C,然后计算标签的同现值,最后计算每个候选标签c∈C的score。计算公式如下:
P(c|u)计算了非对称同现值。
提取(Promotion) 标签分布的基本规律就是服从power law,其头部和尾部都不能很好的用来进行推荐。尾部的标签由于不经常出现,被认为是不稳定固定的描述;头部包含的标签过于大众化。
Stability-promotion。用户定义的标签可以认为其出现频率越高,稳定性越好;推荐稳定性好的标签。
|u|是标签u在集合中的频率,Ks是参数。
Descriptiveness-promotion。标签拥有越高的频率对于图片来讲越普通。
Kd是参数。
Rank-promotion。对于用户标签u的候选标签c∈Cu,其在候选标签集合中的位置为r。
Kr是一个衰减的参数。
根据上述的promotion函数,论文提出了一个标签对(u,c):
将promotion和voting或summing聚合方法结合,结合promotion和voting计算score的方法如下:
这样,一个标签系统中有一系列参数,包括m,Kr,Ks,Kd.
四种不同的策略就是vote,sum,vote+和sum+。
4总结与对比
最好的策略就是V+,具备很好的稳定性能;而且标签推荐系统擅长推荐地点、制造物和对象等,其词汇容量和推荐采用率都较高。
1)标签频率的分布呈现power law曲线
2)在power law中间部分的标签包含了进行标签推荐最感兴趣的候选
3)提出的四个策略有有效,通过对标签进行分级
0 0
- Flickr Tag Recommendation based on Collective Knowledge
- Flickr Tag Recommendation based on Collective KnowLedge
- Flickr Tag Recommendation based on Collective Knowledge
- 论文:Recommendation Based on Contextual Opinions 总结
- Movie recommendation based on collaborative filtering method
- Movie recommendation based on collaborative filtering method
- 【转载】论文读书笔记-personalized news recommendation based on click behavior
- 论文笔记:A Survey on Tag Recommendation Methods 上
- 论文笔记:A Survey on Tag Recommendation Methods 下
- Knowledge Tag
- FaceBook: Text Tag Recommendation
- Knowledge-based system
- Deep content-based music recommendation
- Ask Me Anything:Free-form Visual Question Answering Based on Knowledge from External Sources
- LDA主题模型用于BUG修复人推荐《DRETOM: developer recommendation based on topic models for bug resolution》
- Item-Based Collaborative Filtering Recommendation Algorithms
- -Item-Based Collaborative Filtering Recommendation Algorithms
- [机器学习]content-based recommendation
- Palindrome Partitioning II
- 读c语言深度剖析 -- typedef小结(3) 定义结构体
- 理工大学ACM平台题答案关于C语言 1006 Sum Problem
- Makefile $@ $< $^自动化变量
- 查看内存命令
- Flickr Tag Recommendation based on Collective Knowledge
- RBAC(Role-Based Access Control)基于角色的访问控制
- 黑马程序员——jdk1.5新特性
- Androi NDK生成 找不到对应的C的函数异常
- WinFrom中如何获取文件图片路径
- 不常用的文件分割与合并(使用split和cat)
- 初识cocos2dx
- 项目开发计划——机房收费系统
- hdu 4810 Wall Painting(二进制+组合数学)


