人工神经网络ANN的一些概念的集合
来源:互联网 发布:网络系统集成中的软件 编辑:程序博客网 时间:2024/06/07 06:44
神经网络,学生时,特意修了这门课,但完全找不到感觉,内容基本不理解,实验无头绪。经历了一些项目实践,现在回头再理解NN,一些概念自然就理解了。
1.
单层神经网络:输入
输出
激活函数: 非线性,就是指这个激活函数。z是各输入数据与系数的加权和,a是输出。
权值系数w,与输入仍然成线性关系
多层神经网络
表象的概念:
输入层
输出层
隐藏层
----
权值:也扩展至二维w(i, j)
根据传播形式:
前向传播
前馈网络: 无闭环
反向传导算法: 如何求解神经网络。 训练, 识别。
2.
一个重要概念: 梯度下降算法 --> 批量梯度下降算法cost function: 代价函数,即 计算值与真实值的差异。一般用均方差表示。
代价函数的概念极其重要,因为它是进行分类和回归的中心。代价函数就是衡量 参数w和b依据。 代价函数越小,那么计算出的参数w,b就越好。
我们的目标: 针对w,b;求代价函数的最小值。
代价函数除了均方差的概念,为防止过度拟合,还需增加一个 规则化项(也叫权重衰减项),以减小权重的幅度。
又一个概念:
过度拟合overfitting: 有什么现象,后果? 就是训练时,数据噪声太大,拟合出来的模型,不能满足实际的数据应用。就是拟合失败,训练失败。模型能适用训练数据,不适合一般的数据。
解决方法: 对神经网络,增加权重衰减项; 对决策树,依据一定规则修剪树。
3.
如何求w,b,让代价函数cost function有一个最小值?
采用训练的方式,重复计算,并保证w,b能收敛。这就是机器学习。
1). w,b初始化为一个值。一般初始化为一个很小的、接近为0的随机值,如正态分布N(0, 0.01)。(为什么?)
如果将所有系数都初始化为0,则对于隐藏层,所有的输入值都相同。随机,就是使对称失效。(这个就是那么个意思,解释起来太拗口)。初始化系数都为0.任何输入 相乘后,激活函数的输入都等于b,偏置项。
2). 取输入,输出对(x,y)
3). 然后利用梯度下降算法。计算最优的w,b。
相同的输入、输出,只需要不停的更新w,b即可。
4). 最后考虑局部解与全局最优解的问题。
4.
概念: 梯度下降算法。 最优化中的基本算法之一。又称最速下降法。 沿负梯度方向下降最快。一种简单的形式:x(k+1)=x(k)-a*g(k),g(k)为梯度方向,a是一个学习系数。
求cost function的负梯度方向。求各方向的偏导,相加,求模,相除。
带入此点系数w,b,x,y。即可求出此点的具体的梯度方向。
最后,如何求偏导。神经网络的cost function只是个概念,只有象形的公式,没有具体的公式。所以,无法利用直接的公式进行求导。
1) 前向传播,计算所有节点的激活值
2)反向传播,计算所有节点的残差
3)利用残差,更新偏导数dw, db
这里又推出一种算法: 反向传播算法。用于计算偏导d(w,b)/ d(w), d(w, b) / d(b)。
两个关键的概念: 残差、反向求残差
5.
这里又提出一个概念:残差。
残差:每个节点都有残差值,其表明了每个节点对最终输出值(即 代价函数、最终方差值)的影响。
最终输出节点的残差是 代价函数 在此节点的求导,获取其对 代价函数的影响值 。
经推导,此残差就是 激活函数的输出值 与 实际值之差,再乘以 激活函数的导数值。
对二阶函数的求导,就是一阶函数,乘以此激活函数的导数。
对于输出值与实际值之间的差值,可以理解为偏差,
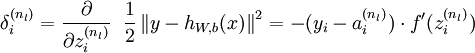
对于隐藏单元的残差: 即隐藏单元 对 总的代价函数的影响。
求导,推导出 前后两个单元间的影响。
前后两个单元的影响,就是权值,加上激活函数的影响。
一次计算时, 权值是常数。 激活函数的一阶导数。
利用反向传播的形式,由最后一层,逐步向第一层的方向推导。
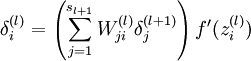
不仅要求出 当前层的 激活值的导数,还要计算出一个加权平均值,是第l+1层所有残差对上一层第i个节点的残差的影响。这个需要好好理解,多看看推导是有好处的。
计算出残差后,就能计算所谓的偏导数了。
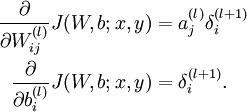
第l层,第i个节点,j的含义是第l+1的数据。。。 这个要好好理解。
就是所谓的反向传播算法了。实际上是,反向求偏导数的一种算法。
以上是前馈神经网络在有监督学习中的应用。
7.
opencv中提供了CvANN_MLP类来实现 NN 算法。
CvANN_MLP首先会指定 MLP的拓扑结构和激活函数:
层数:包括输入、隐藏、输出各层的数目。一般是一个一维矩阵。
激活函数: 默认是双曲正切函数
训练:
拿到输入和结果数据后,就能进行训练参数的设置了。
CvANN_MLP_TrainParameter包括了算法的种类选择,反向传播算法back_prop,还是rprop算法,及其他们的主要参数。
而且,需要设定算法运行的最大迭代次数,和误差截止值(相邻两次迭代误差之差)
执行训练函数。MLP相对收敛较慢,不过结果较好。结束后,MLP就训练好了。
剩下的就是分类了。predict函数,就能拿到结果了。
8.
对于神经网络,有监督学习是首先拿到训练数据的分类标签的。而对于无监督学习,是无法拿到分类标签的。
只能自学习,进行聚类。自编码神经网络就是满足这种需求。
目的:发现输入数据的自身的一些特征,或一些结构,或一些相关性。
输入数据的压缩表示:相当于降维表示;与PCA有点类似。
稀疏性限制:假设sigmoid函数是激活函数,那么输出结果接近1,表示被激活,输出结果接近0,表示被抑制。当神经元大部分处于抑制状态,就称为对神经元的稀疏性限制。 ps: 使用tanh作为激活函数,当神经元输出接近-1的时候,神经元是被抑制的。
所以,神经元的激活度的表示很重要。
9.
一般会求出神经元 的 平均活跃度。
稀疏性参数,就是专门指定 神经元的平均活跃度的标准值。一般是一个比较小的值,如0.05.为了达到这一目标,需要对优化函数加入一个惩罚因子。
这个惩罚因子会随着,平均活跃度和稀疏参数的差值变大而单调递增。当两者相等时,惩罚因子也为0。一般惩罚因子选择用以下函数
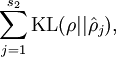 其中
其中 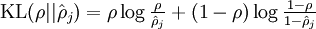 就是 稀疏性参数与神经元平均活跃度的 相对熵。
就是 稀疏性参数与神经元平均活跃度的 相对熵。
而 总体代价函数就可以表示为:
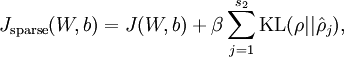
直接跳到这一步,很难理解。 因为J 值如何计算? 因为选用的是恒等式 f = x,那么目标值与输入值相等,代价函数应该是与w, b密切相关,KL函数也是间接与w,b相关的。
仍然是,反向传播算法,只不过增加了一个 相对熵的 求导运算。
- 从
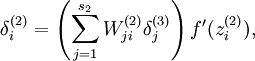
到
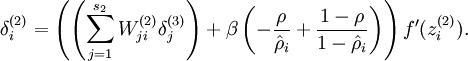
更一步学习的概念:
稀疏编码。
理论概念过了一遍,其效果如何哪?
这个无监督的神经网络,学习了一番之后,有什么能力那?
可视化每个训练好的隐藏单元。每个隐藏单元对应一幅图像。
10.
这里涉及到概念:
范数:一种实值函数。有1, 2, 无穷阶的形式。 1阶对应 绝对值,二阶对应 模,无穷 对应最大值。
最大激励:输出值比较大
平凡解:无意义的解,如线性Ax = 0,解是x=0.即0解
以上的概念都来自:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
以及opencv手册
对应的概念: 极大似然估计。
激活函数选择,线性,还是非线性函数?
如果是线性,等于连续的向量/矩阵相乘,得出的结果仍然是一个矩阵/向量。而其他表达,如一些二元结构的东西,用线性是无法直接表达的。这是线性的缺陷。
对于二元结构的表达,应用非线性函数,如双曲正切函数,就能较好的表达二元结构。
- 人工神经网络ANN的一些概念的集合
- 人工神经网络ANN的一些概念的集合
- 人工神经网络(ANN)
- 人工神经网络(ANN)
- 人工神经网络(ANN)
- 人工神经网络(ANN) .
- 人工神经网络(ANN)
- 人工神经网络(ANN)
- ANN-人工神经网络
- 人工神经网络(ANN)
- ANN人工神经网络基础分类
- 【人工神经网络ANN】- 1 - 概览
- 初识人工神经网络(ANN)
- ANN(人工神经网络)基础知识
- 人工神经网络(ANN)学习
- 什么是人工神经网络 人工神经网络的介绍
- 人工神经网络(Artificial Neural Networks, ANN)
- 人工神经网络(ANN, artificial neural network)
- linux 多线程的线程控制和线程通信
- Future异步事件驱动
- 改变ubuntu下系统字体
- 马云杀入手游业挑战腾讯 游戏开发商分成比提至70%厉害
- ACPI Tables
- 人工神经网络ANN的一些概念的集合
- ViewPager结合Fragment实现页面左右滑动
- addd
- visual studio 2010 中VC++自定义项目模板
- Ogre中使用HLSL的一个例子
- 返回值和右值引用的传递问题
- win7系统下php环境搭建教程(ZendStudio-5_5_1)(apache_2.2.6-win32-x86-no_ssl)(php-5.3.10-Win32-VC9-x86)
- 【Codility】PassingCars
- [leet code] Balanced Binary Tree


