hive 结合执行计划 分析 limit 执行原理
来源:互联网 发布:js设置div的id 编辑:程序博客网 时间:2024/05/29 08:06
- select deviceid from t_aa_pc_log where pt='2012-07-07-00' limit 1;
- > select deviceid from t_aa_pc_log where pt='2012-07-07-00' limit 1;
- Total MapReduce jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks is set to 0 since there's no reduce operator
- Starting Job = job_201205162059_1547550, Tracking URL = http://jt.dc.sh-wgq.sdo.com:50030/jobdetails.jsp?jobid=job_201205162059_1547550
- Kill Command = /home/hdfs/hadoop-current/bin/hadoop job -Dmapred.job.tracker=10.133.10.103:50020 -kill job_201205162059_1547550
- 2012-07-07 16:22:42,570 Stage-1 map = 0%, reduce = 0%
- 2012-07-07 16:22:48,628 Stage-1 map = 80%, reduce = 0%
- 2012-07-07 16:22:49,640 Stage-1 map = 100%, reduce = 0%
- 2012-07-07 16:22:50,654 Stage-1 map = 100%, reduce = 100%
- Ended Job = job_201205162059_1547550
- OK
- 0cf49387a23d9cec25da3d76d6988546
- Time taken: 13.499 seconds
- hive>

- > explain select deviceid from t_aa_pc_log where pt='2012-07-07-00' limit 1;
- OK
- STAGE DEPENDENCIES:
- Stage-1 is a root stage
- Stage-0 is a root stage
- STAGE PLANS:
- Stage: Stage-1
- Map Reduce
- Alias -> Map Operator Tree:
- t_aa_pc_log
- TableScan
- alias: t_aa_pc_log
- Filter Operator
- predicate:
- expr: (pt = '2012-07-07-00')
- type: boolean
- Select Operator
- expressions:
- expr: deviceid
- type: string
- outputColumnNames: _col0
- Limit
- File Output Operator
- compressed: false
- GlobalTableId: 0
- table:
- input format: org.apache.hadoop.mapred.TextInputFormat
- output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
- Stage: Stage-0
- Fetch Operator
- limit: 1
- Time taken: 0.418 seconds
- protected List<Operator<? extends Serializable>> childOperators;
- protected List<Operator<? extends Serializable>> parentOperators;
- protected boolean done; // 初始化值为false

- mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
- hive.input.format org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
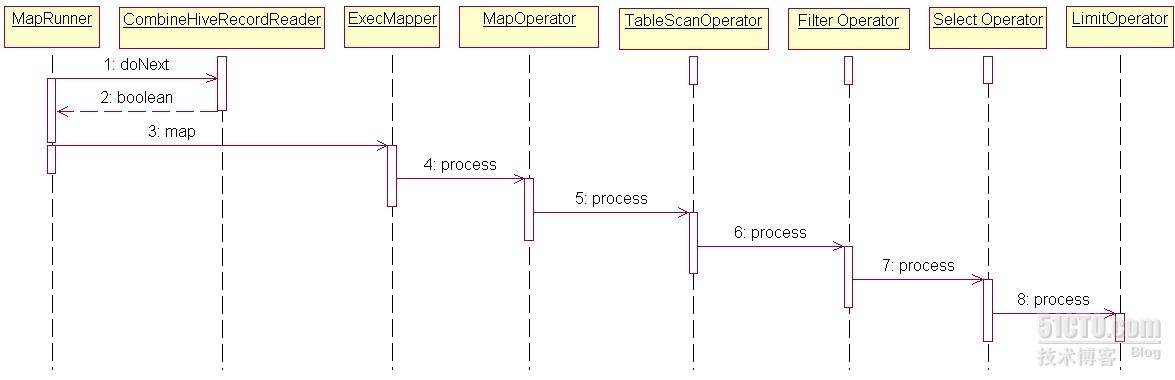
- @Override
- public boolean doNext(K key, V value) throws IOException {
- if (ExecMapper.getDone()) {
- return false;
- }
- return recordReader.next(key, value);
- }
- public void map(Object key, Object value, OutputCollector output,
- Reporter reporter) throws IOException {
- if (oc == null) {
- oc = output;
- rp = reporter;
- mo.setOutputCollector(oc);
- mo.setReporter(rp);
- }
- // reset the execContext for each new row
- execContext.resetRow();
- try {
- if (mo.getDone()) {
- done = true;
- } else {
- // Since there is no concept of a group, we don't invoke
- // startGroup/endGroup for a mapper
- mo.process((Writable)value);
- int childrenDone = 0;
- for (int i = 0; i < childOperatorsArray.length; i++) {
- Operator<? extends Serializable> o = childOperatorsArray[i];
- if (o.getDone()) {
- childrenDone++;
- } else {
- o.process(row, childOperatorsTag[i]);
- }
- }
- // if all children are done, this operator is also done
- if (childrenDone == childOperatorsArray.length) {
- setDone(true);
- }
- @Override
- public void processOp(Object row, int tag) throws HiveException {
- if (currCount < limit) {
- forward(row, inputObjInspectors[tag]);
- currCount++;
- } else {
- setDone(true);
- }
- }
0 0
- hive 结合执行计划 分析 limit 执行原理
- hive 结合执行计划 分析 limit 执行原理
- hive 结合执行计划 分析 limit 执行原理
- hive 结合执行计划 分析 limit 执行原理
- hive 结合执行计划 分析 limit 执行原理
- hive原理与源码分析-物理执行计划与执行引擎(六)
- hive sql执行计划
- hive 执行计划
- hive sql执行计划
- hive执行计划EXPLAIN
- Hive SQL解析/执行计划生成流程分析
- Hive SQL解析/执行计划生成流程分析
- Hive SQL解析/执行计划生成流程分析
- Presto源码分析(和hive执行计划的比较)
- Hive----查询执行计划(explain)和分析表数据(ANALYZE)
- 看懂Hive的执行计划
- hive执行源码分析
- Hive执行流程分析
- bleCentralManager 蓝牙透传
- 第6周 Hadoop子项目与Hbase
- bulk collect 学习
- 低分辨率、非对齐、视频监控数据中的人脸识别(LFW, YTF)+CVPR2013
- Charm Bracelet
- hive 结合执行计划 分析 limit 执行原理
- poi 操作excel 2007 设置 字体样式 插入图片
- Surface与SurfaceHolder.Callback
- 解析Unity3D多线程之间的事件派发
- 发布只读访问跨地域冗余存储公共预览版
- hive 执行计划
- 第7周 HBase集群安装,管理
- oracle 10g数据文件的表空间简单扩展
- linux的ulimit各种限制之深入分析


