栈帧详解
来源:互联网 发布:淘宝图片自己拍 编辑:程序博客网 时间:2024/05/02 04:58
一、 什么是栈帧?
什么是栈帧,相信很多从事C编程的童鞋还是没有搞明白,首先引用百度百科的经典解释:“栈帧也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构。”。
实际上,可以简单理解为:栈帧就是存储在用户栈上的(当然内核栈同样适用)每一次函数调用涉及的相关信息的记录单元。也许这样感觉更复杂了,好吧,让我们从栈开始来理解什么是栈帧...
二、 栈(用户栈和内核栈)
在大学学习《数据结构》的时候,了解到栈作为一种特殊的数据结构而存在(和“队列”相反的记录结构和操作规则),是一种只能在一端进行插入和删除操作的特殊线性表。
它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
栈有很多自己的特性,它具有记忆功能,对栈的插入与删除操作中,不需要改变栈底指针;而且栈是从高地址向低地址延伸的。每个函数的每次调用,都有它自己独立的一个栈帧,这个栈帧中维持着所需要的各种信息。因此栈作用就是用来保持栈帧的活动记录(即函数调用)。下面有这样一幅图(源自Unix环境高级编程第七章):
对于一个栈来说,寄存器ebp和esp分别指向指向系统栈最上面一个栈帧的底部和栈帧顶部(实际上也是栈的顶部)。上图可以清晰的看到栈位置在用户空间的最顶部(从0xc0000000开始向下增长),下于堆对接,实际上堆与栈之间有很大的未使用空间,这里不做详述。
三、栈帧
栈帧表示程序的函数调用记录,而栈帧又是记录在栈上面,很明显栈上保持了N个栈帧的实体,(实际上我们这里说的栈帧是软件上的概念,据说有硬件概念,不是很了解),那就可以说栈帧将栈分割成了N个记录块,但是这些记录块大小不是固定的,因为栈帧不仅保存诸如:函数入参、出参、返回地址和上一个栈帧的栈底指针等信息,还保存了函数内部的自动变量(甚至可以是动态分配内存,alloca函数就可以实现,但在某些系统中不行),因此,不是所有的栈帧的大小都相同。
下面通过一个简单的实例,来分析栈帧的记录活动(这个说明实例参考:http://blog.csdn.net/yxysdcl/article/details/5569351):
void func(int m, int n) {
int a, b;
a = m;
b = n;
}
main() {
...
func(m, n);
L: 下一条语句
...
}
上面是一个简单的可执行代码,目的是为了说明栈帧在栈中的存储形式,因为一个可执行程序在程序的开始嵌入了启动例程代码(这段汇编代码由编译器嵌入可执行程序的其实位置,这里不深究该行为),在执行时由启动例程调用main函数,可以说main函数是第一个被调用的C代码函数,暂且认为是main函数是第一函数。
这里的main函数只是简单调用了一个函数func,那么在main调用func函数前,栈的情况是下面这个样子的:

此时栈中只有一个main函数的栈帧,从低地址esp(栈顶指针)到高地址ebp(栈帧栈底指针)的这块区域,就是当前main函数的栈帧。当main中调用func时,写成汇编大致是:
push m
push n; 两个参数压入栈
call func; 调用func,将返回地址(实际上是当前PC值的下一个值)填入栈,并跳转到func
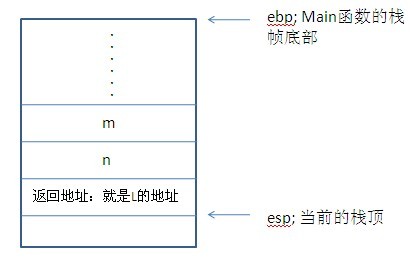
当成功跳转到func函数中时,func函数的栈帧就已经形成了,但是形成新的栈帧之前,必须要重新记录当前栈帧的栈底指针ebp,下面的保存和切换ebp的几个动作是由系统自动完成的(就像Linux中的中断一样,在进入中断处理函数前要做很多的准备工作:如保存当前执行环境,这样才能在处理程序结束后,恢复打断的进程的环境),可以说这几个动作被系统自动加入:
__func:
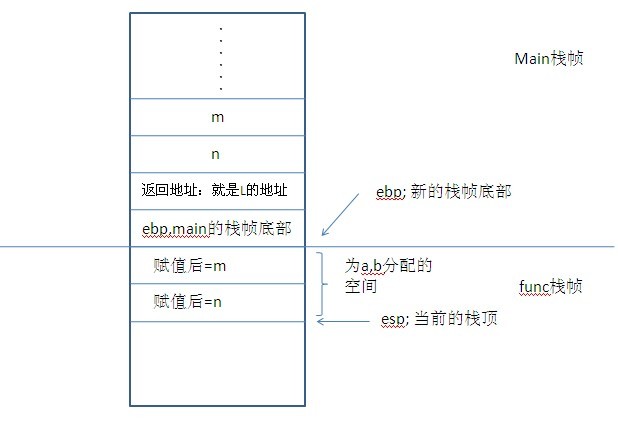
push ebp; 函数调用之所以能够返回,单靠保持返回地址是不够的,这一步压栈动作很重要,因为我们要标记函数调用者栈帧的帧底,这样才能找出保存了的返回地址,栈顶是不用保存的,因为上一个栈帧的顶部讲会是func的栈帧底部。(两栈帧相邻的)
mov ebp, esp; 上一栈帧的顶部,就是这个栈帧的底部
;暂时先看现在的栈的情况

;到这里,此时新的栈帧开始了,由下图中间的一根长长的横线隔开两个栈帧
sub esp, 8 ; int a, b 这里声明了两个int,所以esp减小8个字节来为a,b分配空间
mov dword ptr [esp+4], [ebp+12]; a=m
mov dword ptr [esp], [ebp+8]; b=n
这样,栈的情况变为:
ret 8 ; 返回,然后8是什么意思呢,就是自动变量占用的字节数,当返回后,esp-8,释放参数m,n的空间
由此可见,通过ebp,能够很容易定位到上面的参数。当从func函数返回时,首先esp移动到栈帧底部(即释放自动变量),然后把上一个函数的栈帧底部指针弹出到ebp,再弹出返回地址到cs:ip上,esp继续移动划过参数,这样,ebp,esp就回到了调用函数前的状态,即现在恢复了原来的main的栈帧。
OK,到这里应该说明白了栈帧在栈帧的分布和形成过程,那么栈帧在我们编程过程中给我们什么启示呢?
(1)栈帧上的动态内存分配
前面已经说明过一点:在大部分系统中,栈帧上可以进行动态内存的分配。malloc、calloc和realloc函数都是在堆上动态分配一块内存,在使用过后一定要记得释放动态分配的内存,否则就会产生内存泄露,最终降低系统的性能。
但是如果要在栈帧上动态分配内存的话,那么在函数返回时会自动释放这些内存,而不必担心忘记释放动态分配的内存。我们知道在Linux内核中,每个进程的栈只有1-2个页的大小,即4K-8K大小,需要很珍惜的使用这部分空间;不过实用户栈的空间很大,可以随着需要动态的扩充,而不必担心栈不够用,因此我们还是可以放心的使用alloca动态分配函数在用户栈帧上分配内存。
(2)函数调用深度
在很多系统中都对函数调用的深度做了限制,函数调用深度是指函数嵌套的程度。函数嵌套的程度决定了在栈上同一时刻所拥有的栈帧的最大数量,函数调用的嵌套程度对用户进程来说不是什么问题,但是在内核中栈的大小固定且不能重新分配,因此调用的深度在内核中就存在很大的意义,这里我们不做详述。
(3)函数调用的参数
栈帧部分已经描述了函数参数的保存位置,即保存在调用者栈帧的尾部固定长度偏移位置,程序运行时就根据函数的定义和该位置取参数进行相应的运算。
注意:这里函数调用的参数显然存储在函数调用者的栈帧中,而不是被调用函数的栈帧中。
(4)栈的回溯
学习编程和Linux内核的童鞋一定经常听到“栈的回溯”,它是指系统自主打印进程调用栈的行为。从上面描述栈帧的情况可以看出,系统在将栈打印出来的顺序应当是调用的反顺序,它是从esp(低地址)一点一点向高地址回溯,这正是栈帧形成的反过程。因此,我们经常从下到上看函数的调用,不过有些日志系统将导出的回溯信息重新排序,可以从上到下来查看函数调用顺序。
好吧,暂时就先总结这点,我在学些一个知识点后,总是喜欢将它同实际工作中遇到的可以理解到的情形做个联系和总结,因为,这样可以加深对知识点的印象和整体的提高,同时还能强化对学习的兴趣,觉得不错的童鞋也可以试试,还是蛮有点成就感的...
- linux栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 栈帧详解
- 【C语言】详解栈帧
- Linux系统--栈帧详解
- 栈详解
- 函数调用过程栈帧变化详解
- 函数调用过程栈帧变化详解
- 函数调用与栈帧详解
- 函数栈帧(函数调用过程详解)
- 函数调用及栈帧详解
- 『黑马程序员』---java--IO--字符流基础
- hexToDec
- 排列算法——字典序法
- 插入排序--直接插入排序和希尔排序
- 2. Hello World (2)
- 栈帧详解
- 【Sesame】Triple Store 添加三元数据
- 基本排序(回顾排序)
- pku 1014
- 在我参加的一个晚会上
- 并非我们不重视理想
- 搜索(IDA*)HOJ The Rotation Game
- 2045——不容易系列之(3)—— LELE的RPG难题
- PackageManagerService学习笔记四-构造方法(扫描Package)


