Hadoop数据管理之分布式文件系统HDFS
来源:互联网 发布:淘宝详情视频尺寸大小 编辑:程序博客网 时间:2024/05/07 06:35
HDFS是分布式计算的存储基石,Hadoop分布式文件系统和其他分布式文件系统有很多类似的特质:
·对于整个集群有单一的命名空间;
·具有数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前是无法看到文件存在的;
·文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且会根据配置由复制文件块来保证数据的安全性。
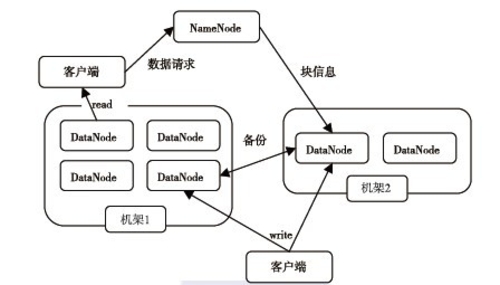
从图中看出,HDFS通过三个重要的角色来进行文件系统的管理:NameNode、DataNode和Client。NameNode可以看做是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的 Metadata存储在内存中,这些信息主要包括文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode中的信息等。 DataNode是文件存储的基本单元,它将文件块(Block)存储在本地文件系统中,保存了所有Block的Metadata,同时周期性地将所有存在的 Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。以下通过三个具体的操作来说明HDFS对数据的管理。
(1)文件写入
1) Client向NameNode发起文件写入的请求。
2)NameNode根据文件大小和文件块的配置情况,返回给Client它所管理的DataNode的信息。
3)Client将文件划分为多个Block,根据DataNode的地址信息,按顺序将其写入每一个DataNode块中。
(2)文件读取
1) Client向NameNode发起读取文件的请求。
2) NameNode返回文件存储的DataNode信息。
3)Client读取文件信息。
(3)文件块(Block)复制
1) NameNode发现部分文件的Block不符合最小复制数这一要求或部分DataNode失效。
2)通知DataNode相互复制Block。
3)DataNode开始直接相互复制。
HDFS作为分布式文件系统在数据管理方面还有几个值得借鉴的功能:
·文件块(Block)的放置:一个Block会有三份备份,一份放在NameNode指定的DataNode上,另一份放在与指定的DataNode不在同一Rack上的DataNode上,最后一份放在与指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种配置方式主要是考虑同一Rack失败的情况,以及不同Rack之间的数据拷贝会带来的性能问题。
·心跳检测:用心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
·数据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和平衡DataNode数据交互压力等情况):使用Hadoop时可以用HDFS的balancer命令配置Threshold来平衡每一个DataNode的磁盘利用率。假设设置了Threshold为10%,那么执行balancer命令的时候,首先会统计所有DataNode的磁盘利用率的平均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode上,这对于新节点的加入来说十分有用。
·数据校验:采用CRC32做数据校验。在写入文件Block的时候,除了写入数据外还会写入校验信息,在读取的时候则需要校验后再读入。
·单个NameNode:如果失败,任务处理信息将会记录在本地文件系统和远端的文件系统中。
·数据管道性的写入:当客户端要写入文件到DataNode上时,客户端首先会读取一个Block,然后写到第一个DataNode上,接着由第一个 DataNode将其传递到备份的DataNode上,直到所有需要写入这个Block的DataNode都成功写入后,客户端才会开始写下一个 Block。
·安全模式:分布式文件系统启动的时候会有安全模式(系统运行期间也可以通过命令进入安全模式),当分布式文件系统处于安全模式时,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了在系统启动的时候检查各个DataNode上的数据块的有效性,同时根据策略进行必要的复制或删除部分数据块。在实际操作过程中,若在系统启动时修改和删除文件会出现安全模式不允许修改的错误提示,只需要等待一会儿即可。
- Hadoop数据管理之分布式文件系统HDFS
- hadoop之HDFS(分布式文件系统)
- Hadoop之Hdfs分布式文件系统
- Hadoop系列之六:分布式文件系统HDFS
- Hadoop之HDFS(分布式文件系统)-yellowcong
- 深入HDFS:Hadoop之分布式文件系统
- HDFS-hadoop分布式文件系统
- Hadoop HDFS分布式文件系统
- HDFS--Hadoop分布式文件系统
- HDFS--Hadoop分布式文件系统
- hdfs:Hadoop分布式文件系统
- HDFS【Hadoop分布式文件系统】
- Hadoop分布式文件系统HDFS
- Hadoop连载系列之四:Hadoop分布式文件系统HDFS
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
- Hadoop分布式文件系统(HDFS)
- Hadoop平台Hdfs分布式文件系统
- 粗糙的iOS笔记之五——>聊天气泡绘制
- STL中的算法
- 当UIButton触发点击事件时获取触发点坐标
- 第四讲 变量和常量
- 黑马程序员学习笔记——类装载器粗解
- Hadoop数据管理之分布式文件系统HDFS
- 快速、冒泡、选择、直接插入C语言实现
- opencv 笔记第一天
- 求两个数的最大公约数和最小公倍数
- Microsoft Windows Workflow Foundation 4.0 Cookbook书翻译
- 使用geoserver+openLayers加载google地图
- Multiply Strings
- 关于ARGB_8888、ALPHA_8、ARGB_4444、RGB_565的理解
- 第五讲 预定义数据类型


