JVM方法内联
来源:互联网 发布:切片软件 编辑:程序博客网 时间:2024/06/01 10:31
更多文章请访问:deepinmind
在IntelliJ IDEA里面Ctrl+Alt+M用来拆分方法。选中一段代码,敲下这个组合,非常简单。Eclipse也用类似的快捷键。我讨厌长的方法,提起这个下面这个方法我就觉得太长了:
public void processOnEndOfDay(Contract c) { if (DateUtils.addDays(c.getCreated(), 7).before(new Date())) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }}首先,它有个条件判断可读性很差。先不管它怎么实现的,它做什么的才最关键。我们先把它拆分出来:
public void processOnEndOfDay(Contract c) { if (isOutdated(c)) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} private boolean isOutdated(Contract c) { return DateUtils.addDays(c.getCreated(), 7).before(new Date());}很明显,这个方法不应该放到这里(按下F6,转移实例方法):
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }}注意到什么不同吗?我的IDE把isOutdated方法改成Contract的实例方法了,这才像样嘛。不过我还是不爽。这个方法做的事太杂了。一个分支在处理业务相关的逻辑priorityHandling,还有一些系统通知和记录日志。另一个分支在做系统通知和日志记录。我们先把处理过期合同拆分成一个独立的方法:
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { handleOutdated(c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} private void handleOutdated(Contract c) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c);}有人会觉得这样已经够好了,不过我觉得两个分支并不对称令人扎眼。handleOutdated方法层级更高些,而else分支更偏细节。软件应该清晰易读,因此不要把不同层级间的代码混到一起。这样我会更满意:
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { handleOutdated(c); } else { stillPending(c); }} private void handleOutdated(Contract c) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c);} private void stillPending(Contract c) { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c);}这个例子看起来有点装,不过其实我想证明的是另一个事情。虽然现在不太常见了,不过还是有些开发人员不敢拆分方法,担心这样的话影响运行效率。他们不知道JVM其实是个非常棒的软件(它其实甩Java语言好几条街),它内建有许多非常令人惊讶的运行时优化。首先短方法更利于JVM推断。流程更明显,作用域更短,副作用也更明显。如果是长方法JVM可能直接就跪了。第二个原因则更重要:
方法内联
如果JVM监测到一些小方法被频繁的执行,它会把方法的调用替换成方法体本身。比如说下面这个:
private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4);} private int add2(int x1, int x2) { return x1 + x2;} 可以肯定的是运行一段时间后JVM会把add2方法去掉,并把你的代码翻译成:
private int add4(int x1, int x2, int x3, int x4) { return x1 + x2 + x3 + x4;} 注意这说的是JVM,而不是编译器。javac在生成字节码的时候是比较保守的,这些工作都扔给JVM来做。事实证明这样的设计决策是非常明智的:
JVM更清楚运行的目标环境 ,CPU,内存,体系结构,它可以更积极的进行优化。
JVM可以发现你代码运行时的特征,比如,哪个方法被频繁的执行,哪个虚方法只有一个实现,等等。
旧编译器编译的.class在新版本的JVM上可以获取更快的运行速度。更新JVM和重新编译源代码,你肯定更倾向于后者。
我们对这些假设做下测试。我写了一个小程序,它有着分治原则的最糟实现的称号。add128方法需要128个参数并且调用了两次add64方法——前后两半各一次。add64也类似,不过它是调用了两次add32。你猜的没错,最后会由add2方法来结束这一切,它是干苦力活的。有些数字我给省略了,免得亮瞎了你的眼睛:
public class ConcreteAdder { public int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) { return add64(x1, x2, x3, x4, ... more ..., x63, x64) + add64(x65, x66, x67, x68, ... more ..., x127, x128); } private int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) { return add32(x1, x2, x3, x4, ... more ..., x31, x32) + add32(x33, x34, x35, x36, ... more ..., x63, x64); } private int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32) { return add16(x1, x2, x3, x4, ... more ..., x15, x16) + add16(x17, x18, x19, x20, ... more ..., x31, x32); } private int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16) { return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16); } private int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) { return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8); } private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4); } private int add2(int x1, int x2) { return x1 + x2; }} 不难发现,调用add128方法最后一共产生了127个方法调用。太多了。作为参考,下面这有个简单直接的实现版本:
public class InlineAdder { public int add128n(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) { return x1 + x2 + x3 + x4 + ... more ... + x127 + x128; } }最后再来一个使用了抽象类和继承的实现版本。127个虚方法调用开销是非常大的。这些方法需要动态分发,因此要求更高,所以无法进行内联。
public abstract class Adder { public abstract int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128); public abstract int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64); public abstract int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32); public abstract int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16); public abstract int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8); public abstract int add4(int x1, int x2, int x3, int x4); public abstract int add2(int x1, int x2);} 还有一个实现:
public class VirtualAdder extends Adder { @Override public int add128(int x1, int x2, int x3, int x4, ... more ..., int x128) { return add64(x1, x2, x3, x4, ... more ..., x63, x64) + add64(x65, x66, x67, x68, ... more ..., x127, x128); } @Override public int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) { return add32(x1, x2, x3, x4, ... more ..., x31, x32) + add32(x33, x34, x35, x36, ... more ..., x63, x64); } @Override public int add32(int x1, int x2, int x3, int x4, ... more ..., int x32) { return add16(x1, x2, x3, x4, ... more ..., x15, x16) + add16(x17, x18, x19, x20, ... more ..., x31, x32); } @Override public int add16(int x1, int x2, int x3, int x4, ... more ..., int x16) { return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16); } @Override public int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) { return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8); } @Override public int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4); } @Override public int add2(int x1, int x2) { return x1 + x2; }} 受到我的另一篇关于@Cacheable 负载的文章的一些热心读者的鼓舞,我写了个简单的基准测试来比较这两个过度分拆的ConcreteAdder和VirtualAdder的负载。结果出人意外,还有点让人摸不着头脑。我在两台机器上做了测试(红色和蓝色的),同样的程序不同的是第二台机器CPU核数更多而且是64位的:
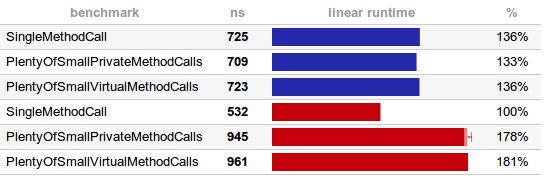
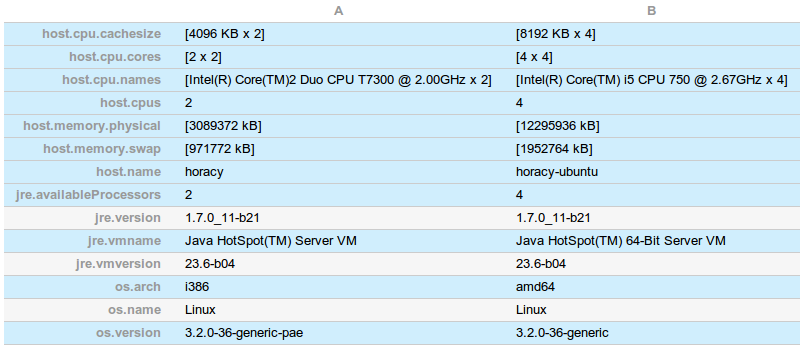
具体的环境信息:
看起来慢的机器上JVM更倾向于进行方法内联。不仅是简单的私有方法调用的版本,虚方法的版本也一样。为什么会这样?因为JVM发现Adder只有一个子类,也就是说每个抽象方法都只有一个版本。如果你在运行时加载了另一个子类(或者更多),你会看到性能会直线下降,因为无能再进行内联了。先不管这个了,从测试中来看,<h5>这些方法的调用并不是开销很低,是根本就没有开销!</h5>方法调用(还有为了可读性而加的文档)只存在于你的源代码和编译后的字节码里,运行时它们完全被清除掉了(内联了)。
我对第二个结果也不太理解。看起来性能高的机器B运行单个方法调用的时候要快点,另两个就要慢些。也许它倾向于延迟进行内联?结果是有些不同,不过差距也不是那么的大。就像优化栈跟踪信息生成那样——如果你为了优化代码性能,手动进行内联,把方法越搞越庞大,越弄越复杂,那你就真的错了。
更多文章请访问:deepinmind
- JVM方法内联
- JVM 方法内联
- JVM方法内联
- JVM 方法内联 提高性能
- 深入理解java虚拟机(十四)正确利用 JVM 的方法内联
- c++语言 内联方法
- GCC内联汇编调试方法
- java 动态编译 方法内联
- 内联
- 内联
- <重构>读书笔记之<内联化方法>
- 类成员方法的内联写法
- java final方法与java内联函数
- 内联元素 垂直居中 实现方法
- C 内联汇编方法 __asm__ __volatile__
- JVM中方法区
- JVM 方法区
- JVM 崩溃分析方法
- sizeof理解
- XML 命名空间(XML Namespaces)
- android Theme使用二
- EasyGame网络游戏服务器解决方案
- 什么是“以管理员身份运行”
- JVM方法内联
- POJ 2796 Feel Good (单调栈)
- Web service是什么?
- CEdit重绘垂直居中显示
- C语言经典算法100例-016-求最大公约数和最小公倍数
- Linux 第一课 学习的方向
- synchronized详解
- 计算几何三维模板
- 数据结构 -- 查找之 二分法查找


