关于Buddy(伙伴)算法的讨论
来源:互联网 发布:sql查询去重 编辑:程序博客网 时间:2024/05/15 15:14
对伙伴系统种的位图的作用没有搞的清楚
就是说:系统在确定一个块的伙伴块是否是空闲时,是在空闲链表种查找有无
伙伴块呢还是利用位图种的状态来判断,
总觉得是和位图有关,可是位图中的一位表示一对伙伴块的状态
又觉得好象信息不太够用。
当位图中的一位为0,表示两块都空或都闲
当位图中的一位为1,表示有一块为忙
哪位大侠能详细谈谈位图的动作哪?
到底是怎么异或的?
位图的某位对应于两个伙伴块,为1就表示其中一块忙,为0表示两块都闲。
所谓异或,是指刚开始两块都闲为0,后来其中一块用了异或一下得1,后来另一块也用
了异或一下得0,后来前面一块回收了异或一下得1,后来另一块也回收了异或一下得0,
这样(如果为1就不合并)就又可以和前面一块合并成一大块了。
位图的主要用途是在回收算法中指示是否可以和伙伴块合并,分配时只要搜索空闲链表
就足够了。当然,分配的同时还要对相应位异或一下了,这是为回收算法服务。
讲的太好了,一下清楚了许多,谢谢了。
我对分配时相应的位异或这个地方还有点晕,就是说对位图的位异或时
是只对该大小队列的位图进行呢?还是所有10条中可能用到该块的都进行处理呢?
比如说:4页这个位置,如果是1页大小的块,其伙伴块是第5页,如果是2页大小的块时
其伙伴块是6,7页组成的,如果是4页大小的块时,其伙伴块是以0页大头的块
那么当第4页(一页大小)回收时(或释放时),其一页大小队列的位图肯定是处理了
那么其它大小的位图是否变化呢?比方说第二条队列位图的第2位是不是也要异或呀?
总感觉不太连冠似的
就拿你的例子来说明吧。
对于回收算法:
1. 当回收序号为4的1页块时,先找到order为0的area,把该页面块加入到该area的空闲
链表中,然后判断其伙伴块(序号为5的1页块)的状态,读该area(不是其它area! )
的map的第2位( 4>>(1+order) ),假设伙伴块被占,则该位为0(回收4块前,4、5块
都忙),现异或一下得1,并不再向上合并。
2. 当回收序号为5的1页块时,同理,先找到order为0的area,把该页面块加入到该are
a的空闲链表中,然后判断其伙伴块(序号为4的1页块)的状态,读该area的map的第2位
( 5>>(1+order) ), 这时该位为1(4块已回收),现异或一下得0,并向上合并,把序
号为4的1页块和序号为5的1页块从该area的空闲链表中摘除,合并成序号为4的2页块,
并放到order为1的area的空闲链表中。同理,此时又要判断合并后的块的伙伴块(序号
为6的2页块)的状态,读该area( order为1的area,不是其它! ) 的map的第1位(
4>>(1+order) ),假设伙伴块在此之前已被回收,则该位为1,现异或一下得0,并向上
合并,把序号为4的2页块和序号为6的2页块从order为1的area的空闲链表中摘除,合并
成序号为4的4页块,并放到order为2的area的空闲链表中。然后再判断其伙伴块状态,
如此反复。
本来还想再说一下分配算法的,发现已经这么多了,我想也应该能明白了。
多谢了,现在清楚了许多
看来:
1。通过异或后是否为0判断是否继续向上合并
2。初始状态位图为全0
3。每次无论分配还是回收,都只对相应大小的位图处理(在没有分裂或合并的情况)
而并不是同时处理全部10条队列的。
现在再来举例谈一谈分配算法。
假设在初始阶段,全是大小为2^9大小的块( MAX_ORDER为10),序号依次为0, 512, 1
024等等,并且所有area的map位都为0(实际上操作系统代码要占一部分空间,但这里只
是举例),现在要分配一个2^3大小的页面块,有以下动作:
1. 从order为3的area的空闲链表开始搜索,没找到就向高一级area搜索,依次类推,按
照假设条件,会一直搜索到order为9的area,找到了序号为0的2^9页块。
2. 把序号为0的2^9页块从order为9的area的空闲链表中摘除并对该area的第0位( 0>>
(1+9) )异或一下得1。
3. 把序号为0的2^9页块拆分成两个序号分别为0和256的2^8页块,前者放入order为8的
area的空闲链表中,并对该area的第0位( 0>>(1+8) )异或一下得1。
4. 把序号为256的2^8页块拆分成两个序号分别为256和384的2^7页块,前者放入order为
7的area的空闲链表中,并对该area的第1位( 256>>(1+7) )异或一下得1。
5. 把序号为384的2^7页块拆分成两个序号分别为384和448的2^6页块,前者放入order为
6的area的空闲链表中,并对该area的第3位( 384>>(1+6) )异或一下得1。
6. 把序号为448的2^6页块拆分成两个序号分别为448和480的2^5页块,前者放入order为
5的area的空闲链表中,并对该area的第7位( 448>>(1+5) )异或一下得1。
7. 把序号为480的2^5页块拆分成两个序号分别为480和496的2^4页块,前者放入order为
4的area的空闲链表中,并对该area的第15位( 480>>(1+4) )异或一下得1。
8. 把序号为496的2^4页块拆分成两个序号分别为496和504的2^3页块,前者放入order为
3的area的空闲链表中,并对该area的第31位( 496>>(1+3) )异或一下得1。
9. 序号为504的2^3页块就是所求的块。
如果有兴趣可以分配和回收一起演算举例,我就不再赘述。
伙伴(buddy)算法的页面释放过程
2.4版内核的页分配器引入了"页区"(zone)结构, 一个页区就是一大块连续的物理页面. Linux 2.4将整个物理内存划分为3个页区, DMA页区(ZONE_DMA), 普通页区(ZONE_NORMAL)和高端页区(ZONE_HIGHMEM). 页区可以使页面分配更有目的性, 有利于减少内存碎片. 每个页区的页分配仍使用伙伴(buddy)算法. 伙伴算法将整个页区划分为以2为幂次的各级页块的集合, 相邻的同次页块称为伙伴, 一对伙伴可以合并到更高次页面集合中去.下面分析一下伙伴算法的页面释放过程.; mm/page_alloc.c:#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->offset) || (((x)-mem_map) >= (zone)->offset+(zone)->size))#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))#define put_page_testzero(p) atomic_dec_and_test(&(p)->count)void free_pages(unsigned long addr, unsigned long order){ order是页块尺寸指数, 即页块的尺寸有(2^order)页. if (addr != 0) __free_pages(virt_to_page(addr), order);}void __free_pages(struct page *page, unsigned long order){ if (!PageReserved(page) && put_page_testzero(page)) __free_pages_ok(page, order);}static void FASTCALL(__free_pages_ok (struct page *page, unsigned long order));static void __free_pages_ok (struct page *page, unsigned long order){ unsigned long index, page_idx, mask, flags; free_area_t *area; struct page *base; zone_t *zone; if (page->buffers) BUG(); if (page->mapping) BUG(); if (!VALID_PAGE(page)) BUG(); if (PageSwapCache(page)) BUG(); if (PageLocked(page)) BUG(); if (PageDecrAfter(page)) BUG(); if (PageActive(page)) BUG(); if (PageInactiveDirty(page)) BUG(); if (PageInactiveClean(page)) BUG(); page->flags &= ~((1<< page->age = PAGE_AGE_START; zone = page->zone; 取page所在的页区 mask = (~0UL) << order; 求页面指数的掩码 base = mem_map + zone->offset; 求页区的起始页 page_idx = page - base; 求page在页区内的起始页号 if (page_idx & ~mask) 页号必须在页块尺寸边界上对齐 BUG(); index = page_idx >> (1 + order); ; 求页块在块位图中的索引, 每一索引位置代表相邻两个"伙伴" area = zone->free_area + order; 取该指数页块的位图平面 spin_lock_irqsave(&zone->lock, flags); zone->free_pages -= mask; 页区的自由页数加上将释放的页数(掩码值为负) while (mask + (1 << (MAX_ORDER-1))) { 当mask所遮掩的位长为(MAX_ORDER-1)时,和恰好为零,即达到了最大块指数 struct page *buddy1, *buddy2; if (area >= zone->free_area + MAX_ORDER) 如果超过了最高次平面 BUG(); if (!test_and_change_bit(index, area->map)) 测试并取反页块的索引位 /* * the buddy page is still allocated. */ break; 如果原始位为0, 则说明该页块原来没有伙伴, 操作完成 /* * Move the buddy up one level. 如果原始位为1, 则说明该页块存在一个伙伴 */ buddy1 = base + (page_idx ^ -mask); 对页块号边界位取反,得到伙伴的起点 buddy2 = base + page_idx; if (BAD_RANGE(zone,buddy1)) 伙伴有没有越过页区范围 BUG(); if (BAD_RANGE(zone,buddy2)) BUG(); memlist_del(&buddy1->list); 删除伙伴的自由链 mask <<= 1; 求更高次掩码 area++; 求更高次位图平面 index >>= 1; 求更高次索引号 page_idx &= mask; 求更高次页块的起始页号 } memlist_add_head(&(base + page_idx)->list, &area->free_list); 将求得的高次页块加入该指数的自由链 spin_unlock_irqrestore(&zone->lock, flags); /* * We don't want to protect this variable from race conditions * since it's nothing important, but we do want to make sure * it never gets negative. */ if (memory_pressure > NR_CPUS) memory_pressure--;}伙伴(buddy)算法的页面释放过程 2.4版内核的页分配器引入了"页区"(zone)结构, 一个页区就是一大块连续的物理页面. Linux 2.4将整个物理内存划分为3个页区, DMA页区(ZONE_DMA), 普通页区(ZONE_NORMAL)和高端页区(ZONE_HIGHMEM). 页区可以使页面分配更有目的性, 有利于减少内存碎片. 每个页区的页分配仍使用伙伴(buddy)算法. 伙伴算法将整个页区划分为以2为幂次的各级页块的集合, 相邻的同次页块称为伙伴, 一对伙伴可以合并到更高次页面集合中去.下面分析一下伙伴算法的页面释放过程.; mm/page_alloc.c:#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->offset) || (((x)-mem_map) >= (zone)->offset+(zone)->size))#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))#define put_page_testzero(p) atomic_dec_and_test(&(p)->count)void free_pages(unsigned long addr, unsigned long order){ order是页块尺寸指数, 即页块的尺寸有(2^order)页. if (addr != 0) __free_pages(virt_to_page(addr), order);}void __free_pages(struct page *page, unsigned long order){ if (!PageReserved(page) && put_page_testzero(page)) __free_pages_ok(page, order);}static void FASTCALL(__free_pages_ok (struct page *page, unsigned long order));static void __free_pages_ok (struct page *page, unsigned long order){ unsigned long index, page_idx, mask, flags; free_area_t *area; struct page *base; zone_t *zone; if (page->buffers) BUG(); if (page->mapping) BUG(); if (!VALID_PAGE(page)) BUG(); if (PageSwapCache(page)) BUG(); if (PageLocked(page)) BUG(); if (PageDecrAfter(page)) BUG(); if (PageActive(page)) BUG(); if (PageInactiveDirty(page)) BUG(); if (PageInactiveClean(page)) BUG(); page->flags &= ~((1<< page->age = PAGE_AGE_START; zone = page->zone; 取page所在的页区 mask = (~0UL) << order; 求页面指数的掩码 base = mem_map + zone->offset; 求页区的起始页 page_idx = page - base; 求page在页区内的起始页号 if (page_idx & ~mask) 页号必须在页块尺寸边界上对齐 BUG(); index = page_idx >> (1 + order); ; 求页块在块位图中的索引, 每一索引位置代表相邻两个"伙伴" area = zone->free_area + order; 取该指数页块的位图平面 spin_lock_irqsave(&zone->lock, flags); zone->free_pages -= mask; 页区的自由页数加上将释放的页数(掩码值为负) while (mask + (1 << (MAX_ORDER-1))) { 当mask所遮掩的位长为(MAX_ORDER-1)时,和恰好为零,即达到了最大块指数 struct page *buddy1, *buddy2; if (area >= zone->free_area + MAX_ORDER) 如果超过了最高次平面 BUG(); if (!test_and_change_bit(index, area->map)) 测试并取反页块的索引位 /* * the buddy page is still allocated. */ break; 如果原始位为0, 则说明该页块原来没有伙伴, 操作完成 /* * Move the buddy up one level. 如果原始位为1, 则说明该页块存在一个伙伴 */ buddy1 = base + (page_idx ^ -mask); 对页块号边界位取反,得到伙伴的起点 buddy2 = base + page_idx; if (BAD_RANGE(zone,buddy1)) 伙伴有没有越过页区范围 BUG(); if (BAD_RANGE(zone,buddy2)) BUG(); memlist_del(&buddy1->list); 删除伙伴的自由链 mask <<= 1; 求更高次掩码 area++; 求更高次位图平面 index >>= 1; 求更高次索引号 page_idx &= mask; 求更高次页块的起始页号 } memlist_add_head(&(base + page_idx)->list, &area->free_list); 将求得的高次页块加入该指数的自由链 spin_unlock_irqrestore(&zone->lock, flags); /* * We don't want to protect this variable from race conditions * since it's nothing important, but we do want to make sure * it never gets negative. */ if (memory_pressure > NR_CPUS) memory_pressure--;}在Webus空间管理组件(WSM)中, 我也提供了Buddy System的实现, 关于这种算法的详细描述, 建议大家看经典教材 " 数据结构" 一书第8章第4节.
 呵呵, 蓝色经典!
呵呵, 蓝色经典!我在此仅谈谈如下三个问题:
1. Buddy System的基本原理?
2. 如何分配空间?
3. 如何回收空间?
对以上三个问题的说明:
Buddy System把系统中的可用存储空间划分为存储块(Block)来进行管理, 每个存储块的大小必须是2的n次幂(Pow(2, n)), 即1, 2, 4, 8, 16, 32, 64, 128...
假设系统全部可用空间为Pow(2, k), 那么在Buddy System初始化时将生成一个长度为k + 1的可用空间表List, 并将全部可用空间作为一个大小为Pow(2, k)的块挂接在List的最后一个节点上, 如下图:

当用户申请size个字的存储空间时, Buddy System分配的Block大小为Pow(2, m)个字大小(Pow(2, m-1) < size < Pow(2, m)).
此时Buddy System将在List中的m位置寻找可用的Block. 显然List中这个位置为空, 于是Buddy System就开始寻找向上查找m+1, m+2, 直到达到k为止. 找到k后, 便得到可用Block(k), 此时Block(k)将分裂成两个大小为Pow(k-1)的块, 并将其中一个插入到List中k-1的位置, 同时对另外一个继续进行分裂. 如此以往直到得到两个大小为Pow(2, m)的块为止, 如下图所示:
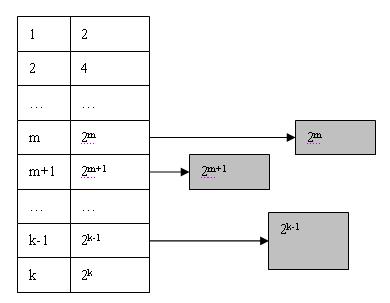
如果系统在运行一段时间之后, List中某个位置n可能会出现多个块, 则将其他块依次链接可用块链表的末尾:

当Buddy System要在n位置取可用块时, 直接从链表头取一个就行了.
当一个存储块不再使用时, 用户应该将该块归还给Buddy System. 此时系统将根据Block的大小计算出其在List中的位置, 然后插入到可用块链表的末尾. 在这一步完成后, 系统立即开始合并操作. 该操作是将"伙伴"合并到一起, 并放到List的下一个位置中, 并继续对更大的块进行合并, 直到无法合并为止.
何谓"伙伴"? 如前所述, 在分配存储块时经常会将一个大的存储块分裂成两个大小相等的小块, 那么这两个小块就称为"伙伴".在Buddy System进行合并时, 只会将互为伙伴的两个存储块合并成大块, 也就是说如果有两个存储块大小相同, 地址也相邻, 但是不是由同一个大块分裂出来的, 也不会被合并起来. 正常情况下, 起始地址为p, 大小为Pow(2, k)的存储块, 其伙伴块的起始地址为: p + Pow(2, k) 和 p - Pow(2, k).
下面把数据结构一书中Buddy算法分配存储块的C++伪码帖出来以供大家参考:
 Space AllocBuddy(FreeList &avail, int n)
Space AllocBuddy(FreeList &avail, int n)

 {
{ //avail[0..m]为可利用空间表, n为申请分配量, 若有不小于n的空闲块, //则分配相应的存储块, 并返回其首地址, 否则返回NULL for(k=0; k<=m && (avail[k].nodesize < n+1 || !avail[k].first); ++k);//查找满足分配要求的子表 if(k>m) return NULL;//分配失败, 返回NULL;
//avail[0..m]为可利用空间表, n为申请分配量, 若有不小于n的空闲块, //则分配相应的存储块, 并返回其首地址, 否则返回NULL for(k=0; k<=m && (avail[k].nodesize < n+1 || !avail[k].first); ++k);//查找满足分配要求的子表 if(k>m) return NULL;//分配失败, 返回NULL;
 else {//可进行分配 pa = avail[k].first;//指向可分配子表的第一个节点 pre = pa->llink; suc = pa->rlink;//分配指向前驱和后继 if(pa == suc) avail[k].first = NULL;//分配后该子表变为空表 else {//从子表删除*pa节点 pre->rlink = suc; suc->llink = pre; avail[k].first = suc;
else {//可进行分配 pa = avail[k].first;//指向可分配子表的第一个节点 pre = pa->llink; suc = pa->rlink;//分配指向前驱和后继 if(pa == suc) avail[k].first = NULL;//分配后该子表变为空表 else {//从子表删除*pa节点 pre->rlink = suc; suc->llink = pre; avail[k].first = suc; } } for(i = 1; avail[k-i].nodesize >= n+1; ++i) { pi = pa + pow(2, k-i); pi-> rlink = pi; pi ->llink = pi; pi -> tag = 0; pi -> kval = k-i; avail[k-i].first = pi; }//将剩余块插入相应子表 pa -> tag = 1; pa -> kval = k-(--i); return pa;
} } for(i = 1; avail[k-i].nodesize >= n+1; ++i) { pi = pa + pow(2, k-i); pi-> rlink = pi; pi ->llink = pi; pi -> tag = 0; pi -> kval = k-i; avail[k-i].first = pi; }//将剩余块插入相应子表 pa -> tag = 1; pa -> kval = k-(--i); return pa; }
}
关于存储块回收算法, 书上没有现成的, 日后笑侃一定提供给大家, 呵呵, 今日工作繁忙, 精力不济, 要挂起了. 感谢大家的关注!
3.4 页面分配与回收
对系统中物理页面的请求十分频繁。例如当一个可执行映象被调入内存时,操作系统必须为其分配页面。当映象执行完毕和卸载时这些页面必须被释放。物理页面的另一个用途是存储页表这些核心数据结构。虚拟内存子系统中负责页面分配与回收的数据结构和机制可能用处最大。
系统中所有的物理页面用包含mem_map_t结构的链表mem_map来描叙,这些结构在系统启动时初始化。每个 mem_map_t描叙了一个物理页面。其中与内存管理相关的重要域如下:
count
- 记录使用此页面的用户个数。当这个页面在多个进程之间共享时,它的值大于1。
- age
- 此域描叙页面的年龄,用于选择将适当的页面抛弃或者置换出内存时。
- map_nr
- 记录本mem_map_t描叙的物理页面框号。
页面分配代码使用free_area数组来寻找和释放页面,此机制负责整个缓冲管理。另外此代码与处理器使用的页面大小和物理分页机制无关。
free_area中的每个元素都包含页面块的信息。数组中第一个元素描叙1个页面,第二个表示2个页面大小的块而接下来表示4个页面大小的块,总之都是2的次幂倍大小。list域表示一个队列头,它包含指向mem_map数组中page数据结构的指针。所有的空闲页面都在此队列中。map域是指向某个特定页面尺寸的页面组分配情况位图的指针。当页面的第N块空闲时,位图的第N位被置位。
图free-area-figure画出了free_area结构。第一个元素有个自由页面(页面框号0),第二个元素有4个页面大小的2个自由块,前一个从页面框号4开始而后一个从页面框号56开始。
3.4.1 页面分配
Linux使用Buddy算法来有效的分配与回收页面块。页面分配代码每次分配包含一个或者多个物理页面的内存块。页面以2的次幂的内存块来分配。这意味着它可以分配1个、2个和4个页面的块。只要系统中有足够的空闲页面来满足这个要求(nr_free_pages > min_free_page),内存分配代码将在free_area中寻找一个与请求大小相同的空闲块。free_area中的每个元素保存着一个反映这样大小的已分配与空闲页面 的位图。例如,free_area数组中第二个元素指向一个反映大小为四个页面的内存块分配情况的内存映象。
分配算法首先搜寻满足请求大小的页面。它从free_area数据结构的list域着手沿链来搜索空闲页面。如果没有这样请求大小的空闲页面,则它搜索两倍于请求大小的内存块。这个过程一直将持续到free_area 被搜索完或找到满足要求的内存块为止。如果找到的页面块大于请求的块则对其进行分割以使其大小与请求块匹配。由于块大小都是2的次幂所以分割过程十分简单。空闲块被连进相应的队列而这个页面块被分配给调用者。

在图3.4中,当系统中有大小为两个页面块的请求发出时,第一个4页面大小的内存块(从页面框号4开始)将分成两个2页面大小的块。前一个,从页面框号4开始的,将分配出去返回给请求者,而后一个,从页面框号6开始,将被添加到free_area数组中表示两个页面大小的空闲块的元素1中。
3.4.2 页面回收
将大的页面块打碎进行分配将增加系统中零碎空闲页面块的数目。页面回收代码在适当时机下要将这些页面结合起来形成单一大页面块。事实上页面块大小决定了页面重新组合的难易程度。
当页面块被释放时,代码将检查是否有相同大小的相邻或者buddy内存块存在。如果有,则将它们结合起来形成一个大小为原来两倍的新空闲块。每次结合完之后,代码还要检查是否可以继续合并成更大的页面。最佳情况是系统的空闲页面块将和允许分配的最大内存一样大。
在图3.4中,如果释放页面框号1,它将和空闲页面框号0结合作为大小为2个页面的空闲块排入free_area的第一个元素中。
3.5 内存映射
映象执行时,可执行映象的内容将被调入进程虚拟地址空间中。可执行映象使用的共享库同样如此。然而可执行文件实际上并没有调入物理内存,而是仅仅连接到进程的虚拟内存。当程序的其他部分运行时引用到这部分时才把它们从磁盘上调入内存。将映象连接到进程虚拟地址空间的过程称为内存映射。

图3.5 虚拟内存区域
每个进程的虚拟内存用一个mm_struct来表示。它包含当前执行的映象(如BASH)以及指向vm_area_struct 的大量指针。每个vm_area_struct数据结构描叙了虚拟内存的起始与结束位置,进程对此内存区域的存取权限以及一组内存操作函数。这些函数都是Linux在操纵虚拟内存区域时必须用到的子程序。其中一个负责处理进程试图访问不在当前物理内存中的虚拟内存(通过页面失效)的情况。此函数叫nopage。它用在Linux试图将可执行映象的页面调入内存时。
可执行映象映射到进程虚拟地址时将产生一组相应的vm_area_struct数据结构。每个vm_area_struct数据结构表示可执行映象的一部分:可执行代码、初始化数据(变量)、未初始化数据等等。Linux支持许多标准的虚拟内存操作函数,创建vm_area_struct数据结构时有一组相应的虚拟内存操作函数与之对应
空洞、buddy算法及extendable hash
UNIX 文件中可以包含有空洞(holes)。如果一个用户创建了一个文件,然后将文件指针 调整到一个很大的偏移(通过调用lseek 可在打开文件对象中设置偏移指针,再往里写入数据。这样,该偏移前的空间中就没有数据因此使形成了一个“空洞”。如果一个进程试图从文件“空洞”处读取数据,它将得到全零字节。文件“空洞”有时候会很大,甚至整个磁盘块都是“空洞”。为这样的磁盘块分配空间,无疑是很浪费的。解决方法是内核将di_addr 数组的相应表项(既可能是直接块,也可能是间接块)置为零。当用户试图读这样一个块时,内核将充满0 的块返回给用户。只有当有人试图往这个块里写数据时内核才分配磁盘空间。拒绝为空洞分配空间有很重要的意义。一个进程在试图往空洞里写数据时可能意外地超出了磁盘空间。如果复制一个包含空洞的文件,新文件在磁盘上可能会有充满零的页,而不是预期的空洞。这是因为复制文件要先从源文件中读出内容,然后写到目的文件中。当内核读取一个空洞时,它创建了一个充满零的页,然后该页会被原样复制到目的文件中去。这样,一些像tar 或cpio 之类的在文件级而非原始磁盘级上操作的备份和归档工具便会出现问题。系统管理员可能要为一个文件系统作备份,可是他会发现复制的数据在相同磁盘上却没有足够的空间来恢复。
buddy算法
buddy算法是用来做内存管理的经典算法,目的是为了解决内存的外碎片。
避免外碎片的方法有两种:1,利用分页单元把一组非连续的空闲页框映射到非连续的线性地址区间。2,开发适当的技术来记录现存的空闲连续页框块的情况,以尽量避免为满足对小块的请求而把大块的空闲块进行分割。
基于下面三种原因,内核选择第二种避免方法:1,在某些情况下,连续的页框确实必要。2,即使连续页框的分配不是很必要,它在保持内核页表不变方面所起的作用也是不容忽视的。假如修改页表,则导致平均访存次数增加,从而频繁刷新TLB。3,通过4M的页可以访问大块连续的物理内存,相对于4K页的使用,TLB未命中率降低,加快平均访存速度。
buddy算法将所有空闲页框分组为10个块链表,每个块链表分别包含1,2,4,8,16,32,64,128,256,512个连续的页框,每个块的第一个页框的物理地址是该块大小的整数倍。如,大小为16个页框的块,其起始地址是16*2^12的倍数。
例,假设要请求一个128个页框的块,算法先检查128个页框的链表是否有空闲块,如果没有则查256个页框的链表,有则将256个页框的块分裂两份,一份使用,一份插入128个页框的链表。如果还没有,就查512个页框的链表,有的话就分裂为128,128,256,一个128使用,剩余两个插入对应链表。如果在512还没查到,则返回出错信号。
回收过程相反,内核试图把大小为b的空闲伙伴合并为一个大小为2b的单独快,满足以下条件的两个块称为伙伴:1,两个块具有相同的大小,记做b;2,它们的物理地址是连续的,3,第一个块的第一个页框的物理地址是2*b*2^12的倍数,该算法迭代,如果成功合并所释放的块,会试图合并2b的块来形成更大的块。
extendable hash
使用hash的好处在于它能够直接定位索引的数据,但当数据动态添加删除时,就会有如何安置新加入的数据和回收多余的空间的问题。
动态hash算法可以解决利用hash对数据添加删除时所遇到的问题。有关extendable hash的解释可见
http://www.cs.sfu.ca/CC/354/zaiane/material/notes/Chapter11/node20.html
有空再写个详细些的解释吧
各种书籍中介绍的都很详细,不再赘述,只提出一个值得注意的问题.
关键函数如下: (在/linux/mm/page_alloc.c中)
static FASTCALL(struct page * rmqueue(zone_t *zone, unsigned long order));
static struct page * rmqueue(zone_t *zone, unsigned long order)
{
free_area_t * area = zone->free_area + order; //根据页框数(对2的幂数)找到对应的空闲页链表
unsigned long curr_order = order;
struct list_head *head, *curr;
unsigned long flags;
struct page *page;
spin_lock_irqsave(&zone->lock, flags);
do {
head = &area->free_list; //head指向链表头
curr = memlist_next(head); //指向链表中下一页块的对应page结构中的list域指针
if (curr != head) {
unsigned int index;
page = memlist_entry(curr, struct page, list); //由上面得到的list地址得到指向对应page结构的指针
if (BAD_RANGE(zone,page))
BUG();
memlist_del(curr); //将该页块从链标中脱离
index = (page - mem_map) - zone->offset;
MARK_USED(index, curr_order, area); //改变页位图数组中的相应位
//注意:对于每个页块大小为2^i 个页框的队列,其位图数组每一位表示相邻的两个页块(符合buddy标准的两个相邻页块)的使用情况;
//为1表示其中一个页块已被使用,一个页块空闲;为0表示两个页块同时空闲或同时已被使用。所以MARK_USED宏调用change_bit
时的一个参数是index>>(1+order)
//而不是index>>(1+order)
zone->free_pages -= 1 << order; //调整空闲页记数
page = expand(zone, page, index, order, curr_order, area);
//若分配的页块中的页数>需求,将多余的页(位于页块的开头部分)插入相应的一个或几个队列中
//返回实际分得的页块指针,放在page中
spin_unlock_irqrestore(&zone->lock, flags);
set_page_count(page, 1); //分配得到的页块标记使用记数为1
if (BAD_RANGE(zone,page))
BUG();
DEBUG_ADD_PAGE
return page; //已分配成功,返回页块指针
}
curr_order++;
//否则当前链表中已无空闲页块,向上一级链表中寻求(更大的页块),进入下一轮循环
area++;
} while (curr_order < MAX_ORDER);
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
#define MARK_USED(index, order, area) \
change_bit((index) >> (1+(order)), (area)->map)
Linux内核中buddy算法的实现在一些相关书籍《linux内核2.4版源代码分析大全》包括新近出版的《操作系统原理·技术与编程》等书中都有介绍,但是其中对
空闲页链表中的页块位图的表述都值得斟酌,以上两书在表述页位图数组时都说页位图数组中每一位表示该页块的使用情况,为1则被占用,为0则空闲。
这种说法其实想想也有漏洞,因为空闲页链表中的页块自然都是空闲的,还要位图作甚?
看了MARK_USED(index, order, area) 宏的实现后可看出每位表示的是相邻两个buddy页块的使用情况(为1则一个空闲一个使用,为0则两个都空闲或都使用),位图的作用是当空闲页块插入某个链表时,系统根据位图相应位能很容易得知另一个页块是否空闲,从而决定是不是需要将两个buddy页块合并后插入到上一级链表。
编辑者: xuweii (04-02-07 18:48)
mm/page_alloc.c --第二部分, buddy系统 [re: hyl]
II)Buddy 算法核心 最后开始理解最终要的buddy系统,为了说明白算法到底如何工作,我们先来引入 几个重要的概念: 1)某组page: 假设order是2,则page_idx是0-3的是一组,4-7是一组.组中最低地址的那个页 面代表这个组连接进area的list链表,并且组内其他page不会存在于其他任何area 的list。 2)组对(相关组): area中有两个重要的数据结构: (1)list : 属于此order(area)的pgae,或者page组的链表 (2)*map : 每一位代表一对相关组(buddy)。所谓相关组就是可以合并成更高 order的两个连续page组,我们也称之为相关组. map中的组对bit位的意义我们暂且不说,当释放时0代表这对相关组的其中一组还 在使用,无法合并,如果释放是1则代表可以合并。初始值是0,对应的list也为空。 map中bit的意义对于理解buddy算法很有好处,可惜一直未能彻底搞明白,这次希 望运气好些. 通过对初始化的分析看看map中bit位的变化: 1)初始为0,也代表配对page无法合并吗?(显然不是)list也为空.内存初始化调用所 有页面的释放函数,挂入area0 的list,对应位置1. 2)配对的page释放后对应位又变成0,从list摘出先释放的那个一齐放入area1.(如果 重复释放某个page,page组,就会出现严重错误) 3)分配的时候,从areaX的list中出队,mapbit从0变成1,如果这时释放刚分配的page, 1代表可以合并.如果另一个组也分配出去了,位图又变成0,代表释放的时候不能合并. 此时不会在分配这两个组了,因为list中这两个组都已经出队. 所以,操作顺序,bitmap,和list相互配合完成buddy的管理. 仔细考虑,总结一下,map中的bit含义其实是: 0,相关组的状态一致 1,相关组的状态不同 (god,是个异或) 所以分配的时候反转两次,释放的时候反转两次.在看上面的分析: 1)初始为0,连个页面都处于使用中. 释放其中一个的时候,bit为0,代表状态相同,即 都在使用中(我们是在释放啊),我们释放完成后当然无法合并.同时我们释放其中一个 后反转bit,bit变成1,代表现在状态不同了. 2)当配对的一个释放时,发现bit是1,代表状态不同.因为这在使用中,所以另一个已经 释放,故这个释放后就可以合并了.这就是为什么释放时bit为0代表可以合并. 3)请自己分析。 Buddy算法的核心函数之一,__free_pages_ok:释放page组,根据bitmap判断buddy page组的状态,合并buddy page组到更高的order. /* * Buddy system. Hairy. You really aren't expected to understand this * (真的不期望你们理解这段代码---原作者) * Hint: -mask = 1+~mask */ static void FASTCALL(__free_pages_ok (struct page *page, unsigned long order)); static void __free_pages_ok (struct page *page, unsigned long order) { unsigned long index, page_idx, mask, flags; free_area_t *area; struct page *base; zone_t *zone; //要释放的页面不能再有任何人使用了 if (page->buffers) BUG(); ..........//省略 //清除ref,diry位,恢复其初始生命值 page->flags &= ~((1<<PG_referenced) |(1<<PG_dirty)); page->age = PAGE_AGE_START; zone = page->zone; mask = (~0UL) << order; // like: 111111110000,此order的mask base = mem_map + zone->offset; page_idx = page - base; if (page_idx & ~mask) //~mask: 0000000001111, BUG();// page_idx 必须是2^order的整倍数,xxxxxxxx0000 index = page_idx >> (1 + order);//index是指代表page_idx所指组对 //的位图索引,所以是idx>>order>>1 area = zone->free_area + order; spin_lock_irqsave(&zone->lock, flags); zone->free_pages -= mask; //-mask :00010000,2^order while (mask + (1 << (MAX_ORDER-1))) {//11xxxx00+001000000=000xxx00 struct page *buddy1, *buddy2; if (area >= zone->free_area + MAX_ORDER) BUG(); if (!test_and_change_bit(index, area->map)) //释放时如果为0,代表另一组还在使用中,并反转对应位 /* * the buddy page is still allocated. */ break; /* * Move the buddy up one level. */ buddy1 = base + (page_idx ^ -mask);color=blue>//-mask:00010000,疑惑取得另一个组 buddy2 = base + page_idx; if (BAD_RANGE(zone,buddy1)) BUG(); if (BAD_RANGE(zone,buddy2)) BUG(); memlist_del(&buddy1->list); mask <<= 1; //11xxxx00->11xxx000,更大的一个order area++; index >>= 1; page_idx &= mask;//新order下代表组对的页面索引 //(清除一个bit,既,idx值小的那个组) } memlist_add_head(&(base + page_idx)->list, &area->free_list); spin_unlock_irqrestore(&zone->lock, flags); ...... } Buddy系统的另一个核心函数,expand:当指定的order,low无页面可以分配的时候 从oredr为high的area分配,将high中一个页面组依次向低order的area拆分,一次一 半,直至order为low的那个area为止.如,我们要order为1的页面组,从order为3的开 始分配, 8=4+2+(2),(2)代表我们所要的页面组. static inline struct page * expand (zone_t *zone, struct page *page, unsigned long index, int low, int high, free_area_t * area) { //low :目标order high: 从此order的area分配 //page: order为high 的页面组 //index:page组在order为high的area中的位图索引 unsigned long size = 1 << high; while (high > low) {//分解到low if (BAD_RANGE(zone,page)) BUG(); area--; //lower area high--; //lower order size >>= 1;//size 减半 memlist_add_head(&(page)->list,&(area)->free_list);//将拆分的头一个组 //入低级别的area MARK_USED(index, high, area);color=blue>//在此低级别的area中反转状态 index += size;//低一个order的位图索引 page += size; //留下同一对的后一个组分配给用户 } if (BAD_RANGE(zone,page)) BUG(); return page; } 分析完expand后对于rmqueue应该不难了: static struct page * rmqueue(zone_t *zone, unsigned long order) { free_area_t * area = zone->free_area + order; unsigned long curr_order = order; struct list_head *head, *curr; unsigned long flags; struct page *page; spin_lock_irqsave(&zone->lock, flags); /*only __free_pages_ok show_free_areas_core and this */ do {color=blue>//指定的order可能没有页面了,要依次向高order的area遍历 head = &area->free_list; curr = memlist_next(head); if (curr != head) {//还有页面可以分配 unsigned int index; page = memlist_entry(curr, struct page, list); if (BAD_RANGE(zone,page)) BUG(); memlist_del(curr); index = (page - mem_map) - zone->offset; MARK_USED(index, curr_order, area);//反转状态 zone->free_pages -= 1 << order; page = expand(zone, page, index, order, curr_order, area); spin_unlock_irqrestore(&zone->lock, flags); set_page_count(page, 1); if (BAD_RANGE(zone,page)) BUG(); DEBUG_ADD_PAGE return page; } //如果此order的area无页面就试试高一个order的area curr_order++; area++; } while (curr_order < MAX_ORDER); spin_unlock_irqrestore(&zone->lock, flags); return NULL; }
- 关于Buddy(伙伴)算法的讨论
- 关于Buddy(伙伴)算法的讨论
- Linux伙伴算法(Buddy Allocator)
- 伙伴算法(Buddy)
- 伙伴算法 buddy system
- 操作系统 --- Buddy伙伴算法
- xv6的buddy(伙伴)系统源代码之buddy.h
- 关于缓存文件格式(单文件文件柜)是否适合使用伙伴算法的讨论
- 我看Buddy(伙伴)算法-到底是怎么计算"伙伴"地址的
- 内存管理算法--Buddy伙伴算法
- 内存管理算法--Buddy伙伴算法
- 内存管理算法--Buddy伙伴算法
- 内存管理算法--Buddy伙伴算法
- 【那些年遇到过的面试题】 内存管理算法--Buddy伙伴算法
- Linux kernel memory management buddy system (linux内核内存管理的伙伴算法)
- 我看Buddy(伙伴)算法-到底是怎么"找朋友"的
- 伙伴算法 (Buddy Algorithm)简单描诉和自己的简单实现
- 内存管理之伙伴系统算法(The Buddy System Algorithm)
- http://dongxi.douban.com/article/1056161/
- Android学习之——并发编程:Android进程中的线程
- 向大家请教个问题--怎样获取linux服务器的各个硬盘的大小
- Digital Tv Modulation Type 介绍
- 获取各类硬件ID汇编代码
- 关于Buddy(伙伴)算法的讨论
- linux Gsensor驱动(bma250为例子)
- 汇添富截个图
- LeetCode之Swap Nodes in Pairs
- Spring MVC下载文件
- dtplayer总体设计
- 二叉查找树的典型面试题目汇总
- nyoj-206矩形的个数
- 题目1020:最小长方形


