有关编译原理
来源:互联网 发布:如何查看linux服务器ip 编辑:程序博客网 时间:2024/05/01 14:41
有关编译原理
编译程序的逻辑结构:词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成。六个阶段。
1.词法分析
目的:识别字符串,识别出关键字、数字、运算符、变量名等,以二元式(类别,值)的形式存储,供后续的语法分析器用。
1.1文法:
一个文法可表示成形如G[S]=(Vn,Vt,P,S)的四元式。
Vn:非终结符号集;
Vt:终结符号集;
P:产生式集;
S:文法的开始符号。
文法的分类:分析略,有以下几种。
0型
1型
2型
3型
短语结构文法
前后文有关文法
前后文无关文法
正规文法
确定的有限自动机(DFA)
DFA,Deterministic Finite Automaton。
DFA 用M=(K,∑,f,S0,Z)五元式表示。
K:状态集合;
∑,:符号集合;
f:单值映射,f(p,a)=q:指明若当前的状态为p,而输入字符为a时下一个状态就是q;
S0:一个初始状态,属于K;
Z:若干个结束状态,属于K。
非确定的有限自动机(NFA)
NFA,Non-deterministic Finite Automaton。
NFA 用M=(K,∑,f,S0,Z)五元式表示,同DFA,区别为f可以不是单值映射,即f(p,a)={q1。q2,q3,...}。
NFA与DFA的等价性论证:
1.DFA是特殊的NFA;
2.NFA可等价德转换到DFA。
文法->DFA的步骤:
文法->具有ε动作的NFA->DFA确定化->DFA状态数最小化。
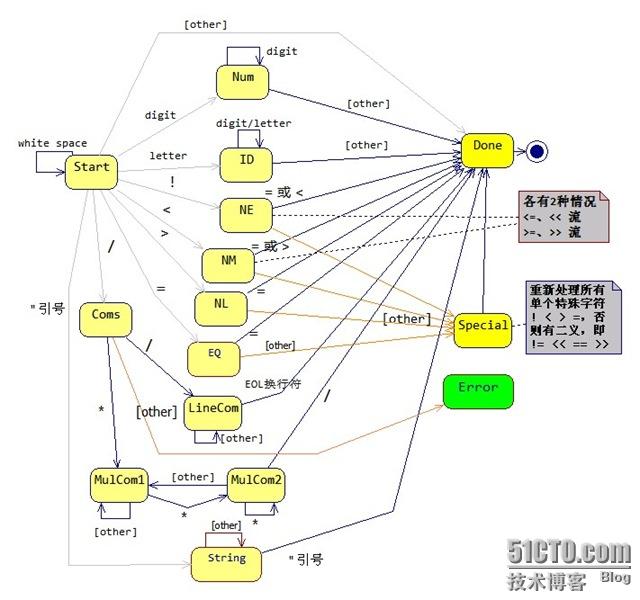
图1-1 词法分析的自动机示意图
1.2正则表达式
又称正规文法,用来描述符合特定文法的字符串。
符号有:
* • |
名字分别叫闭包、连接、或。这三个的优先级依次降低。
正规集:某文法下的全体字符串构成了相应的正规集。
正规式
正规集(ε代表空串)
a|b
{a,b}
a|ba*
{a,b,ba,baa,...}
a*
{ε,a,aa,aaa,...}
(a|b)*abb
任何以abb结尾的a、b符号串
增强版的 正则表达式见:
http://blog.csdn.net/chuchus/article/details/34109787
2.语法分析
以词法分析的二元式作为输入,判断是否合乎特定文法。如int a 后缺少分号,语法分析器会报错。
有自顶向下和自底向上两种思想。对于前者,试着为源程序构造一棵完整的语法树,若成功则无语法错误。
递归下降分析法,属于自顶向下。是指对文法的每一非终结符号,都根据相应产生式各候选式的结构,为其编写一个子程序,用来识别该非终结符号所表示的语法。
该方法要求文法不能有直接左递归。若有,可以对文法进行改造以达到要求。
例:
T->aFb 为语法的一部分,为非终结符号T、F分别构造相应的语法检验函数,T的判别函数见下:
T(){ ...;//判断a
F();//判断F
...;判断b
}//若中间任一环节出错则说明源程序不符合语法规定。
此类函数之间允许相互嵌套和递归。
3.语义分析
较复杂,不详述。通常与语法分析并行进行。
定义函数 void fun(int);调用 fun();时会因参数不去匹配由语义分析器报错。
4.中间代码生成
四则运算表达式的表示方法:后缀表示法。
流程控制语句的翻译:
while(a<b){if(c>d) x=y+z;}
地址
operator
参数一
参数二
结果(地址)
100
j<
a
b
102
101
j
/
/
107
102
j>
c
d
104
103
j
/
/
100
104
+
y
z
tmp
105
=
tmp
/
x
106
j
/
/
100
107
...
...
...
...
5.代码优化及目标代码生成
略。
 消除产生式中的直接左递归是比较容易的。例如假设非终结符P的规则为
消除产生式中的直接左递归是比较容易的。例如假设非终结符P的规则为
P→Pα|β
其中,β是不以P开头的符号串。那么,我们可以把P的规则改写为如下的非直接左递归形式:
P→βP’ P’→αP’|ε
这两条规则和原来的规则是等价的,即两种形式从P推出的符号串是相同的。
- 有关编译原理
- 有关编译原理中的4种文法
- 编译原理:句型分析和有关文法实用的说明
- 有关编译
- 有关编译的问题
- 有关PowerBuilder的编译
- 有关编译的库
- 有关编译的笔记
- 编译原理
- 《编译原理》
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- php正则表达式匹配3
- 蜗牛—Java面试之面向对象(一)
- JavaWeb入门实战—相关知识准备
- 手机免费使用wifi和ChinaNet详细图文教程
- html控件、html服务器控件和web用户控件(onclick,onclientclick和onserverclick的执行顺序)
- 有关编译原理
- 体验常成员函数
- Kivy A to Z -- Kivy的运行机制
- HTML id name
- Android之MediaPlayer
- Android线程间通信的Message机制
- eclipse在线安装JBoss Tool过程
- 二维数组的复制
- Android学习笔记(五)——通过全局变量传递数据


