聚类分析_R语言
来源:互联网 发布:las vegas算法 编辑:程序博客网 时间:2024/05/14 17:22
聚类分析(cluster analysis)是把研究对象(样本或变量)分组成为由类似的对象组成多个类的一种统计方法。聚类结果一般在4-6类,不易太多,或太少。聚类分析目的在于将相似的事物归类,同一类中的个体有较大的相似性,不同类的个体差异性很大。两个个体间(或变量间)的对应程度或联系紧密程度的度量可以用两种方式来测量:1、采用描述个体对(变量对)之间的接近程度的指标,例如“距离”,“距离”越小的个体(变量)越具有相似性;2、采用表示相似程度的指标,例如“相关系数”,“相关系数”越大的个体(变量)越具有相似性。
聚类分析方法包括:系统聚类法、动态聚类法、有序样本聚类法和模糊聚类法等等。本文只介绍较常用的系统聚类法和动态聚类法。
1 系统聚类法
以R基础包自带的鸢尾花(Iris)数据进行聚类分析。分析代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
###### 代码清单 #######
data(iris); attach(iris)
iris.hc <- hclust(dist(iris[,1:4]))
# plot(iris.hc,hang = -1)
plclust(iris.hc, labels = FALSE, hang = -1)
re <- rect.hclust(iris.hc, k = 3)
iris.id <-cutree(iris.hc, 3)
table(iris.id, Species)
###### 运行结果 #######
> table(iris.id,Species)
Species
iris.id setosa versicolor virginica
1 50 0 0
2 0 23 49
3 0 27 1
聚类分析生成的图形如下:
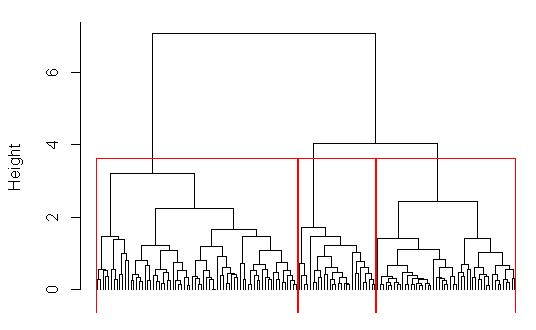
鸢尾花花萼及花瓣的长度和宽度系统聚类图
结果表明,函数cuttree()将数据iris分类结果iris.hc编为三组分别以1,2, 3表示,保存在iris.id中。将iris.id与iris中Species作比较发现:1应该是setosa类,2应该是virginica类(因为virginica的个数明显多于versicolor),3是versicolor。
2 动态聚类法
仍以R基础包自带的鸢尾花(Iris)数据进行K-均值聚类分析,分析代码如下:
1
2
3
4
5
6
7
8
9
###### 代码清单 #######
library(fpc)
data(iris)
df<-iris[,c(1:4)]
set.seed(252964) # 设置随机值,为了得到一致结果。
(kmeans <- kmeans(na.omit(df), 3)) # 显示K-均值聚类结果
plotcluster(na.omit(df), kmeans$cluster) # 生成聚类图
生成的图如下:
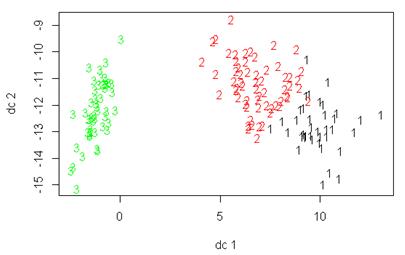
动态聚类结果
转载自:http://blog.sciencenet.cn/blog-1114360-735780.html
0 0
- 聚类分析_R语言
- R语言实现聚类分析
- R语言 聚类分析
- R语言-聚类分析
- R语言 聚类分析
- R语言聚类分析
- R语言实战 聚类分析
- r语言聚类分析
- R语言 : 层次聚类分析
- R语言学习之聚类分析
- R语言-聚类分析相关函数
- R语言实现层次聚类分析
- 用R语言求概率分布_R语言学习笔记5
- R语言快速入门_R语言中的一些重要的数据结构
- 聚类分析
- 聚类分析
- 聚类分析
- 聚类分析
- JAVA 获取当前月的初始时间的时间戳
- C# interface与abstract class区别
- haproxy+keepalived实现高可用负载均衡
- 我不是懒东西
- oracle 备份、还原、导出导入,创建表空间以及用户的命令和语句
- 聚类分析_R语言
- 功能权限和数据权限管理的实现
- 【小白笔记】PHP学习之路 (26) --文件上传与下载、配置
- rules for reference counting are still fulfilled(ARC).
- c3p0详细配置
- C#使用XmlDocument操作XML进行查询、增加、修改、删除、保存应用的实例
- HttpHandler开发的两个重点问题
- ubuntu(64位) 安装 Balsamiq Mockups绘制原型图
- 双面打印技巧


