K-SVD
来源:互联网 发布:中国电信盒子安装软件 编辑:程序博客网 时间:2024/05/14 08:50
参考网址:http://en.wikipedia.org/wiki/K-SVD
K-SVD 是一种关于稀疏表示的字典学习算法。之所以称之为K-SVD ,是因为该算法K次迭代使用SVD(singular value decomposition)。K-SVD是 k-means的一种推广,该算法采用迭代交替学习方式,通过迭代优化输入数据在当前字典的表示和更新字典中的单词(atom)以更好地拟合数据1][2] 。 K-SVD在图像处理、语音处理、生物和文件分析等众多领域被广泛应用。
稀疏表示问题描述
给定一个过完备的字典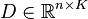 ,该字典包含
,该字典包含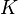 个单词,在此每一列都被视作一个单词。一个信号
个单词,在此每一列都被视作一个单词。一个信号 能够被表示为这些单词的线性组合。为表示
能够被表示为这些单词的线性组合。为表示 ,稀疏表示
,稀疏表示  应当满足精确条件
应当满足精确条件 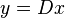 , 或者满足近似条件
, 或者满足近似条件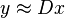 , 或者满足条件
, 或者满足条件  . 向量
. 向量  由表示的系数组成. 通常来说, 范数
由表示的系数组成. 通常来说, 范数  可以选为L1, L2, 或者 L∞ .
可以选为L1, L2, 或者 L∞ .
如果 并且 D 是满秩矩阵,那么稀疏表示问题的解为有限个,因此,应当对解设置一定的条件。并且,为保证稀疏性,含有最少非零元素的解是我们更想得到的。我们的目的是在当前字典的基础上,用最少的非零元素表示所有的样本。因此,稀疏表示是问题
并且 D 是满秩矩阵,那么稀疏表示问题的解为有限个,因此,应当对解设置一定的条件。并且,为保证稀疏性,含有最少非零元素的解是我们更想得到的。我们的目的是在当前字典的基础上,用最少的非零元素表示所有的样本。因此,稀疏表示是问题
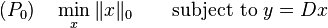
或者问题

的解。在此, 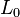 范数是向量中非零元素的个数. (具体可参考矩阵范数Matrix norm)。
范数是向量中非零元素的个数. (具体可参考矩阵范数Matrix norm)。
K-SVD 算法
K-SVD 是 K-means的一种泛化。稀疏表示的目的是用少数的几个单词来表示一个样本,K-means只用一个单词表示一个样本(K-means的中心为单词)。因此. k-means能够被视作 sparse representation的一种方法. 这就是, 通过最近邻(nearest neighbor)寻找最好的可能码本表示数据样本  。 通过解决问题
。 通过解决问题

该问题可以改写为
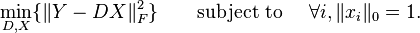
稀疏表示项 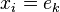 使K-means 算法仅用字典中的一个单词(一列)来表示样本
使K-means 算法仅用字典中的一个单词(一列)来表示样本 。为松弛这个条件, K-SVD 算法的目标是将信号表示为字典中单词的线性组合。
。为松弛这个条件, K-SVD 算法的目标是将信号表示为字典中单词的线性组合。
K-SVD 算法遵循K-means的类似条件。然而, 和 K-means不同的是, 为表示为字典D的线性组合,稀疏项的条件放宽到每列的非零元素数目可以大于1,但是少于 。因此,目标函数变为
。因此,目标函数变为

或者另一种形式

在 K-SVD算法中,首先固定字典 求最佳的系数矩阵
求最佳的系数矩阵  。 因为找到最优的真值 是不可能的, 我们采取近似追踪(approximation pursuit)的方法。给定字典和阈值,如OMP(the orthogonal matching pursuit)可以用来计算系数。
。 因为找到最优的真值 是不可能的, 我们采取近似追踪(approximation pursuit)的方法。给定字典和阈值,如OMP(the orthogonal matching pursuit)可以用来计算系数。
在 sparse coding 任务之后,下一步是寻找更优的字典 。然而, 一次求解整个字典不大可能,因此在该过程中每次仅更新字典 的一列(一个单词),在固定的情况下. 第k个列的更新通过求解如下被改写的惩罚项:
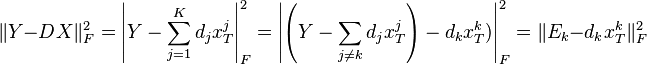
在此,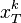 代表矩阵X的第k行.
代表矩阵X的第k行.
通过将乘积  分解为 个秩为 1 的矩阵(矩阵乘积的秩小于或等于两个因子的秩), 我们可以假设 第k个未知,其余
分解为 个秩为 1 的矩阵(矩阵乘积的秩小于或等于两个因子的秩), 我们可以假设 第k个未知,其余 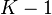 项固定。 这步后,我们可以解最小化问题通过采用奇异值分解(singular value decomposition)用一个秩为
项固定。 这步后,我们可以解最小化问题通过采用奇异值分解(singular value decomposition)用一个秩为  的矩阵近似
的矩阵近似 ,然后更新
,然后更新 。 然而, 新的解向量 很可能不是稀疏的, 因为我们在此并未强加稀疏约束。为解决此问题,我们定义
。 然而, 新的解向量 很可能不是稀疏的, 因为我们在此并未强加稀疏约束。为解决此问题,我们定义 为
为

对应使用了单词样本  (即 对应的元素非0). 接着, 我们定义
(即 对应的元素非0). 接着, 我们定义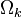 为大小
为大小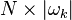 的矩阵, 该矩阵在
的矩阵, 该矩阵在 处元素为1,其余元素为0。做右乘
处元素为1,其余元素为0。做右乘 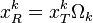 , 可以将行向量 中的非0元素去掉。类似地, 乘积
, 可以将行向量 中的非0元素去掉。类似地, 乘积 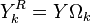 表示样本集中使用了单词 表示的样本子集。 同理,我们可以得到
表示样本集中使用了单词 表示的样本子集。 同理,我们可以得到 。
。
因此,以上的最小化问题可以变为
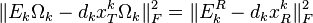
熟悉PCA的朋友可以看到,该最小化问题本质上就是一个PCA问题。即用一个基向量表示当前所有的样本,误差最小。该问题可以直接用SVD解。 SVD 算法将矩阵  分解为
分解为 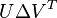 。 的解为矩阵 U的第一个列向量, 系数向量
。 的解为矩阵 U的第一个列向量, 系数向量 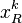 的解为矩阵
的解为矩阵  的第一列。 在更新完整个字典后, K-SVD算法又转向更新 X, 然后再迭代优化字典.
的第一列。 在更新完整个字典后, K-SVD算法又转向更新 X, 然后再迭代优化字典.
局限性
为数据集选择字典是一个非凸的问题, K-SVD算法通过迭代优化并不能保证结果全局最优。[2]然而,这对使用迭代优化的算法很常见, 并且K-SVD算法在实际应用中效果很不错 .[2]

参考文献:
- Michal Aharon, Michael Elad, and Alfred Bruckstein (2006), "K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation", IEEE Transactions on Signal Processing 54 (11): 4311–4322, doi:10.1109/TSP.2006.881199
- ^ Jump up to:a b c Rubinstein, R., Bruckstein, A.M., and Elad, M. (2010), "Dictionaries for Sparse Representation Modeling", Proceedings of the IEEE 98 (6): 1045–1057,doi:10.1109/JPROC.2010.2040551
- K-SVD
- k-svd
- K-SVD
- K-SVD
- K-SVD
- K-SVD, BM3D等
- K-SVD Algorithm
- K-SVD matlab
- K-SVD算法
- K-SVD Algorithm
- K-SVD算法总结
- K-SVD算法
- K-SVD算法简介
- K-SVD算法总结
- K-SVD学习笔记
- K-SVD算法
- K-SVD算法学习
- k-svd字典学习
- Code Sign error: No matching provisioning profile found: Your build settings specify a provisioni.
- swing的ItemListener的监听事件
- android快速开发框架
- python requests的安装与简单运用
- c++(vc)实现类似qq窗口悬挂功能
- K-SVD
- css 实现球形渐变
- 增加删除cookie
- 玩转CPU Topology
- cocos2dx-3.0建立lua项目
- 【iOS开发】创建你自己的 iOS 框架
- .NET项目持续集成实践 - Jenkins
- Libjingle和各协议的关系
- SQL性能优化(不断总结)


