决策树总结
来源:互联网 发布:贵州大数据学院 编辑:程序博客网 时间:2024/05/16 04:47
首先,要对决策树有个大致的了解。决策树是应用比较广的归纳推理算法(可以是分类,也可以是推断,实质是将离散值进行划分)。
下面将决策树进行细致的讲解,分为以下几个部分:
1、决策树定义以及基本的学习方法
2、决策树学习举例
3、决策树学习中存在的几个问题,以及解决办法
4、matlab中使用统计工具箱实现决策树学习
1、决策树的定义以及基本的学习方法
在决策树中,实例是由“属性-值”组成的,例如说暴雨的强度,可以是暴雨,大暴雨,特大暴雨三个值。决策树通过把实例从根节点排列属性来分类实例,叶子节点对应的就是属性的值,即为不同的分类。树上的每一个结点指定了对实例的某个属性的测试,并且该结点的每一个后继分支对应于该属性的一个可能值。分类实例从树的根结点开始,测试这个结点指定的属性,然后按照给定实例的该属性的值对应的树枝向下移动,不断地重复这个过程,进而构造出整棵树。
上面构造树的过程中,存在一个问题,即是如何选择属性。一般在开始构造树时,各个属性之间是没有联系的。那如何来选择哪个属性放在根节点,哪个属性放在第二个结点呢?这个问题就是——决策树是如何进行学习的。按照咱的经验也知道,要进行分类,肯定是分类能力比较强的放在根节点,逐步往下。但是什么样的属性分类能力比较强呢?如何进行量化一个属性的分类能力呢?在信息论中我们知道,一个属性的信息量,是通过熵来描述的,它刻画了任意样例集的纯度(这点不太理解?纯度在这是什么意思),如下:
例如上面暴雨强度的例子,假如暴雨、大暴雨、特大暴雨的概率分别为1/6,1/3,1/2,则Entropy(s)=-1/6*log2(1/6)-1/3*log2(1/3)-1/2*log2(1/2).下图是属性取两个值的信息熵图
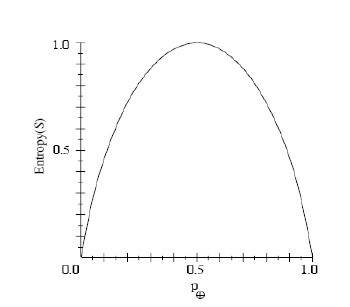
那么现在我们知道了一个属性的信息量的多少,但我们显然不能根据信息量的多少将属性从根结点往下排,因为信息量大的不一定分类能力强。在这,使用“信息增益”来作为属性分类能力的度量标准。简单地讲,一个属性的信息增益就是使用这个属性分割样例,导致的期望熵降低的多少。要是一个属性使用后,使得整个集合的信息增益降了比较多,那么我们就可以认定,这个属性的分类能力是比较强的(也可以理解为,使用了某个属性后,整个集合中的信息量减少了比较多,消除了很多不确定性,那么可以认为该属性分类能力较强),信息增益的公式如下:

有这个学习的度量标准后,接下来就是挨个计算各个属性的信息增益。从计算里面找到信息增益最大的,作为该结点的属性,从而完成该结点属性的选取。不断重复,最终能够构造出决策树。
2、决策树学习的例子
使用课本上决策树学习的例子(例子内容是星期六在各种条件下,决策是否适合打网球),下面是数据:
数据集中包含14个样本,其中9个正样本(yes),5个负样本(no)。则这些元组的期望信息(即熵)为:
Info(D) = - 9/14 * log2(9/14) - 5/14 * log2(5/14) = 0.940
现在观察每个属性的期望信息需求。在属性Outlook中,对于sunny,正样本数为2,负样本数为3;对于overcast,正样本数为4,负样本数为0;对与rain,正样本数为3,负样本数为2。
按照Outlook划分样例得到的信息熵为(这里有个问题,是否是选取熵小的作为根节点呢,熵小对应是该属性容易估计的,但是会有点矛盾的?):
5/14 * ( - 2/5log22/5 – 3/5log23/5) + 4/15 * ( - 4/4log24/4) + 5/14 * ( - 3/5log23/5 – 2/5log22/5)=0.694
即选取Outlook做根节点的信息增益为:
Gain(outlook) = 0.940 – 0.694 = 0.246
同理其他几个的信息增益如下:
Gain(Temperature) = 0.029
Gain(Humidity) = 0.151
Gain(Wind) = 0.048
由此根结点使用outlook.outlook可以取三个值,即sunny,overcast,rain。接下来在这三个值下面,继续重复上面步骤,从而构造出整个的决策树如下:
●避免过度拟合数据
过度拟合(Overfitting)即是训练的模型,对于训练的数据拟合度非常高,但对于验证的数据拟合度差(应该说,差的比较多,即是模型只是适合于训练数据。与之对应的一个概念叫欠拟合)。见下图:
其中决策树出现过度拟合的原因是:数据的不具有代表性,或者说数据不准确(个人观点,可能是数据受到噪声影响,导致树的构造和真实情况有偏差,或者是数据比较少),解决办法是1、及早的停止树的增长2、后修剪法,允许树过度拟合,通过验证数据对树进行修剪,一般第二种方法用的比较多。后修剪法中,根据修剪的准则不同,可以分为错误率降低修剪、规则后修剪,实质差别就是什么情况修剪,什么情况不修剪。
●属性的其他度量标准
我们上面讲的构造决策树,都是在信息增益准则下构造出的决策树。但信息增益这个属性有点内在的毛病,就是它会偏向于属性取比较多值。例如说,日期从1900到2014,由于这个属性取值特别多,计算信息增益时它消除了较多的不确定性。但实际上这个属性可能对于分类没有多大好处,最后设计的分类器效果可能也不好。既然如此,那该如何改进呢?按照我们的想法,既然是由于属性的取值特别多导致分类不好的,那我们就设置一个惩罚因子就好。由此,定义了增益比率这个度量标准。定义分裂信息来描述属性的广度和均匀性,公式如下:
增益比率是信息增益和分裂信息共同定义的,公式如下:
上面的公式也存在缺陷,主要是在分母。根据定义,分母处当Si=S时,分裂信息趋于0,从而导致增益比率比较大。因此这个度量准则一般用在,某个属性信息增益比较高的情况。这两个不同的度量准则,也是ID3决策树与C4.5的区别。
●处理缺少属性值的训练样例
资料上表示,缺少属性值的一种策略是给训练样例赋予常见值。(这个观点我是不太赞同的,毕竟这和私造没啥区别,毕竟训练数据本身是为了使模型越来越精确)。这个问题真不知道应该怎么解决,有需要的话再找答案吧。
4、matlab中使用统计工具箱实现决策树学习(参考http://blog.chinaunix.net/uid-29235952-id-4187114.html,讲的挺详细)
以下例子中,使用Fisher's Iris Data进行分类,数据如下:
- 决策树总结
- 决策树总结
- 决策树--总结
- 决策树总结
- 决策树总结
- 决策树个人总结
- 决策树算法总结
- 决策树算法总结
- CART决策树算法总结
- 决策树算法总结
- 决策树归纳总结
- 【机器学习】决策树总结
- 决策树系列算法总结——决策树
- 决策树的完整知识点总结
- 五、决策树--统计学习方法总结
- 机器学习算法总结--决策树
- 机器学习算法总结--决策树
- 决策树
- FireMonkey TrayIcon组件
- POJ 1191 棋盘分割(记忆化搜)
- 安卓基础学习1
- uml之状态图
- Java概念(一):POJO与Entity Bean
- 决策树总结
- hbase之路-1
- 三维形式显示图像
- JDK动态代理
- 素数
- Ubuntu下编译Android JNI实例全过程
- 条款24::若所有参数皆需类型转换,请为此采用 non-member 函数
- 对于当前时点不能进行事物的事后确认。
- 刚刚接触什么是对象和接口,记录一下


