大端小端(Big- Endian和Little-Endian)
来源:互联网 发布:sql语句的执行顺序 编辑:程序博客网 时间:2024/06/11 14:28
大端小端(Big- Endian和Little-Endian)
2011-10-11 09:47:20| 分类: 程序员笔试面试 | 标签: |举报 |字号大中小 订阅
图文并茂
http://www.cppblog.com/tx7do/archive/2009/01/06/71276.html
http://my.oschina.net/alphajay/blog/5478?from=rss
在各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领 域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正 确的编/译码从而导致通信失败。
目前在各种体系的计算机中通常采用的字节存储机制主要有两种:Big-Endian和Little-Endian,下面先 从字节序说起。
一、什么是字节序
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。其实大部分人在实际的开 发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字 节序分为两类:Big-Endian和Little-Endian,引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
1.1 什么是高/低地址端
首先我们要知道我们C程序映像中内存的空间布局情况:在《C专家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
栈底
栈
栈顶
-----------------------
NULL (空洞)
-----------------------
堆
-----------------------
未初始 化的数据
----------------------- 统称数据段
初始化的数据
-----------------------
正 文段(代码段)
----------------------- 最低内存地址 0x00000000
以上图为例如果我们在栈上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
1.2 什么是高/低字节
现在我们弄清了高/低地址,接着考虑高/低字节。有些文章中称低位字节为最低有效位,高位字节为最高有效位。如果我们有一个32位无符号整型0x12345678,那么高位是什么,低位又是什么呢? 其实很简单。
在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。
就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高/低地址端和高/低字节都弄清了。我们再来回顾 一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
栈 顶 (低地址)
二、各种Endian
2.1 Big-Endian
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最重要字节(MSB)存放在最低端的地址 上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
+----------+
| 0x34 |<-- 0x00000021
+----------+
| 0x12 |<-- 0x00000020
+----------+
图 1:双字节数0x1234以Big-Endian的方式存在起始地址0x00000020中
在Big-Endian中,对于bit序列 中的序号编排方式如下(以双字节数0x8B8A为例):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+----------------------------------------+
图 2:Big-Endian的bit序列编码方式
2.2 Little-Endian
计算机体系结构中 一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列 微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
+----------+
| 0x12 |<-- 0x00000021
+----------+
| 0x34 |<-- 0x00000020
+----------+
图3:双字节数0x1234以Little-Endian的方式存在起始地址0x00000020中
在 Little-Endian中,对于bit序列中的序号编排和Big-Endian刚好相反,其方式如下(以双字节数0x8B8A为例):
bit 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+-----------------------------------------+
图 4:Little-Endian的bit序列编码方式
注2:通常我们说的主机序(Host Order)就是遵循Little-Endian规则。
所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序 (Little-Endian)和网络序(Big-Endian)的转换。
注3:正因为这两种机制对于同一bit序列的序号编排方式恰 恰相反,所以《现代英汉词典》中对MSB的翻译为“最高有效位”欠妥,故本文定义为“最重要的bit/byte”。
2.3 Middle-Endian
除了Big-Endian和Little-Endian之外的多字节存储顺序就是Middle- Endian,比如以4个字节为例:象以3-4-1-2或者2-1-4-3这样的顺序存储的就是Middle-Endian。这种存储顺序偶尔会在一些小 型机体系中的十进制数的压缩格式中出现。
嵌入式系统开发者应该对Little-endian和Big-endian模式非常了解。采用Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。 32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
而在Big- endian模式CPU内存中的存放方式则为:
三、Big-Endian和Little-Endian优缺点
Big-Endian优点:靠首先提取高位字节,你总是可以由看看在偏移位置为0的字节来确定这个数字是 正数还是负数。你不必知道这个数值有多长,或者你也不必过一些字节来看这个数值是否含有符号位。这个数值是以它们被打印出来的顺序存放的,所以从二进制到十进制的函数特别有效。因而,对于不同要求的机器,在设计存取方式时就会不同。
Little-Endian优点:提取一个,两个,四个或者更长字节数据的汇编指令以与其他所有格式相同的方式进行:首先在偏移地址为0的地方提取最低位的字节,因为地址偏移和字节数是一对 一的关系,多重精度的数学函数就相对地容易写了。
如果你增加数字的值,你可能在左边增加数字(高位非指数函数需要更多的数字)。因此, 经常需要增加两位数字并移动存储器里所有Big-endian顺序的数字,把所有数向右移,这会增加计算机的工作量。不过,使用Little- Endian的存储器中不重要的字节可以存在它原来的位置,新的数可以存在它的右边的高位地址里。这就意味着计算机中的某些计算可以变得更加简单和快速。
四、如何检查处理器是Big-Endian还是Little-Endian?
由于联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little- endian还是Big-endian模式读写。
例如:
int checkCPUendian()
{
union
{
unsigned int a;
unsigned char b;
}c;
c.a = 1;
return (c.b == 1);
} /*return 1 : little-endian, return 0:big-endian*/
C++怎样判别大端小端
使用宏的方法:
 constint endian = 1;#define is_bigendian() ( (*(char*) &endian) == 0 )#define is_littlendbian() ( (*(char*) &endian) == 1 )
constint endian = 1;#define is_bigendian() ( (*(char*) &endian) == 0 )#define is_littlendbian() ( (*(char*) &endian) == 1 )方法二:
bool IsLittleEndian()

 {
{ union
union
 {long val;char Char[sizeof(long)];
{long val;char Char[sizeof(long)]; }u;// 1-小端(Intel); 0-大端(Motor)u.val = 1;if ( u.Char[0] == 1 ){// 小端returntrue;}elseif ( u.Char[sizeof(long)-1] == 1 ){// 大端returnfalse; }throw( "Unknown!" );
}u;// 1-小端(Intel); 0-大端(Motor)u.val = 1;if ( u.Char[0] == 1 ){// 小端returntrue;}elseif ( u.Char[sizeof(long)-1] == 1 ){// 大端returnfalse; }throw( "Unknown!" ); }
}
五、Big-Endian和Little-Endian转 换
现有的平台上Intel的X86采用的是Little-Endian,而像 Sun的SPARC采用的就是Big-Endian。那么在跨平台或网络程序中如何实现字节序的转换呢?这个通过C语言的移位操作很容易实现,例如下面的 宏:
#if defined(BIG_ENDIAN) && !defined(LITTLE_ENDIAN)
#define htons(A) (A)
#define htonl(A) (A)
#define ntohs(A) (A)
#define ntohl(A) (A)
#elif defined(LITTLE_ENDIAN) && !defined(BIG_ENDIAN)
#define htons(A) ((((uint16)(A) & 0xff00) >> 8) | \
(((uint16)(A) & 0x00ff) << 8))
#define htonl(A) ((((uint32)(A) & 0xff000000) >> 24) | \
(((uint32)(A) & 0x00ff0000) >> 8) | \
(((uint32)(A) & 0x0000ff00) << 8) | \
(((uint32)(A) & 0x000000ff) << 24))
#define ntohs htons
#define ntohl htohl
#else
#error "Either BIG_ENDIAN or LITTLE_ENDIAN must be #defined, but not both."
网络字节顺序
1、字节内的比特位不受这种顺序的影响
比如一个字节 1000 0000 (或表示为十六进制 80H)不管是什么顺序其内存中的表示法都是这样。
2、大于1个字节的数据类型才有字节顺序问题
比如 Byte A,这个变量只有一个字节的长度,所以根据上一条没有字节顺序问题。所以字节顺序是“字节之间的相对顺序”的意思。
3、大于1个字节的数据类型的字节顺序有两种
比如 short B,这是一个两字节的数据类型,这时就有字节之间的相对顺序问题了。
网络字节顺序是“所见即所得”的顺序。而Intel类型的CPU的字节顺序与此相反。
比如上面的 short B=0102H(十六进制,每两位表示一个字节的宽度)。所见到的是“0102”,按一般数学常识,数轴从左到右的方向增加,即内存地址从左到右增加的话,在内存中这个 short B的字节顺序是:
01 02
这就是网络字节顺序。所见到的顺序和在内存中的顺序是一致的!
假设通过抓包得到网络数据的两个字节流为:01 02
而相反的字节顺序就不同了,其在内存中的顺序为:02 01
如果这表示两个 Byte类型的变量,那么自然不需要考虑字节顺序的问题。如果这表示一个 short 变量,那么就需要考虑字节顺序问题。根据网络字节顺序“所见即所得”的规则,这个变量的值就是:0102
假设本地主机是Intel类型的,那么要表示这个变量,有点麻烦:
定义变量 short X,字节流地址为:pt,按顺序读取内存是为x=*((short*)pt);
那么X的内存顺序当然是 01 02按非“所见即所得”的规则,这个内存顺序和看到的一样显然是不对的,所以要把这两个字节的位置调换。调换的方法可以自己定义,但用已经有的API还是更为方便。
网络字节顺序与主机字节顺序
NBO与HBO 网络字节顺序NBO(Network Byte Order):按从高到低的顺序存储,在网络上使用统一的网络字节顺序,可以避免兼容性问题。主机字节顺序(HBO,Host Byte Order):不同的机器HBO不相同,与CPU设计有关计算机数据存储有两种字节优先顺序:高位字节优先和低位字节优先。Internet上数据以高位字节优先顺序在网络上传输,所以对于在内部是以低位字节优先方式存储数据的机器,在Internet上传输数据时就需要进行转换。
htonl()
简述:
将主机的无符号长整形数转换成网络字节顺序。
#include <winsock.h>
u_long PASCAL FAR htonl( u_long hostlong);
hostlong:主机字节顺序表达的32位数。
注释:
本函数将一个32位数从主机字节顺序转换成网络字节顺序。
返回值:
htonl()返回一个网络字节顺序的值。
inet_ntoa()
简述:
将网络地址转换成“.”点隔的字符串格式。
#include <winsock.h>
char FAR* PASCAL FAR inet_ntoa( struct in_addr in);
in:一个表示Internet主机地址的结构。
注释:
本函数将一个用in参数所表示的Internet地址结构转换成以“.” 间隔的诸如“a.b.c.d”的字符串形式。请注意inet_ntoa()返回的字符串存放在WINDOWS套接口实现所分配的内存中。应用程序不应假设该内存是如何分配的。在同一个线程的下一个WINDOWS套接口调用前,数据将保证是有效。
返回值:
若无错误发生,inet_ntoa()返回一个字符指针。否则的话,返回NULL。其中的数据应在下一个WINDOWS套接口调用前复制出来。
网络中传输的数据有的和本地字节存储顺序一致,而有的则截然不同,为了数据的一致性,就要把本地的数据转换成网络上使用的格式,然后发送出去,接收的时候也是一样的,经过转换然后才去使用这些数据,基本的库函数中提供了这样的可以进行字节转换的函数,如和htons( ) htonl( ) ntohs( ) ntohl( ),这里n表示network,h表示host,htons( ) htonl( )用于本地字节向网络字节转换的场合,s表示short,即对2字节操作,l表示long即对4字节操作。同样ntohs( )ntohl( )用于网络字节向本地格式转换的场合。
一、大端模式和小端模式的起源
关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。战争的原因:大家都知道,吃鸡蛋的时候,原始的方法是打破鸡蛋较大的一端,可以那时的皇帝的祖父由于小时侯吃鸡蛋,按这种方法把手指弄破了,因此他的父亲,就下令,命令所有的子民吃鸡蛋的时候,必须先打破鸡蛋较小的一端,违令者重罚。然后老百姓对此法令极为反感,期间发生了多次叛乱,其中一个皇帝因此送命,另一个丢了王位,产生叛乱的原因就是另一个国家Blefuscu的国王大臣煽动起来的,叛乱平息后,就逃到这个帝国避难。据估计,先后几次有11000余人情愿死也不肯去打破鸡蛋较小的端吃鸡蛋。这个其实讽刺当时英国和法国之间持续的冲突。Danny Cohen一位网络协议的开创者,第一次使用这两个术语指代字节顺序,后来就被大家广泛接受。
二、什么是大端和小端
Big-Endian和Little-Endian的定义如下:
1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0×12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 —————–> 高地址
0×12 | 0×34 | 0×56 | 0×78
2)小端模式:
低地址 ——————> 高地址
0×78 | 0×56 | 0×34 | 0×12
可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:
内存地址小端模式存放内容大端模式存放内容0×40000×340×120×40010×120×34
32bit宽的数0×12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0×4000开始存放)为:
内存地址小端模式存放内容大端模式存放内容0×40000×780×120×40010×560×340×40020×340×560×40030×120×784)大端小端没有谁优谁劣,各自优势便是对方劣势:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
三、数组在大端小端情况下的存储:
以unsigned int value = 0×12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下:
高地址
—————
buf[3] (0×78) — 低位
buf[2] (0×56)
buf[1] (0×34)
buf[0] (0×12) — 高位
—————
低地址
Little-Endian: 低地址存放低位,如下:
高地址
—————
buf[3] (0×12) — 高位
buf[2] (0×34)
buf[1] (0×56)
buf[0] (0×78) — 低位
————–
低地址
四、为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0×0010,x的值为0×1122,那么0×11为高字节,0×22为低字节。对于大端模式,就将0×11放在低地址中,即0×0010中,0×22放在高地址中,即0×0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
五、如何判断机器的字节序
可以编写一个小的测试程序来判断机器的字节序:
01BOOL IsBigEndian() 02{ 03int a = 0x1234; 04char b = *(char *)&a; //通过将int强制类型转换成char单字节,通过判断起始存储位置。即等于 取b等于a的低地址部分05if( b == 0x12) 06{ 07return TRUE; 08} 09return FALSE; 10}联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写:
01BOOL IsBigEndian() 02{ 03union NUM 04{ 05int a; 06char b; 07}num; 08num.a = 0x1234; 09if( num.b == 0x12 ) 10{ 11return TRUE; 12} 13return FALSE; 14}六、常见的字节序
一般操作系统都是小端,而通讯协议是大端的。
4.1 常见CPU的字节序
Big Endian : PowerPC、IBM、Sun
Little Endian : x86、DEC
ARM既可以工作在大端模式,也可以工作在小端模式。
4.2 常见文件的字节序
Adobe PS – Big Endian
BMP – Little Endian
DXF(AutoCAD) – Variable
GIF – Little Endian
JPEG – Big Endian
MacPaint – Big Endian
RTF – Little Endian
另外,Java和所有的网络通讯协议都是使用Big-Endian的编码。
七、如何进行转换
对于字数据(16位):
1#define BigtoLittle16(A) (( ((uint16)(A) & 0xff00) >> 8) | \2(( (uint16)(A) & 0x00ff) << 8))对于双字数据(32位):
1#define BigtoLittle32(A) ((( (uint32)(A) & 0xff000000) >> 24) | \2(( (uint32)(A) & 0x00ff0000) >> 8) | \3(( (uint32)(A) & 0x0000ff00) << 8) | \4(( (uint32)(A) & 0x000000ff) << 24))八、从软件的角度理解端模式
从软件的角度上,不同端模式的处理器进行数据传递时必须要考虑端模式的不同。如进行网络数据传递时,必须要考虑端模式的转换。在Socket接口编程中,以下几个函数用于大小端字节序的转换。
1#define ntohs(n) //16位数据类型网络字节顺序到主机字节顺序的转换2#define htons(n) //16位数据类型主机字节顺序到网络字节顺序的转换3#define ntohl(n) //32位数据类型网络字节顺序到主机字节顺序的转换4#define htonl(n) //32位数据类型主机字节顺序到网络字节顺序的转换其中互联网使用的网络字节顺序采用大端模式进行编址,而主机字节顺序根据处理器的不同而不同,如PowerPC处理器使用大端模式,而Pentuim处理器使用小端模式。
大端模式处理器的字节序到网络字节序不需要转换,此时ntohs(n)=n,ntohl = n;而小端模式处理器的字节序到网络字节必须要进行转换,此时ntohs(n) = __swab16(n),ntohl = __swab32(n)。__swab16与__swab32函数定义如下所示。
01#define ___swab16(x) 02{ 03__u16 __x = (x); 04((__u16)( 05(((__u16)(__x) & (__u16)0x00ffU) << 8) |06(((__u16)(__x) & (__u16)0xff00U) >> 8) ));07} 08#define ___swab32(x) 09{ 10__u32 __x = (x); 11((__u32)( 12(((__u32)(__x) & (__u32)0x000000ffUL) << 24) |13(((__u32)(__x) & (__u32)0x0000ff00UL) << 8) |14(((__u32)(__x) & (__u32)0x00ff0000UL) >> 8) |15(((__u32)(__x) & (__u32)0xff000000UL) >> 24) ));16}PowerPC处理器提供了lwbrx,lhbrx,stwbrx,sthbrx四条指令用于处理字节序的转换以优化__swab16和__swap32这类函数。此外PowerPC处理器中的rlwimi指令也可以用来实现__swab16和__swap32这类函数。
在对普通文件进行处理也需要考虑端模式问题。在大端模式的处理器下对文件的32,16位读写操作所得到的结果与小端模式的处理器不同。单纯从软件的角度理解上远远不能真正理解大小端模式的区别。事实上,真正的理解大小端模式的区别,必须要从系统的角度,从指令集,寄存器和数据总线上深入理解,大小端模式的区别。
九、从系统的角度理解端模式
MSB:MoST Significant Bit ——- 最高有效位
LSB:Least Significant Bit ——- 最低有效位
处理器在硬件上由于端模式问题在设计中有所不同。从系统的角度上看,端模式问题对软件和硬件的设计带来了不同的影响,当一个处理器系统中大小端模式同时存在时,必须要对这些不同端模式的访问进行特殊的处理。
PowerPC处理器主导网络市场,可以说绝大多数的通信设备都使用PowerPC处理器进行协议处理和其他控制信息的处理,这也可能也是在网络上的绝大多数协议都采用大端编址方式的原因。因此在有关网络协议的软件设计中,使用小端方式的处理器需要在软件中处理端模式的转变。而Pentium主导个人机市场,因此多数用于个人机的外设都采用小端模式,包括一些在网络设备中使用的PCI总线,Flash等设备,这也要求在硬件设计中注意端模式的转换。
本文提到的小端外设是指这种外设中的寄存器以小端方式进行存储,如PCI设备的配置空间,NOR FLASH中的寄存器等等。对于有些设备,如DDR颗粒,没有以小端方式存储的寄存器,因此从逻辑上讲并不需要对端模式进行转换。在设计中,只需要将双方数据总线进行一一对应的互连,而不需要进行数据总线的转换。
如果从实际应用的角度说,采用小端模式的处理器需要在软件中处理端模式的转换,因为采用小端模式的处理器在与小端外设互连时,不需要任何转换。而采用大端模式的处理器需要在硬件设计时处理端模式的转换。大端模式处理器需要在寄存器,指令集,数据总线及数据总线与小端外设的连接等等多个方面进行处理,以解决与小端外设连接时的端模式转换问题。在寄存器和数据总线的位序定义上,基于大小端模式的处理器有所不同。
一个采用大端模式的32位处理器,如基于E500内核的MPC8541,将其寄存器的最高位msb(most significant bit)定义为0,最低位lsb(lease significant bit)定义为31;而小端模式的32位处理器,将其寄存器的最高位定义为31,低位地址定义为0。与此向对应,采用大端模式的32位处理器数据总线的最高位为0,最高位为31;采用小端模式的32位处理器的数据总线的最高位为31,最低位为0。
大小端模式处理器外部总线的位序也遵循着同样的规律,根据所采用的数据总线是32位,16位和8位,大小端处理器外部总线的位序有所不同。大端模式下32位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第31位,LSB是第24~31字段。小端模式下32位总线的msb是第31位,MSB是数据总线的第31~24位,lsb是第0位,LSB是7~0字段。大端模式下16位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第15位,LSB是第8~15字段。小端模式下16位总线的msb是第15位,MSB是数据总线的第15~7位,lsb是第0位,LSB是7~0字段。大端模式下8位数据总线的msb是第0位,MSB是数据总线的第0~7的字段;而lsb是第7位,LSB是第0~7字段。小端模式下8位总线的msb是第7位,MSB是数据总线的第7~0位,lsb是第0位,LSB是7~0字段。
由上分析,我们可以得知对于8位,16位和32位宽度的数据总线,采用大端模式时数据总线的msb和MSB的位置都不会发生变化,而采用小端模式时数据总线的lsb和LSB位置也不会发生变化。
为此,大端模式的处理器对8位,16位和32位的内存访问(包括外设的访问)一般都包含第0~7字段,即MSB。小端模式的处理器对8位,16位和32位的内存访问都包含第7~0位,小端方式的第7~0字段,即LSB。由于大小端处理器的数据总线其8位,16位和32位宽度的数据总线的定义不同,因此需要分别进行讨论在系统级别上如何处理端模式转换。在一个大端处理器系统中,需要处理大端处理器对小端外设的访问。
十、实际中的例子
虽然很多时候,字节序的工作已由编译器完成了,但是在一些小的细节上,仍然需要去仔细揣摩考虑,尤其是在以太网通讯、MODBUS通讯、软件移植性方面。这里,举一个MODBUS通讯的例子。在MODBUS中,数据需要组织成数据报文,该报文中的数据都是大端模式,即低地址存高位,高地址存低位。假设有一16位缓冲区m_RegMW[256],因为是在x86平台上,所以内存中的数据为小端模式:m_RegMW[0].low、m_RegMW[0].high、m_RegMW[1].low、m_RegMW[1].high……
为了方便讨论,假设m_RegMW[0] = 0×3456; 在内存中为0×56、0×34。
现要将该数据发出,如果不进行数据转换直接发送,此时发送的数据为0×56,0×34。而Modbus是大端的,会将该数据解释为0×5634而非原数据0×3456,此时就会发生灾难性的错误。所以,在此之前,需要将小端数据转换成大端的,即进行高字节和低字节的交换,此时可以调用步骤五中的函数BigtoLittle16(m_RegMW[0]),之后再进行发送才可以得到正确的数据。
小端(高位存在高地址,低位存在低地址)\
union { long Long; char Char[sizeof(long)]; }u; bool IsBigOrSmall() // 1-小端(Intel); 0-大端(Motor) { u.Long = 1; if( u.Char[0] == 1 ) { return 1; } else if( u.Char[sizeof(long)-1] == 1 ) { return 0; } throw( "Unknown!" ); }
用于指代字节顺序,在网络传输和计算机硬件使用,通常表示逻辑最小处理单元大于物理最小处理单元时逻辑单元与物理单元的映射方式。通常情况下无论是大端还是小端都是以字节(8bit)计,在字节之内都是以大端顺序排列。但不排除以后随着计算机的发展将这个数字扩充。
字节排序
含义
Big-Endian
高位在前,低位在后。
Little-Endian
低位在前,高位在后
请看下面这个例子:
如果我们将0x1234abcd写入到以0x0000开始的内存中,则结果为
big-endian little-endian
0x0000 0x12 0xcd
0x0001 0x34 0xab
0x0002 0xab 0x34
0x0003 0xcd 0x12
然后,假如需要从内存中取32位整数0x1234abcd中的高16位整数,就需要知道是不是big-endian,如果是,需要从0x0002地址中去取,如果是little-endian,则需要从0x0000中取。也即怎么存就怎么取。
在“小终结者”形式中,提取一个,两个,四个或者更长字节数据的汇编指令以与其他所有格式相同的方式进行:首先在偏移地址为0的地方提取最低位的字节,因为地址偏移和字节数是一对一的关系,多重精度的数学函数就相对地容易写了。
在“大 终结者”的形式中,靠首先提取高位字节,你总是可以由看看在偏移位置为0的字节来确定这个数字是正数还是负数。你不必知道这个数值有多长,或者你也不必过一些字节来看这个数值是否含有符号位。这个数值是以它们被打印出来的顺序存放的,所以从二进制到十进制的函数特别有效。因而,对于不同要求的机器,在设计存取方式时就会不同。
IBM 的370主机,多数基于RISC计算机,和Motorola的微处理器使用big-endian方法。TCP/IP也使用big-endian方法 (big-endian方法也叫做网络编码)。对于人来说我们的语言都是从左到右的习惯方式。这看上去似乎被认为是自然的存储字符和数字方式-你同样也希 望以同样的方式出现在你面前。许多人因此也会认为big-endian是流行的存储方式,正如我们平时所读到的。然而,Intel处理器 (CPUs)和DEC Alphas和至少一些在他们的平台的其他程序都是little-endian的。对于little-endian有一个问题,那就是如果你增加数字的 值,你可能在左边增加数字(高位非指数函数需要更多的数字)。因此,经常需要增加两位数字并移动存储器里所有Big-endian顺序的数字,把所有数向右移,这会增加计算机的工作量。不过,使用little-endian的存储器中不重要的字节可以存在它原来的位置,新的数可以存在它的右边的高位地址 里。这就意味着计算机中的某些计算可以变得更加简单和快速。
字节序(Endian),大端(Big-Endian),小端(Little-Endian)
在各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正确的编/译码从而导致通信失败。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:
big-edian和little-endian。
字节顺序 Endian
现代的计算机系统一般采用字节(Octet, 8 bit Byte)作为逻辑寻址单位。当物理单位的长度大于1个字节时,就要区分字节顺序(Byte Order, or Endianness)。常见的字节顺序有两种:Big Endian(High-byte first)和Little Endian(Low-byte first),这就是表2.1中的BE和LE。Intel X86平台采用Little Endian,而PowerPC处理器则采用了Big Endian。举例来说,整型数字$1234ABCD存储的时候就会有两种方式:
字节顺序
内存数据
备注
Big Endian (BE)
0xAB 0xCD 0x12 0x34
此时的0xAB被称为most significant byte (MSB)
Little Endian (LE)
0xCD 0xAB 0x34 0x12
此时的0xCD被称为least significant byte (LSB)
词源:据Jargon File记载,endian这个词来源于Jonathan Swift在1726年写的讽刺小说 "Gulliver's Travels"(《格利佛游记》)。该小说在描述Gulliver畅游小人国时碰到了如下的一个场景。在小人国里的小人因为非常小(身高6英寸)所以总是碰到一些意想不到的问题。有一次因为对水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开的争论而引发了一场战争,并形成了两支截然对立的队伍:支持从Big-End剥开的人Swift就称作Big-Endians而支持从Little-End剥开的人就称作Little-Endians……(后缀ian表明的就是支持某种观点的人:-)。Endian这个词由此而来。
1980年,Danny Cohen在其著名的论文"On Holy Wars and a Plea for Peace"中为了平息一场关于在消息中字节该以什么样的顺序进行传送的争论而引用了该词。该文中,Cohen非常形象贴切地把支持从一个消息序列的MSB开始传送的那伙人叫做Big-Endians,支持从LSB开始传送的相对应地叫做Little-Endians。此后Endian这个词便随着这篇论文而被广为采用。
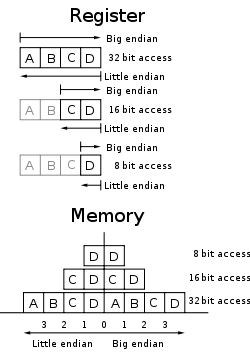
Mapping registers to memory locations
最高有效位 MSB: Most Significant Bit
最高有效位(MSB),有时候叫做最左边的位,是在一个n位二进制数字中的n-1位,这个位有最高的权重(2^(n-1))。第一个或最左边的位,当这个数字被用一般的方式书写时。
最低有效位 LSB: Least Significant Bit
最低有效位(LSB)是给这些单元值的一个二进制整数位位置,就是,决定是否这个数字是偶数或奇数。LSB有时候是指最右边的位,因为写较不重要的数字到右边位置符号的协定。它类似于一个十进制整数的最不重要的数字,它是在一个(最右边)位置的数字。
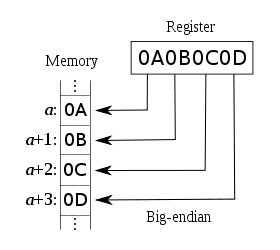
大端Big-Endian
低地址存放最高有效位(MSB),既高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最高有效位(MSB)存放在最低端的地址上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
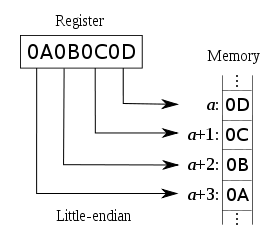
小端Little-Endian
低地址存放最低有效位(LSB),既低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
中端 Middle-Endian
除了big-endian和little-endian之外的多字节存储顺序就是middle-endian,比如以4个字节为例:象以3-4-1-2或者2-1-4-3这样的顺序存储的就是middle-endian。这种存储顺序偶尔会在一些小型机体系中的十进制数的压缩格式中出现。
网络字节序 Network Order
TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
主机序 Host Orader
它遵循Little-Endian规则。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序(Little-Endian)和网络序(Big-Endian)的转换。
C++怎样判别大端小端
使用宏的方法:
const int endian = 1;#define is_bigendian() ( (*(char*) &endian) == 0 )#define is_littlendbian() ( (*(char*) &endian) == 1 )方法二:
bool IsLittleEndian(){union { long val;char Char[sizeof(long)];}u;// 1-小端(Intel); 0-大端(Motor)u.val = 1; if ( u.Char[0] == 1 ){// 小端return true;} else if ( u.Char[sizeof(long)-1] == 1 ){// 大端return false; } throw( "Unknown!" );}
小知识
Java使用的是Big-Endian。
引用
1. 关于Endian大小端模式:
http://hi.baidu.com/%C8%FD%C9%EE/blog/item/6abb3d7779c0961db151b96b.html
2. Endianness:
http://en.wikipedia.org/wiki/Endianness
- 大端(Big Endian)和小端(Little Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端和小端(Big endian and Little endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)
- 大端小端(Big- Endian和Little-Endian)探究
- 大端小端(Big- Endian和Little-Endian)
- 自学django
- SQLServer 循环1百万插入测试数据
- 条形码控件字体的工具包Code 39 Font Advantage Package
- C++第15周(春)项目2 - 用文件保存的学生名单
- UVa:755 - 487--3279
- 大端小端(Big- Endian和Little-Endian)
- 文件下载
- Hive的数据存储模式
- 解决办法汇总:java.lang.NoSuchMethodError: javax.persistence.OneToMany.orphanRemoval()Z
- The Swift Programming Language 中文翻译版
- Android HAL开发详解
- CocoaPods安装和使用教程
- 使用SkinMagic美化VC界面
- html 空格


