support vector machine -note from wiki
来源:互联网 发布:ubuntu标题栏透明 编辑:程序博客网 时间:2024/06/15 20:23
Summary
Support vector machine is used for classification and regression analysis
SVM training algorithm build one model to assign the new examples into the category.
An SVM model is a representation of the examples as points in space.
svm can perform linear classification and non-linear classification with kernel tricks.
Definition
SVM constructs a hyperplane orset of hyperplanes in a high- or infinite-dimensional space, which can be used for classification, regression, or other tasks.
The hyperplane has the largest distance tothe nearest training data point of any class.the larger the margin the lower generalization error of the classifier.
sometimes The set to discriminate are not liner seperatable in the finite dimension,the original finite-dimensional space ismapped into amuch higher-dimensional space
By defining a kernel function  , the mappings are design to make dot product computation easily.
, the mappings are design to make dot product computation easily.
The hyperplanes is defined as set of points whoses the dot prodcut with vector is constant.
The vectors can be chosen as a liner combination with 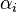 prameters.
prameters.
Then the points  in the feature space that are mapped into hyperplane are defined by the relation:
in the feature space that are mapped into hyperplane are defined by the relation: 
the sum of kernel are used to measure the relative nearness of each test point to the data points originating in sets.
Motivation
The goal is to decide which class a new data point will be in.
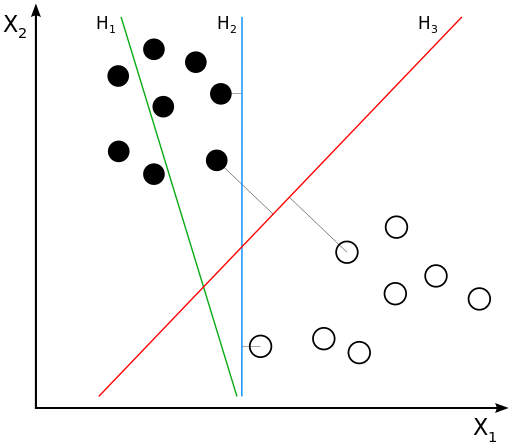
H1 does not separate the classes. H2 does, but only with a small margin. H3 separates them with the maximum margin.
we choose the hyperplane so that the distance from it to the nearest data pointon eachside is maximized.
The hyperplan is called maximum-margin hyperplane.
Liner svm
Given training set D, including n points.

Each  is a p-dimensional real vector.
is a p-dimensional real vector.
Any hyperplane can be written as the set of points 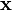 satisfying
satisfying
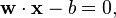
 is the normal vector to the hyperplane.
is the normal vector to the hyperplane.

Maximum-margin hyperplane and margins for an SVM trained with samples from two classes. Samples on the margin are called the support vectors.
we can select two hyperplanes(seperate the points)can be described by the equations

and

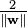 , so we want to minimize
, so we want to minimize 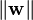 .
.In order to prevent data points from falling into the margin, we add the following constraint: for each  either
either
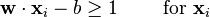 of the first class
of the first class
or
 of the second.
of the second.
This can be rewritten as:

Minimize (in  )
)
subject to (for any  )
)

Primal form
substituting ||w|| with with math convinience. this is quadratic programming optimization.
with math convinience. this is quadratic programming optimization.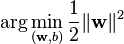
subject to (for any )
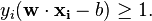
By introducing Lagrange multipliers 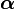 , the previous constrained problem can be expressed as
, the previous constrained problem can be expressed as
![\arg\min_{\mathbf{w},b } \max_{\boldsymbol{\alpha}\geq 0 } \left\{ \frac{1}{2}\|\mathbf{w}\|^2 - \sum_{i=1}^{n}{\alpha_i[y_i(\mathbf{w}\cdot \mathbf{x_i} - b)-1]} \right\}](http://upload.wikimedia.org/math/4/9/a/49a160099f1dd1f4073081e88ef4fd0c.png)
- The KKT implies the solution can be expressed as a linear combination of the training vectors:

Only a few will be greater than zero. The corresponding  are exactly the support vectors, which lie on the margin and satisfy
are exactly the support vectors, which lie on the margin and satisfy  . From this one can derive that the support vectors also satisfy
. From this one can derive that the support vectors also satisfy
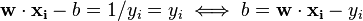
which allows one to define the offset  . In practice, it is more robust to average over all
. In practice, it is more robust to average over all  support vectors:
support vectors:

Dual form
Writing the classification rule reveals that the maximum-margin hyperplane and therefore the classification task is only a function of the support vectors.Using the fact that  and substituting
and substituting  , one can show that the dual of the SVM reduces to the following optimization problem:
, one can show that the dual of the SVM reduces to the following optimization problem:
Maximize (in )
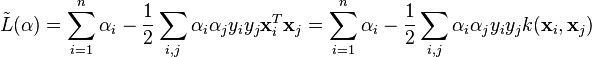
subject to (for any )

and to the constraint from the minimization in

Here the kernel is defined by  .
.
 can be computed thanks to the
can be computed thanks to the  terms:
terms:

- Soft Margain
- Soft Margin method will choose a hyperplane that splits the examples as cleanly as possible.
- The method introduces non-negative slack variables,
 , which measure the degree of misclassification of the data
, which measure the degree of misclassification of the data  ;
; 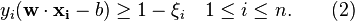
- optimization becomes a trade off between a large margin and a small error penalty
subject to (for any
 )
)This constraint in (2) along with the objective of minimizing
can be solved using Lagrange multipliers as done above. One has then to solve the following problem:with
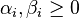 .
.Dual form[edit]
Maximize (in
)subject to (for any
)and
- every dot product is replaced by a nonlinear kernel function
Some common kernels include:
- Polynomial (homogeneous):

- Polynomial (inhomogeneous):

- Gaussian radial basis function:
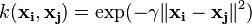 , for
, for  . Sometimes parametrized using
. Sometimes parametrized using 
- Hyperbolic tangent:
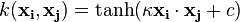 , for some (not every)
, for some (not every)  and
and 
 by the equation
by the equation 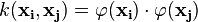 .
.- Polynomial (homogeneous):
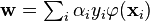
- Properties
- The effectiveness of SVM depends on the selection of kernel, the kernel's parameters, and soft margin parameter C
- Implementation
- The parameters of the maximum-margin hyperplane are derived by solving the optimization.

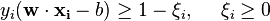
![\arg\min_{\mathbf{w},\mathbf{\xi}, b } \max_{\boldsymbol{\alpha},\boldsymbol{\beta} }\left \{ \frac{1}{2}\|\mathbf{w}\|^2+C \sum_{i=1}^n \xi_i- \sum_{i=1}^{n}{\alpha_i[y_i(\mathbf{w}\cdot \mathbf{x_i} - b) -1 + \xi_i]}- \sum_{i=1}^{n} \beta_i \xi_i \right \}](http://upload.wikimedia.org/math/8/6/4/86478542f998f3ad2d0f40a91687f8da.png)

- support vector machine -note from wiki
- CalTech machine learning, video 14 note(Support Vector Machine)
- [Machine Learning]--Support Vector Machine
- support vector machine
- Transductive Support Vector Machine
- 使用Support Vector Machine
- SVM Support Vector Machine
- Support Vector Machine
- SVM(Support Vector Machine)
- Support Vector Machine
- Support vector machine
- Support Vector Machine
- 5. support vector machine
- Support Vector Machine是什么?
- SVM(Support Vector Machine)
- support vector machine简介
- Support Vector Machine
- 论文读书笔记-Support vector machine
- iis如何下载包含中文文件名的rar文件
- 《算法设计与分析》考试说明(复习总结 与 试题提交方式、个人考勤记录——2014.05.10更新)
- Linux Shell脚本查看Java线程的CPU使用情况
- Python多线程下载文件实例代码
- C++输出wchar_t和wstring
- support vector machine -note from wiki
- coherent 和NoCoherent的正交IQ频率间隔
- u-boot学习(五):u-boot启动内核
- 代码分析工具推荐Understand
- java.util.concurrent包(4)——读写锁ReentrantReadWriteLock
- 在IOS程序中设置UIButton的字体大小
- Java Web Start为什么能加载pack.gz
- Nginx学习之一-第一个程序Hello World
- leetcode_Reverse Integer


