插入排序
来源:互联网 发布:unity3d 2d 编辑:程序博客网 时间:2024/05/01 06:17
ps:红色字体为2015/6/18 修改
排序的知识博大精深,不是一蹴而就的。
今天有幸学习一下插入排序。早就听说过插入排序,不过一直没有实现过,借着复习数据结构,来实现一下。
插入排序的思想:
向一个有序的序列中,插入一个数,使新生成的序列继续有序。直到所有的数插入完毕。
直接插入:
直接插入排序很是简单。
代码:
<span style="font-size:18px;">void insertsort(int *arr,int n) { for(int i = 1; i < n; i++){ for(int j = i-1; j >= 0; j --) { if(arr[j+1] < arr[j]) swap(arr[j+1], arr[j]); else break; } /*for(int k = 0; k < 8; k++){ printf("->%d",arr[k]); } printf("\n");*/ }}</span>分析:
时间复杂度上,一般情况下,为O(n^2)。最快的情况下,为n次的查找和插入,这种数据就是,本来就是按关键字排好序的。最坏的情况下,为n*(n-1)次的比较和n-1次的“移动”,这种数据就是,本来按关键字的逆序来排序的。
其他插入排序。
1.折半插入排序:
我一直在想折半插入排序的意义在哪?
有一种说法是,减少了查找时候的比较次数。我很赞同这句话。但是,没有减少移动次数。这句话也对。
我认为,比较和移动的一起进行的,那么我先查找的意义何在?本来,比较和移动是在同一时间进行的,这样把它们分开来,不就更加的费时吗?
2.2-路插入排序:
简单来说就是把,待插入的表分成两个表,减少比较次数。
2-路插入排序代码:
<span style="font-size:18px;">void twoway_insertsort(int *arr,int n) { int tmp[N]; int first = 0, final = 0; tmp[0] = arr[0]; for(int i = 1; i < n ; i ++) { if(arr[i] > tmp[final]){ tmp[++final] = arr[i]; } else if(arr[i] < tmp[first]) { first = (first - 1 + n) % n; tmp[first] = arr[i]; } else { tmp[++final] = arr[i]; int k = final; while(tmp[k] < tmp[k-1]){ // swap(arr[k], arr[k-1]) is wrong! because arr[0],arr[7]. swap(tmp[k], tmp[((k - 1) + n) % n]); k = ((k - 1) + n) % n; // printf("k = %d\n",k); } } } //printf("%d %d\n",first,final); int i = first, top = 0; while(top < n) { arr[top ++] = tmp[(i ++) % n]; }}</span>实现确实花费了一点时间。不过理解取余最为关键。
分析:对于一般的数据,效率比一般的插入排序有明显的优势。
3.表插入排序。
后续更新。。。。。。
4.希尔排序:
希尔排序(shell's sort)也是插入排序的一种。
它是思想是:先将整个待排序序列分割成若干个序列分别进行直接插入排序,带整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
希尔排序的一个特点 是:子序列的构成并不是简单地“逐段分割”,而是将相隔的某个“增量”的记录组成一个子序列。
这里最重要的就是引入了一个增量的概念,有必要特殊的解释一下:
我们可以看到,就是shell排序的最重要思想就是要划分序列,划分序列按照增量来进行划分。
比如一开始的增量为inc = n / 2,inc = inc /2,....inc = 1。也就是说,我们要按照不同的增量来进行划分,然后,同时排序。
当inc = 1的时候,shell排序就成为了最简单的插入排序,由于现在的序列已经基本有序,所以,该次排序应该是接近于n的。
总体时间复杂度,鉴于选择的增量不同,会有不同时间复杂度。下表上就给出了选择不同的增量,会出现的不同时间复杂度。
-----------下面这句话才是shell排序的精髓----------------
为什么希尔排序较直接插入排序快?
因为根据增量进行分组后,关键字较小的会进行跳跃式的前移。在进行最后一次是插入排序的时候,已经使得序列基本有序。
那么增量是怎么选定的呢?
time complexity

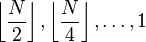
 [when N=2p]Shell, 1959[2]
[when N=2p]Shell, 1959[2]
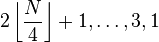
 Frank & Lazarus, 1960[6]
Frank & Lazarus, 1960[6]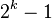
 Hibbard, 1963[7]
Hibbard, 1963[7] , prefixed with 1
, prefixed with 1 Papernov & Stasevich, 1965[8]successive numbers of the form
Papernov & Stasevich, 1965[8]successive numbers of the form 

 Pratt, 1971[9]
Pratt, 1971[9] , not greater than
, not greater than 
 Knuth, 1973[1]
Knuth, 1973[1]这些是前人总结出来效率比较高的增量。
那么我们就一shell的增量来进行实现。
希尔排序代码:
<span style="font-size:18px;">void shell_sort(int *arr,int n) { for(int inc = n / 2; inc > 0; inc = inc / 2) { for(int i = inc; i < n; i ++){ for(int j = i; j >= inc; j = j - inc){ if(arr[j] < arr[j - inc]){ swap(arr[j], arr[j - inc]); } else break; } } }}</span>我们可以看到,其实就是一个增量+直接插入排序。
- 插入排序-【插入排序】
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- 插入排序
- Android资源之图像资源(状态图像资源)
- SQL_数据库基础之级联删除和级联更新
- [Perl系列—] 2. Perl 中的引用用法
- java自学之路-----对于之前学习的总结以及接下来的计划
- 第105天
- 插入排序
- ovirt-engine搭建
- 使用Visual Studio 创建新的Web Part项目
- ovirt-engine详细安装
- ovirt-engine搭建问题总结
- 工作记录--make clean
- CentOS 6.5安装nvidia显卡驱动
- Cocos2d-x 3.0final 终结者系列教程15-win7+vs2012+adt+ndk环境搭建(无Cygwin)
- Delphi中destroy, free, freeAndNil, release用法和区别


