Dimension Reduction - feature selection
来源:互联网 发布:淘宝众筹卖家怎么赚钱 编辑:程序博客网 时间:2024/06/01 23:21
前一篇说到了feature extraction。这里可以先做一些简单的回顾。
feature extraction叫做特征提取,他是一种降维技术。跟feature selection不一样的是,它是从原来的特征集中,提取新的特征(可能是线性的也可能是非线性的)。
比如我们最为熟知的PCA是一种线性降维,autocoder就是一种非线性降维。
本篇说到的feature selection是一种不一样的降维策略。feature selection叫做特征选择,它是从原来的特征集中,选择特征子集(不会产生新特征)。
feature selection主要有三种方式: filter、wrapper和embedded。
filter: filter主要是通过给每个特征计算一个分数,然后按分数排序,从而选择top-k的特征作为新的特征集。他的优点很明显:计算速度快;缺点也很明显:没有考虑特征间的关系,导致效果不一定好。常见的fiter方法有: mutual information(互信息)、pearson相关系数、 卡方检验、 InfoGain等。
wrapper:wrapper 使用预测模型来对特征集进行评分。也就是说,对每一个特征子集,我们进行训练并预测,得到的误差作为这个模型的分数(当然是越小越好了)。但是这种方法计算极慢,因为要考虑每一个feature subset。所以有时候,我们会用一些greedy的策略,例如我们所熟知的逐步回归的思想-逐步加入或者逐步删去。
embedded:embedded的方法都是内嵌在模型构建的本事的。事实上,这种特征选择的办法,都是基于构造机器学习模型时,产生的一些好的性质(比如线性回归时某些属性的系数为0)。这种办法属于比较常见的办法有:加入L1惩罚的回归模型(Lasso, SVM)、 随机森林(得到特征的importance)。embedded的计算复杂度介于上述两者之间。

下面具体介绍这些常规的特征选择算法
Filter:
Mutual Information

网上找了点资料,这个应该容易理解。A可以看成属性,B看成是class。
pearson系数
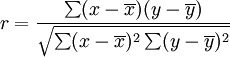
其中x是每个属性,y是class。
卡方检验
卡方检验可以看看下面这个blog中的内容。简单来说,就是假设属性和class是独立的,然后计算卡方量。卡方量越大,说明两者越有关系。

InfoGain
InfoGain大家应该很熟悉了,就是决策树那里那个InfoGain。其实这个应该容易想,跟决策树选属性分裂是一个道理。具体公式就不贴了,算个熵即可。
上面列举的4种,都是带监督的。那有没有非监督的特征选择方法呢? 之前做实验室的项目的时候,就接触过一种叫做Laplacian的方法,是基于方差的。pdf在这里:http://people.cs.uchicago.edu/~niyogi/papersps/HeCaiNiylapscore.pdf
Wrapper:
Wrapper更像是一种策略,逐步加入或者逐步删去,而加入和删去的标准是错误率。比较常见的就是greedy forward selection和backward selection。
以Logistic Regression做forward selection为例:
feature set = {}
for (j = 1 to k)
for(i = 1 t o n)
加入f[i],到feature set, 然后run LR,得到error
选择min(error)对应的feature f(o)。
把f(o) 加入 feature set
end
至于前面review的图片中提到的randomize的方法,目前我也没有看过== 等到需要的时候,再回过头来补吧。
最后还有一点说明,RFE(recursive feature elemination)并不是wrapper,它是一种embedded的方法。因为RFE每次删去的是系数最小的feature,这个系数是由模型得到。我们并没有直接在feature space里进行搜索。
Embedded:
Embedded应该说算看着比较高大上了(有比较复杂的数学模型了)。先来说说L1,之前面试也被问到过2次。
L1 based method:
L1其实就是在你的cost function后面加一介的惩罚,他主要是用来规则下你的参数范围。加入L1后,训练后的解往往很稀疏(许多变量为0)。
L2是二阶惩罚(具有kernel性质)。来看看他们的区别。

我们发现,L1的解是sharp的,而L2则相对圆滑。这个图可以一定程度上,说明为什么加入L1 正则化后,解会很稀疏(因为L1相交会在角上)。
详细的比较可以参考http://blog.csdn.net/xidianzhimeng/article/details/20856047。
一般的,L1可以加到linear regression和support vector regression中,得到稀疏解,然后根据weight vector 选择那些非零系数对应的特征,就完成了特征选择。
Random Forest
首先我是参考了http://en.wikipedia.org/wiki/Random_forest上面计算importance来给出features的ranking,从而选择特征。
然后计算这个importance的办法是:
对于每棵树,我们每次改变OOB测试集(就是构造树的时候,没有被选中的那些样本,因为RF是sample with replacement)的某个特征的排列(randomly permutation), 然后再计算error。跟之前没有排序的error进行对比。
举个例子,比如对于树T, 特征f, 我们对OOB样本属性f的那一列,随机排序。得到新的样本集,然后再次测试error。这个新误差-原误差就是我们认为的importance(当然是要每棵树average一下)。可以想象,如果特征越重要,那么随机排序产生的新误差越大,所以我们的importance会越重要。
具体可以参考: variable selection using randomforest这篇文章。
- Dimension Reduction - feature selection
- Feature extraction feature selection Dimension reduction
- Dimension Reduction - feature extraction
- sklearn-学习:Dimensionality reduction(降维)-(feature selection)特征选择
- Software for feature selection
- 特征选择Feature Selection
- regression Feature Selection
- 特征选择(feature selection)
- 特征选择(Feature Selection)
- Feature Selection(特征选择)
- 特征选择(feature selection)
- neuron classification with feature selection
- 1.13. 特征选择(Feature selection)
- R Clustering & Dimension Reduction聚类和降维
- openlayers select-feature show polygon dimension label
- 机器学习 4 model selection and feature selection
- An Introduction to Variable and Feature Selection
- 机器学习的特征选择(feature selection)
- 业务账号的修改
- Struts1之Titles框架 Demo
- JSON+JS实现省市县三级联动下拉框
- 解决JSP中文乱码问题
- selenium学习笔记第一篇之case1
- Dimension Reduction - feature selection
- CString转char * ,string
- ClientScript.RegisterStartupScript不能弹出的问题及解决方案
- Apktool在MAC上的使用
- 图文教你Spring如何连接MySQL
- opencv创建3通道图像
- Java程序为何“编译一次,到处运行”
- GetSafeHwnd()的调用正确时机
- C++头文件的组织


