[机器学习] 支持向量机通俗导论节选(一)
来源:互联网 发布:ubuntu wps字体库下载 编辑:程序博客网 时间:2024/05/12 10:50
本文转载自:http://blog.csdn.net/v_july_v/article/details/7624837
作者:July、pluskid ;致谢:白石、JerryLead支持向量机通俗导论(理解SVM的三层境界)
出处:结构之法算法之道blog。
第一层、了解SVM
1.0、什么是支持向量机SVM
要明白什么是SVM,便得从分类说起。
分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向量机本身便是一种监督式学习的方法(至于具体什么是监督学习与非监督学习,请参见此系列Machine L&Data Mining第一篇),它广泛的应用于统计分类以及回归分析中。
支持向量机(SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
对于不想深究SVM原理的同学或比如就只想看看SVM是干嘛的,那么,了解到这里便足够了,不需上层。而对于那些喜欢深入研究一个东西的同学,甚至究其本质的,咱们则还有很长的一段路要走,万里长征,咱们开始迈第一步吧,相信你能走完。
1.1、线性分类
OK,在讲SVM之前,咱们必须先弄清楚一个概念:线性分类器(也可以叫做感知机,这里的机表示的是一种算法,本文第三部分、证明SVM中会详细阐述)。
1.1.1、分类标准
这里我们考虑的是一个两类的分类问题,数据点用

上面给出了线性分类的定义描述,但或许读者没有想过:为何用y取1 或者 -1来表示两个不同的类别呢?其实,这个1或-1的分类标准起源于logistic回归,为了完整和过渡的自然性,咱们就再来看看这个logistic回归。
1.1.2、1或-1分类标准的起源:logistic回归

 的图像是
的图像是

 ,发现
,发现 只和
只和 有关,
有关, >0,那么
>0,那么 ,g(z)只不过是用来映射,真实的类别决定权还在
,g(z)只不过是用来映射,真实的类别决定权还在 。还有当
。还有当 ,
, =1,反之
=1,反之


 。Logistic回归就是要学习得到
。Logistic回归就是要学习得到 ,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。1.1.3、形式化标示
 替换成w和b。以前的
替换成w和b。以前的 ,其中认为
,其中认为 。现在我们替换
。现在我们替换 为
为
 )。这样,我们让
)。这样,我们让 ,进一步
,进一步

 的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
1.2、线性分类的一个例子
下面举个简单的例子,一个二维平面(一个超平面,在二维空间中的例子就是一条直线),如下图所示,平面上有两种不同的点,分别用两种不同的颜色表示,一种为红颜色的点,另一种则为蓝颜色的点,红颜色的线表示一个可行的超平面。
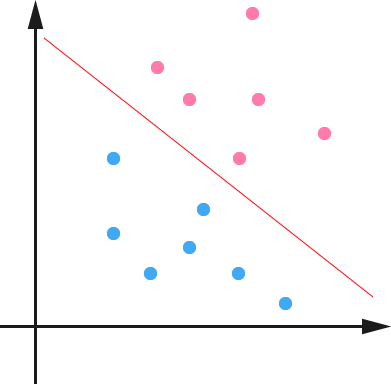
从上图中我们可以看出,这条红颜色的线把红颜色的点和蓝颜色的点分开来了。而这条红颜色的线就是我们上面所说的超平面,也就是说,这个所谓的超平面的的确确便把这两种不同颜色的数据点分隔开来,在超平面一边的数据点所对应的
接着,我们可以令分类函数(提醒:下文很大篇幅都在讨论着这个分类函数):
显然,如果
注:上图中,定义特征到结果的输出函数

 ,与我们之前定义的
,与我们之前定义的 实质是一样的。为什么?因为无论是,还是,不影响最终优化结果。下文你将看到,当我们转化到优化
实质是一样的。为什么?因为无论是,还是,不影响最终优化结果。下文你将看到,当我们转化到优化 (有一朋友飞狗来自Mare_Desiderii,看了上面的定义之后,问道:请教一下SVM functional margin 为
更进一步,我们在进行分类的时候,将数据点
请读者注意,下面的篇幅将按下述3点走:
- 咱们就要确定上述分类函数f(x) = w.x + b(w.x表示w与x的内积)中的两个参数w和b,通俗理解的话w是法向量,b是截距(再次说明:定义特征到结果的输出函数
- 那如何确定w和b呢?答案是寻找两条边界端或极端划分直线中间的最大间隔(之所以要寻最大间隔是为了能更好的划分不同类的点,下文你将看到:为寻最大间隔,导出1/2||w||^2,继而引入拉格朗日函数和对偶变量a,化为对单一因数对偶变量a的求解,当然,这是后话),从而确定最终的最大间隔分类超平面hyper plane和分类函数;
- 进而把寻求分类函数f(x) = w.x + b的问题转化为对w,b的最优化问题,最终化为对偶因子的求解。
总结成一句话即是:从最大间隔出发(目的本就是为了确定法向量w),转化为求对变量w和b的凸二次规划问题。亦或如下图所示(有点需要注意,如读者@酱爆小八爪所说:从最大分类间隔开始,就一直是凸优化问题):
1.3、函数间隔Functional margin与几何间隔Geometrical margin
一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。
于此,我们便引出了定义样本到分类间隔距离的函数间隔functional margin的概念。
- 在超平面w*x+b=0确定的情况下,|w*x+b|能够相对的表示点x到距离超平面的远近,而w*x+b的符号与类标记y的符号是否一致表示分类是否正确,所以,可以用量y*(w*x+b)的正负性来判定或表示分类的正确性和确信度。
1.3.1、函数间隔Functional margin
我们定义函数间隔functional margin 为:
接着,我们定义超平面(w,b)关于训练数据集T的函数间隔为超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值,其中,x是特征,y是结果标签,i表示第i个样本,有:
然与此同时,问题就出来了。上述定义的函数间隔虽然可以表示分类预测的正确性和确信度,但在选择分类超平面时,只有函数间隔还远远不够,因为如果成比例的改变w和b,如将他们改变为2w和2b,虽然此时超平面没有改变,但函数间隔的值f(x)却变成了原来的2倍。
其实,我们可以对法向量w加些约束条件,使其表面上看起来规范化,如此,我们很快又将引出真正定义点到超平面的距离--几何间隔geometrical margin的概念(很快你将看到,几何间隔就是函数间隔除以个||w||,即yf(x) / ||w||)。
1.3.2、点到超平面的距离定义:几何间隔Geometrical margin
在给出几何间隔的定义之前,咱们首先来看下,如上图所示,对于一个点
x ,令其垂直投影到超平面上的对应的为x0 ,由于w 是垂直于超平面的一个向量,为样本x到分类间隔的距离,我们有
(||w||表示的是范数,关于范数的概念参见这里)
又由于
x0 是超平面上的点,满足f(x0)=0 ,代入超平面的方程即可算出:
γ (有的书上会写成把||w|| 分开相除的形式,如本文参考文献及推荐阅读条目11,其中,||w||为w的二阶泛数)
不过这里的
y 即可,因此实际上我们定义 几何间隔geometrical margin 为(注:别忘了,上面
(代人相关式子可以得出:yi*(w/||w|| + b/||w||))
正如本文评论下读者popol1991留言:函数间隔y*(wx+b)=y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量;而几何间隔|f(x)|/||w||才是直观上的点到超平面距离。
想想二维空间里的点到直线公式:假设一条直线的方程为ax+by+c=0,点P的坐标是(x0,y0),则点到直线距离为|ax0+by0+c|/sqrt(a^2+b^2)。如下图所示:
那么如果用向量表示,设w=(a,b),f(x)=wx+c,那么这个距离正是|f(p)|/||w||。1.4、最大间隔分类器Maximum Margin Classifier的定义
于此,我们已经很明显的看出,函数间隔functional margin 和 几何间隔geometrical margin 相差一个
的缩放因子。按照我们前面的分析,对一个数据点进行分类,当它的 margin 越大的时候,分类的 confidence 越大。对于一个包含
n 个点的数据集,我们可以很自然地定义它的 margin 为所有这n 个点的 margin 值中最小的那个。于是,为了使得分类的 confidence 高,我们希望所选择的超平面hyper plane 能够最大化这个 margin 值。
通过上节,我们已经知道:
1、functional margin 明显是不太适合用来最大化的一个量,因为在 hyper plane 固定以后,我们可以等比例地缩放
w 的长度和b 的值,这样可以使得2、而 geometrical margin 则没有这个问题,因为除上了
w 和b 的时候的值是不会改变的,它只随着 hyper plane 的变动而变动,因此,这是更加合适的一个 margin 。
这样一来,我们的 maximum margin classifier 的目标函数可以定义为:
当然,还需要满足一些条件,根据 margin 的定义,我们有
其中
(等价于
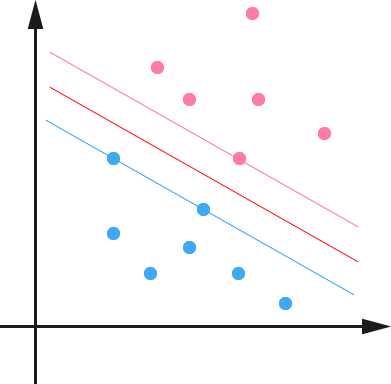
通过求解这个问题,我们就可以找到一个 margin 最大的 classifier ,如下图所示,中间的红色线条是 Optimal Hyper Plane ,另外两条线到红线的距离都是等于
通过最大化 margin ,我们使得该分类器对数据进行分类时具有了最大的 confidence,从而设计决策最优分类超平面。
1.5、到底什么是Support Vector
上节,我们介绍了Maximum Margin Classifier,但并没有具体阐述到底什么是Support Vector,本节,咱们来重点阐述这个概念。咱们不妨先来回忆一下上节1.4节最后一张图:
可以看到两个支撑着中间的 gap 的超平面,它们到中间的纯红线separating hyper plane 的距离相等,即我们所能得到的最大的 geometrical margin
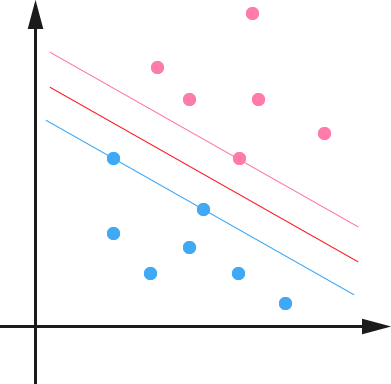
或亦可看下来自此PPT中的一张图,Support Vector便是那蓝色虚线和粉红色虚线上的点:
很显然,由于这些 supporting vector 刚好在边界上,所以它们满足
(还记得我们把 functional margin 定为 1 了吗?上节中:“处于方便推导和优化的目的,我们可以令
。当然,除了从几何直观上之外,支持向量的概念也可以从下文优化过程的推导中得到。
OK,到此为止,算是了解到了SVM的第一层,对于那些只关心怎么用SVM的朋友便已足够,不必再更进一层深究其更深的原理。












- [机器学习] 支持向量机通俗导论节选(一)
- [机器学习] 支持向量机通俗导论节选(二)
- 支持向量机通俗导论(一)
- 机器学习之支持向量机通俗导论(理解SVM的三层境界)
- 【机器学习】支持向量机通俗导论(理解SVM的三层境界)
- 支持向量机通俗导论-我的学习笔记(一)
- 支持向量机通俗导论(二)
- 支持向量机通俗导论(三)
- 支持向量机通俗导论
- 支持向量机通俗导论
- 支持向量机通俗导论
- 支持向量机通俗导论
- 支持向量机通俗导论
- 转 支持向量机通俗导论(理解SVM的三层境界)——机器学习第一步SVM
- 补充支持向量机通俗导论
- 机器学习(一)支持向量机(Support Vector Machine)
- 机器学习笔记08:支持向量机(一)(SVM)
- 理解SVM的三层境界-支持向量机通俗导论
- listview中的imageview获取网络图片重复显示的问题
- OCP 1Z0 052 V9.02 115
- vc++教程之win7下基址定位处理
- ORB BREAK http://rogerioferis.com/VisualRecognitionAndSearch/Resources.html
- 图片上传
- [机器学习] 支持向量机通俗导论节选(一)
- boost asio库 同步socket连接示例
- 电源管理API
- 类型转换5
- 虚析构函数
- Android 设计指南 – 风格
- 【学生管理系统】--常见的错误
- 解析json将json转化为DataTable
- RedHat9 下 Linux编译工具Gcc-4.4.3的安装详解


