Hadoop Mapreduce从零开始
来源:互联网 发布:音频编辑软件for mac 编辑:程序博客网 时间:2024/06/07 02:56
前言
Hadoop简介
Tips
HDFS架构
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
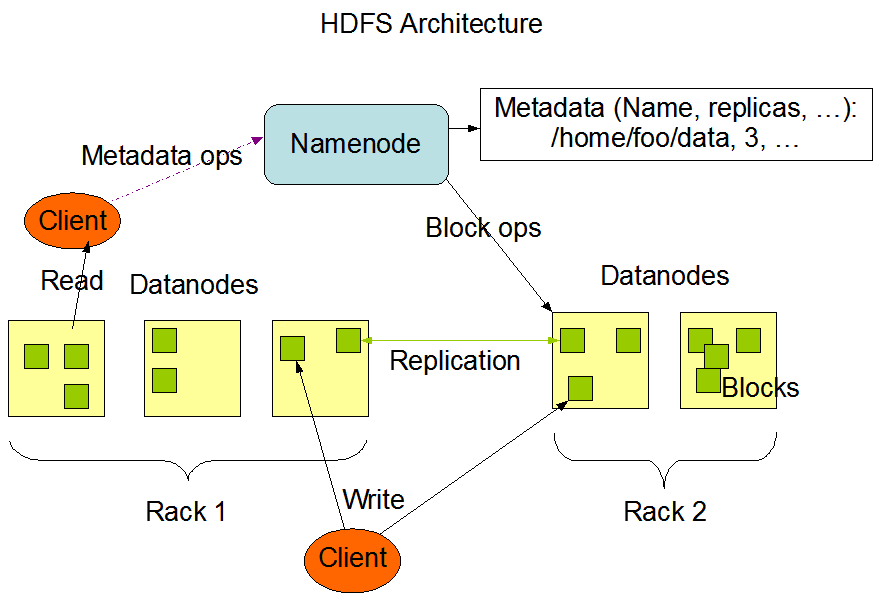
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
MapReduce
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(job configuration)。然后,Hadoop的 job client提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给job-client。
虽然Hadoop框架是用JavaTM实现的,但Map/Reduce应用程序则不一定要用 Java来写 。Hadoop Streaming是一种运行作业的实用工具,它允许用户创建和运行任何可执行程序 (例如:Shell工具)来做为mapper和reducer。Hadoop Pipes是一个与SWIG兼容的C++ API (没有基于JNITM技术),它也可用于实现Map/Reduce应用程序。
可能诸位看到这里也不知道MapReduce是用来干啥的,举个比较经典的例子,给若干篇文章,需要归纳出每个单词出现的次数。用MapReduce统计是这样的过程:首先对每篇文章进行处理,处理成<word, 1>的k/v对(因为对于每个单词,出现一次就有一个word,1的键值对),经过处理后会有一张大列表,列表中的每个元素就是一个键值对,接着进行排序,按照key的字典序进行排序,排序之后,对这个大表进行分割,分割到不同的机器上进行统计,每个节点统计之后再merge到一起得到最终的结果。具体如下:
第一篇文章 I am a boy.
第二篇文章 I am a girl.
第一篇文章处理之后的列表:
I 1am 1a 1boy 1
第二篇文章处理后的列表:
I 1am 1a 1girl 1
这两篇文章的列表合并起来得到一个大表:
I 1am 1a 1boy 1I 1am 1a 1girl 1
按照key的字典序进行排序:
a 1a 1am 1am 1boy 1girl 1I 1I 1
接着将前4行和后四行分别给两个reduce。
第一个reduce统计的结果:
am 2I 2
第二个reduce统计的结果:
a 2boy 1girl 1
两个reduce统计的结果merge:
a 2am 2boy 1girl 1I 2
这样就得到了最终的结果。
Hadoop部署(没有自己造轮子,在别人部署好的基础上直接使用了)
Hadoop常用命令
MapReduce使用方法
MapReduce流程

1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
Map、Reduce任务中Shuffle和排序的过程

Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
MapReduce实战
streaming
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ 这里用/bin/cat命令当做mapper -reducer /bin/wc 这里用/bin/wc命令当做reducer这里我们用C++写mapper和reducer。mapper.cc
#include <iostream>#include <string>using namespace std;int main(){ string str; while(cin>>str){ cout<<str<<" "<<"1"<<endl; } return 0;}reducer.cc
#include <iostream>#include <map>using namespace std;int main(){ map<string, int> wordCount; map<string, int>::iterator it; string key; int value; int count; while(cin>>key>>value) { wordCount[key] += value; } for(it = wordCount.begin(); it != wordCount.end(); it++){ cout<<it->first<<" "<<it->second<<" fuck!"<<endl; } return 0;}input文件内容
hellohellohelloworldworld提交作业脚本(命令很长,所以写成一个脚本方便点)mapreduce.sh
#!/bin/bashinput="/user/serving/zhuzekun/input" #这里要保证input已经put到hadoop的/user/serving/zhuzekun/下output="/user/serving/zhuzekun/output/"SPLIT_SIZE=1000000000MAP_CAP=300REDUCE_CAP=300NUM_MAP=50NUM_REDUCE=5hadoop_home_path="/home/serving/hadoop_client/hadoop"hadoop_bin="${hadoop_home_path}/bin/hadoop"hadoop_streaming_file="${hadoop_home_path}/contrib/streaming/hadoop-streaming-1.2.0.jar"${hadoop_bin} fs -rmr ${output}${hadoop_bin} jar ${hadoop_streaming_file} \ -partitioner "org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner" \ -jobconf stream.num.map.output.key.fields=1 \ -jobconf num.key.fields.for.partition=1 \ -input ${input} \ -output ${output} \ -mapper "mapper" \ -file "mapper" \ -reducer "reducer" \ -file "reducer" \ -jobconf stream.map.output.field.separator=" " \ -jobconf mapred.job.map.capacity=${MAP_CAP} \ -jobconf mapred.job.reduce.capacity=${REDUCE_CAP} \ -jobconf mapred.map.tasks=${NUM_MAP} \ -jobconf mapred.reduce.tasks=${NUM_REDUCE}\ -jobconf mapred.min.split.size=${SPLIT_SIZE} \ -jobconf mapred.job.name="MP" \ -jobconf mapred.job.priority=NORMALif [ $? -ne 0 ]; then exit 1firm -rf /data8/zhuzekun/merge${hadoop_bin} fs -getmerge ${output} /data8/zhuzekun/merge流程:
- g++ -o mapper mapper.cc 编译出mapper可执行文件
- g++ -o reducer reducer.cc 编译出reducer可执行文件
- sh mapreduce.sh 运行提交作业脚本
- 等执行完之后会在/data8/zhuzekun/文件夹下产生一个merge文件,里面保存着结果。
awk脚本与streaming
在实际工作中,常常对大量的日志进行处理,awk能方便地处理日志。awk具体讲解看http://zh.wikipedia.org/wiki/AWK。上文提到streaming的mapper和reducer可以是脚本文件,awk脚本属于其中一种。两者结合能方便地处理日志。这里以统计日志中每个ip的访问次数为例,讲解awk脚本如何应用在MapReduce中。mapper.awk
BEGIN{ FS=" ";}{ printf("%s %d\n", $11, 1); #日志文件的第11列是ip}END{}reducer.awk
BEGIN{ FS=" ";}{ word_count[$1] += $2;}END{ for(i in word_count){ printf("%s %d\n", i, word_count[i]); }}mapreduce.sh#!/bin/bashinput="/user/serving/log/aries/merged/20140715.st/part-00999"output="/user/serving/zhuzekun/output/"SPLIT_SIZE=1000000000MAP_CAP=300REDUCE_CAP=300NUM_MAP=50NUM_REDUCE=5hadoop_home_path="/home/serving/hadoop_client/hadoop"hadoop_bin="${hadoop_home_path}/bin/hadoop"hadoop_streaming_file="${hadoop_home_path}/contrib/streaming/hadoop-streaming-1.2.0.jar"${hadoop_bin} fs -rmr ${output}${hadoop_bin} jar ${hadoop_streaming_file} \ -partitioner "org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner" \ -jobconf stream.num.map.output.key.fields=1 \ -jobconf num.key.fields.for.partition=1 \ -input ${input} \ -output ${output} \ -mapper "awk -f mapper.awk" \ -file "mapper.awk" \ -reducer "awk -f reducer.awk" \ -file "reducer.awk" \ -jobconf stream.map.output.field.separator=" " \ -jobconf mapred.job.map.capacity=${MAP_CAP} \ -jobconf mapred.job.reduce.capacity=${REDUCE_CAP} \ -jobconf mapred.map.tasks=${NUM_MAP} \ -jobconf mapred.reduce.tasks=${NUM_REDUCE}\ -jobconf mapred.min.split.size=${SPLIT_SIZE} \ -jobconf mapred.job.name="MP" \ -jobconf mapred.job.priority=NORMALif [ $? -ne 0 ]; then exit 1firm -rf /data8/zhuzekun/merge${hadoop_bin} fs -getmerge ${output} /data8/zhuzekun/merge
运行mapreduce脚本就可以上传统计ip次数的作业了。小结
通过两个小demo,实现了简单的mapreduce作业,有了入门之后,剩下的都是万变不离其宗了,无非是逻辑结构、实现方式更复杂一些罢了。
- Hadoop Mapreduce从零开始
- 从零开始学习Hadoop--第7章 Hadoop MapReduce的运行机制
- 从零开始学习Hadoop--第2章 第一个MapReduce程序
- 从零开始学习Hadoop--第6章 MapReduce的输入输出
- 从零开始学Hadoop——浅析MapReduce(一)
- 从零开始学Hadoop——浅析MapReduce(二)
- MapReduce&hadoop
- Hadoop MapReduce
- Hadoop MapReduce
- Hadoop MapReduce
- Hadoop Mapreduce
- Hadoop MapReduce
- hadoop mapreduce
- hadoop mapreduce
- hadoop mapreduce
- Hadoop mapreduce
- Hadoop MapReduce
- Hadoop/mapreduce
- poi 3.9 Range发现一个bug
- linux下libxml2库的使用说明
- ------Java基础强化------适合初学者
- Code blocks error: 'thread' is not a member of 'std'|
- P6spy sql跟踪使用
- Hadoop Mapreduce从零开始
- hdu1969
- 设置了error_reporting(E_ALL)还是不显示错误
- HDU 4255 A Famous Grid
- 交大OJ 2113题
- 扩展欧几里得算法
- java一个多线程的经典例子
- IM系统中聊天记录模块的设计与实现
- Bayes在语音识别中的实际应用


