跳跃表(Skip List)深入介绍
来源:互联网 发布:java高级工程师培训 编辑:程序博客网 时间:2024/06/05 18:19
为什么选择跳跃表
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。
想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树
出来吗? 很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,
还要参考网上的代码,相当麻烦。
用跳跃表吧,跳跃表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,
它的效率和红黑树以及 AVL 树不相上下,但跳跃表的原理相当简单,只要你能熟练操作链表,
就能轻松实现一个 SkipList,其时间复杂度绝大多是情况下为O(lgn)
跳跃表作者
跳表是由William Pugh发明。他在 Communications of the ACM June 1990, 33(6) 668-676 发表了Skip lists: a probabilistic alternative to balanced trees,在该论文中详细解释了跳表的数据结构和插入删除操作。现在是University of Maryland, College Park(马里兰大学伯克分校,位于马里兰州,全美大学排名在五六十名左右的样子)大学的一名教授。他和他的学生所作的研究深入的影响了java语言中内存池实现。
作者对于跳跃表的解释
Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
有序链表的搜索
考虑一个有序链表:

从该有序链表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数
为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找(有序数组能用二分查找,T(n)=Θ(lgn))。类似二叉
搜索树,我们把一些节点提取出来,作为索引。得到如下结构(一种通过“空间来换取时间”的算法):

这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:

这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。
跳跃表
下面的结构是就是跳跃表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。
(跳跃表的起始位置默认是从左上角开始的,链表的最左端定义-1而且每次都执行上升操作,为了不让左上角的元素空缺)

跳跃表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳跃表的搜索

例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值大,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值大,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,往后面找
(5) 比较 117, 等于 117, 找到了节点。
跳跃表的插入
先确定该元素要占据的层数 K(采用投硬币的方式,这完全是随机的;硬币投出正面向上一层,再投一次,直到投出第一个反面为止)
然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2(投硬币前两次正面,第三次反面)

如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4(投硬币前四次正面,第五次反面)

投硬币决定 K
插入元素的时候,元素所占有的层数完全是随机的,通过一下随机算法产生:
相当与做一次投硬币的实验,如果遇到正面,继续投,遇到反面,则停止,
用实验中投硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,
K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
跳跃表的高度
跳跃表高度在极高的概率下为O(lgn)
跳跃表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点(直接删节点,修改相关指针即可)。
例子:删除 71

下图更直观地展现了跳跃表的数据结构,不同于一般的链表,跳跃表额引用域有不止一个指针,可以建立指针数组。

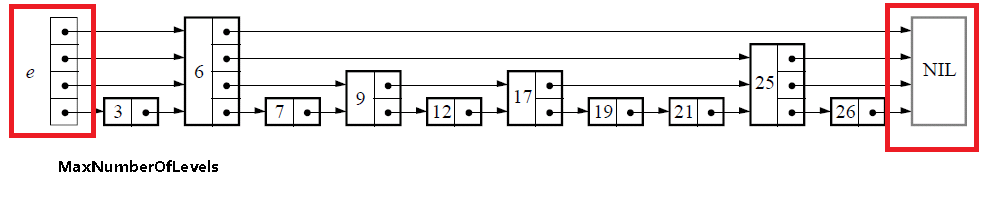
http://kenby.iteye.com/blog/1187303
http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html
- 跳跃表(Skip List)深入介绍
- 跳跃表(Skip List)深入介绍
- 跳跃表(Skip List)
- 跳跃表(Skip List)
- Skip List(跳跃表)
- 跳跃表Skip List
- 跳跃表 Skip List
- LevelDB中的Skip List(跳跃表)
- 跳跃表(skip list) 的实现
- LevelDB中的Skip List(跳跃表)
- Skip List(跳跃表)与ConcurrentSkipListMap
- Skip List跳跃链表
- skip list跳跃表实现
- Skip List(跳跃表)原理详解与实现
- 数据结构之六(跳跃表Skip List)
- Skip List(跳跃表)原理详解与实现
- Skip List(跳跃表)原理详解与实现
- Skip List(跳跃表)原理详解与实现
- php集成环境安装与测试
- 2014年趋势科技夏令营总结
- 程序的运行
- 《Thinking in java》学习笔记
- Unity3D研究院之初探PoolManager插件
- 跳跃表(Skip List)深入介绍
- Java一对一关系的演示
- MFC CStatic控件在DrawItem中自绘
- 在win7系统下使用TortoiseGit(乌龟git)简单操作Git@OSC
- 正在运行的android程序,再次点击程序图标避免再次重新启动程序解决办法
- 比较有意思的话
- HDUJ 2043 密码
- php安装模式cgi,fastcgi,php_mod比较
- Oracle表或者视图的行转列[练习]


