拓扑排序
来源:互联网 发布:淘宝双十一的营销策略 编辑:程序博客网 时间:2024/06/06 01:06
一、概述
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若<u,v> ∈E(G),则u在线性序列中出现在v之前。这样的线性序列称为满足拓扑次序(TopoiSicai Order)的序列,简称拓扑序列。
注意:
①若将图中顶点按拓扑次序排成一行,则图中所有的有向边均是从左指向右的。
②若图中存在有向环,则不可能使顶点满足拓扑次序。
③一个DAG的拓扑序列通常表示某种方案切实可行。
④一个DAG可能有多个拓扑序列。
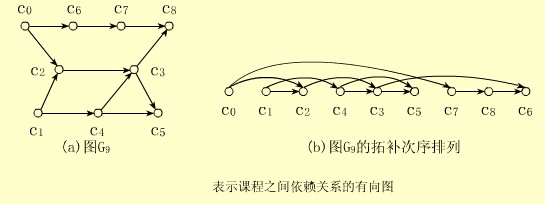
【例】对图G9进行拓扑排序,至少可得到如下的两个(实际远不止两个)拓扑序列:C0,C1,C2,C4,C3,C5,C7,C8,C6和C0,C7,C9,C1,C4,C2,C3,C6,C5。
⑤当有向图中存在有向环时,拓扑序列不存在
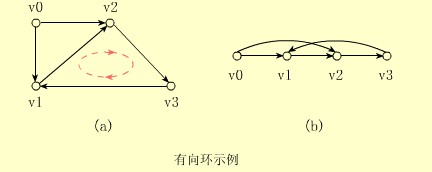
【例】下面(a)图中的有向环重排后如(b)所示,有向边<v3,vl>和其它边反向。若有向图被用来表示某项工程实施方案或某项工作计划,则找不到该图的拓扑序列(即含有向环),就意味着该方案或计划是不可行的。
二、无前趋的顶点优先的拓扑排序方法
该方法的每一步总是输出当前无前趋(即入度为零)的顶点,其抽象算法可描述为:
NonPreFirstTopSort(G){ //优先输出无前趋的顶点
while(G中有入度为0的顶点)do{
从G中选择一个人度为0的顶点v且输出之;
从G中删去v及其所有出边;
}
if(输出的顶点数目<|V(G)|) //若此条件不成立,则表示所有顶点均已输出,排序成功。
Error("G中存在有向环,排序失败!");
}
注意:
无前趋的顶点优先的拓扑排序算法在具体存储结构下,为便于考察每个顶点的入度,可保存各顶点当前的入度。为避免每次选入度为0的顶点时扫描整个存储空间,可设一个栈或队列暂存所有入度为零的顶点:
在开始排序前,扫描对应的存储空间,将人度为零的顶点均入栈(队)。以后每次选入度为零的顶点时,只需做出栈(队)操作即可。
拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。
下面以图为例,来说明拓扑排序算法的执行过程。
拓扑排序的图形说明:
(1) 在(a)图中v0和v1的入度都为0,不妨选择v0并输出之,接着删去顶点v0及出边<0,2>,得到的结果如(b)图所示。
(2) 在(b)图中只有一个入度为0的顶点v1,输出v1,接着删去v1和它的三条出边<1,2>,<1,3>和<1,4>,得到的结果如(c)图所示。
(3) 在(c)图中v2和v4的入度都为0,不妨选择v2并输出之,接着删去v2及两条出边<2,3>和<2,5>,得到的结果如(d)图所示。
(4) 在(d)图上依次输出顶点v3,v4和v5,并在每个顶点输出后删除该顶点及出边,操作都很简单,不再赘述。
三、无后继的顶点优先拓扑排序方法
1、思想方法
该方法的每一步均是输出当前无后继(即出度为0)的顶点。对于一个DAG,按此方法输出的序列是逆拓扑次序。因此设置一个栈(或向量)T来保存输出的顶点序列,即可得到拓扑序列。若T是栈,则每当输出顶点时,只需做人栈操作,排序完成时将栈中顶点依次出栈即可得拓扑序列。若T是向量,则将输出的顶点从T[n-1]开始依次从后往前存放,即可保证T中存储的顶点是拓扑序列。
2、抽象算法描述
NonSuccFirstTopSort(G){ //优先输出无后继的顶点
while(G中有出度为0的顶点)do {
从G中选一出度为0的顶点v且输出v;
从G中删去v及v的所有人边
}
if(输出的顶点数目<|V(G)|)
Error("G中存在有向环,排序失败!");
}
四、利用深度优先遍历对DAG拓扑排序
当从某顶点v出发的DFS搜索完成时,v的所有后继必定均已被访问过(想像它们均已被删除),此时的v相当于是无后继的顶点,因此在DFS算法返回之前输出顶点v即可得到 DAG的逆拓扑序列。
其中第一个输出的顶点必是无后继(出度为0)的顶点,它应是拓扑序列的最后一个顶点。若希望得到的不是逆拓扑序列,同样可增加T来保存输出的顶点。若假设T是栈,并在DFSTraverse算法的开始处将T初始化,
利用DFS求拓扑序列的抽象算法可描述为:
void DFSTopSort(G,i,T){ //在DisTraverse中调用此算法,i是搜索的出发点,T是栈
int j;
visited[i]=TRUE; //访问i
for(所有i的邻接点j) //即<i,j>∈E(G)
if(!visited[j])
DFSTopSort(G,j,T);
//以上语句完全类似于DFS算法
Push(&T,i); //从i出发的搜索已完成,输出i
}
只要将深度优先遍历算法DFSTraverse中对DFS的调用改为对DFSTopSort的调用,即可求得拓扑序列T。
若G是一个DAG,则用DFS遍历实现的拓扑排序与NonSuccFirstTopSort算法完全类似;但若C中存在有向环,则前者不能正常工作。
*************************************************************************
dfs实现拓扑排序 函数(算法竞赛入门经典)
E(u,v)
int c[maxn];
int topo[maxn],t;
bool dfs(int u)
{
c[u]=-1; //开始访问该顶点
for(int v=0;v<n;v++)
{
if(G[u][v]==1)
{
if(c[v]<0) return false; //c[v]=-1代表正在访问该定点(即递归调用dfs(u)正在帧栈中,尚未返回)
else if(!c[v] && !dfs(v)) return false; //(c[v]==0 && dfs(v)==false即当前顶点没有后即顶点时,
//开始返回 (结束))
}
}
c[u]=1; //访问结束
topo[--t]=u;
return true;
}
bool toposort()
{
t=n;
memset(c,0,sizeof(c));
for(int u=0;u<n;u++)
if(!c[u]) if(!dfs()) return false;
return ture;
}
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 【拓扑排序】
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 拓扑排序
- 远离身边的垃圾人
- 通过广播关闭应用程序(每个Activity)和连续点击两次返回键关闭应用程序
- Android4.4深入浅出之SurfaceFlinger与Client通信框架(一)
- windows消息和消息队列
- 抓包工具
- 拓扑排序
- HDUJ 1047 Integer Inquiry
- MyBatis Generator generatorConfig.xml配置详解
- Spring 两个核心技术
- 在学校学了3年,用了半年多的as3
- pdf转换器哪个简单好用
- 云计算技术背后的天才程序员:Open VSwitch鼻祖Martin Casado
- poj2528-Mayor's posters
- 简单制作Makefile 文件


