Hadoop_WordCount示例_运行详解
来源:互联网 发布:上海银行 淘宝金卡 编辑:程序博客网 时间:2024/05/17 15:57
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
1、MapReduce理论简介
1.1 MapReduce编程模型
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。
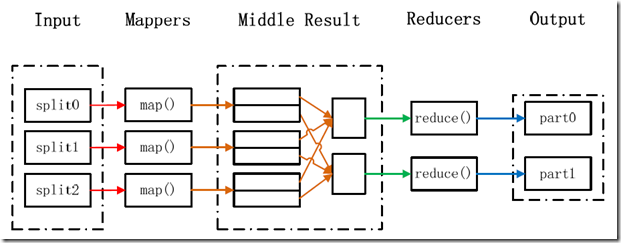
MapReduce处理大数据集的过程
2、运行WordCount程序
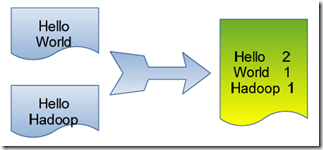
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
2.1 准备工作
现在以"hadoop"普通用户登录"Master.Hadoop"服务器。
1)创建本地示例文件
首先在"/home/hadoop"目录下创建文件夹"file"。
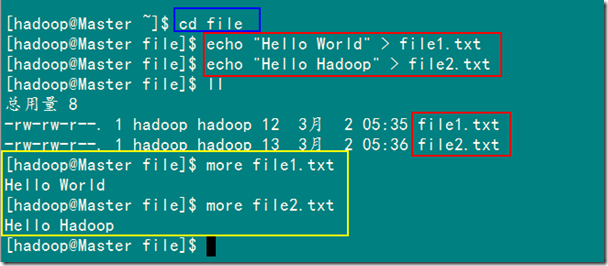
接着创建两个文本文件file1.txt和file2.txt,使file1.txt内容为"Hello World",而file2.txt的内容为"Hello Hadoop"。
2)在HDFS上创建输入文件夹

3)上传本地file中文件到集群的input目录下

2.2 运行例子
1)在集群上运行WordCount程序
备注:以input作为输入目录,output目录作为输出目录。
已经编译好的WordCount的Jar在"/usr/hadoop"下面,就是"hadoop-examples-1.0.0.jar",所以在下面执行命令时记得把路径写全了,不然会提示找不到该Jar包。
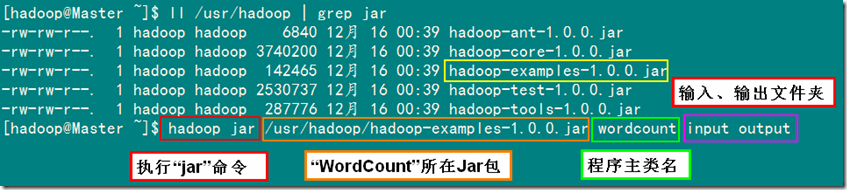
2)MapReduce执行过程显示信息
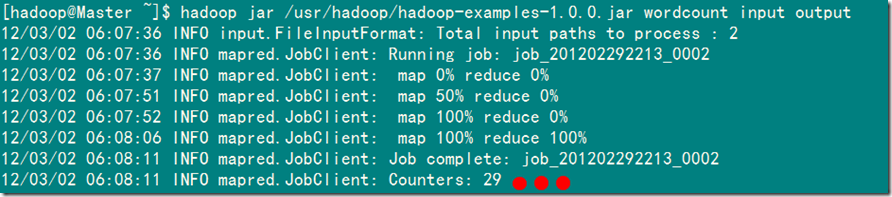
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是2个,reduce的task数量是一个。map的输入record数是2个,输出record数是4个等信息。
2.3 查看结果
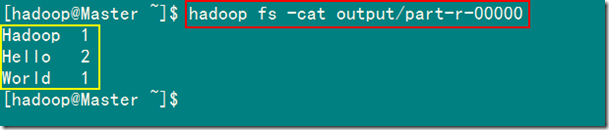
1)查看HDFS上output目录内容

从上图中知道生成了三个文件,我们的结果在"part-r-00000"中。
2)查看结果输出文件内容
4、WordCount处理过程
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。

图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。

图4-4 Reduce端排序及输出结果
- Hadoop_WordCount示例_运行详解
- Hadoop示例程序WordCount运行及详解
- Hadoop示例程序WordCount运行及详解
- caffe典型识别示例CIFAR_10的运行详解
- _渲染图像示例
- Kettle_js脚本_示例
- J2me后台运行示例
- 程序唯一示例运行
- sqlite运行错误示例
- Camel运行示例
- 运行ReactNative示例
- timit运行示例一
- timit运行示例二
- cocos2dx-lua 示例运行
- 嵌入式小波零树(EZW)算法的过程详解和Matlab代码(4)运行示例
- 读书笔记_运行库
- 02_运行多线程
- LINQ基础_简单示例
- NGUI相关教程
- Application1
- Java反射机制
- ZOJ 4257 Most Powerful
- button 修改 title 和 image偏移量
- Hadoop_WordCount示例_运行详解
- 产品经理入职后要做的12件事
- poj 1088 滑雪
- UVa 165 - Stamps 解题报告(暴力)
- ASP.NET Cookie的存储与读取
- HDU - 2276 Kiki & Little Kiki 2
- vc++取得系统信息,并实时刷新
- MyEclipse,Eclipse安装findBugs插件技巧
- 完美框架


