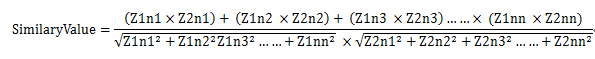publicclass CosineSimilarAlgorithm {
publicstatic double getSimilarity(String doc1, String doc2) {
if(doc1 != null&& doc1.trim().length() > 0&& doc2 != null
&& doc2.trim().length() > 0) {
Map<Integer,int[]> AlgorithmMap = newHashMap<Integer, int[]>();
for(inti = 0; i < doc1.length(); i++) {
chard1 = doc1.charAt(i);
if(isHanZi(d1)){
intcharIndex = getGB2312Id(d1);
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null&& fq.length == 2){
fq[0]++;
}else{
fq = newint[2];
fq[0] = 1;
fq[1] = 0;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
for(inti = 0; i < doc2.length(); i++) {
chard2 = doc2.charAt(i);
if(isHanZi(d2)){
intcharIndex = getGB2312Id(d2);
if(charIndex != -1){
int[] fq = AlgorithmMap.get(charIndex);
if(fq != null&& fq.length == 2){
fq[1]++;
}else{
fq = newint[2];
fq[0] = 0;
fq[1] = 1;
AlgorithmMap.put(charIndex, fq);
}
}
}
}
Iterator<Integer> iterator = AlgorithmMap.keySet().iterator();
doublesqdoc1 = 0;
doublesqdoc2 = 0;
doubledenominator = 0;
while(iterator.hasNext()){
int[] c = AlgorithmMap.get(iterator.next());
denominator += c[0]*c[1];
sqdoc1 += c[0]*c[0];
sqdoc2 += c[1]*c[1];
}
returndenominator / Math.sqrt(sqdoc1*sqdoc2);
}else{
thrownew NullPointerException(
" the Document is null or have not cahrs!!");
}
}
publicstatic boolean isHanZi(charch) {
return(ch >= 0x4E00&& ch <= 0x9FA5);
}
/**
* 根据输入的Unicode字符,获取它的GB2312编码或者ascii编码,
*
* @param ch
* 输入的GB2312中文字符或者ASCII字符(128个)
* @return ch在GB2312中的位置,-1表示该字符不认识
*/
publicstatic short getGB2312Id(charch) {
try{
byte[] buffer = Character.toString(ch).getBytes("GB2312");
if(buffer.length != 2) {
return-1;
}
intb0 = (int) (buffer[0] & 0x0FF) - 161;
intb1 = (int) (buffer[1] & 0x0FF) - 161;
return(short) (b0 * 94+ b1);
}catch(UnsupportedEncodingException e) {
e.printStackTrace();
}
return-1;
}
}