和码5.0版的说明
来源:互联网 发布:三个月雅思6.5知乎 编辑:程序博客网 时间:2024/06/03 21:37
和码5.0版的说明
和码字形编码的前一个方案是4.2版,完成于2009年10月《点击看记录》,之后的4年半时间里,字根表与编码方法没有修改过。
4.2版之后,我并没有停止对和码方案的推敲,我看和码一直是带着挑剔否定的态度,在输入汉字时,也是推敲可能存在的改变。
虽然我很早就写出了《和码是最好最终的汉字形码》的文章。这篇文章说明了字形编码的几大的基本问题,如:①为什么要用数字码;②为什么是25个数字码;③为什么要用以“横竖撇捺”四个基本笔画分区;④为什么每个汉字是四个码。
但还有些问题没有说清楚。如:编码是否是汉字字形信息的代码?汉字形码是以检索输入汉字为目的,还是以包含更多的字形信息为目的?形相似的字根是否应该归并在一起?为什么和码不能分四块取,依顺序取四个编码?为什么字形技术可以用于字形教学?为什么字形教学需要采用汉字字形技术?等等。只有对这些问题有了清楚的回答,才能建立坚固的信心。
很早的时候我就想到字根“米”是“木”的延展,应该把“十土卄木米”放在一起,这更能说明汉字字根的关联,说明汉字字形的表义特点,尽管第一笔画不同。但我没有足够多的理由去做个新版。
2013年6月,我在看汉字的25个常用字根时,忽然感到,字根表中的两个横(一)(码11,码21),两个口(码33, 码34),是个问题,怎样区分这两组字形相同的字根,初学者都会问到。尽管有清楚的解释,但仍是增加了初学者的难度。
英文字母表中,iL(Il), Cc, Oo, 给书写辨认带来了许多的麻烦。
如果以和码字根表为基础,建立字形字母表,就更不能有两个“一”,两个“口”了。
我责备自己为什么这么多年,都没有注意到这个问题。且很多人都问过我,怎样区别两个“一”(码11, 码21),怎样区别两个“口”(码33,34),我也解释过很多次。
和码的研究,开始是以汉字输入为目的,因此特别注重低重码率。因为汉字中,字根“一”与“口”出现的频率特别大,将与其它笔画相交的横分出来,形成两个码(11,21)“一”,将中间有笔画的“口”分出来,形成两个码(33,34)“口”,不失为一个好办法。
后来我也认识到,对于3800(或5200)个常用汉字,形码的分辨率很好,即使不分“一”与“口”,常用字的重码也不严重。
当和码字形技术应用在于汉字字形教学时,“一”分为两个,“口”分为两个,增加了很多教学中的麻烦。
我试着调整字根表,合并码11与21,33与34,并把第二、三区(列)交换,就形成了“横竖十撇捺”的排布,这比“横横竖撇点”容易解释,容易记忆得多。
汉字的基本笔画是“横竖撇捺”,和码4.2版试着从“横横竖撇点”来解释25个常用字根,以建立字形基础概念,进而解释所有的汉字。
现在我认为“横竖十撇捺”更简单,更能体现汉字字形的合理,简单,与易记。
2014年03月初,我开始做和码5.0版的编码,过程中又考虑了很多的问题,在这里做一些记录。
和码5.0版 25个常用字根表
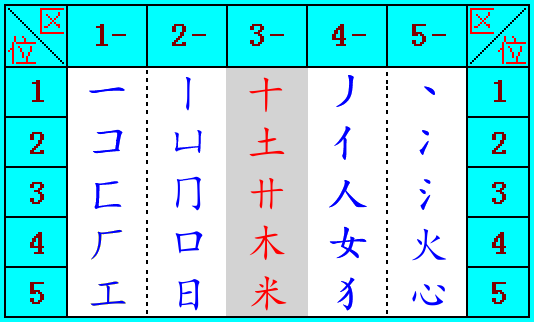
以“横竖十撇捺”为起点,建立汉字字形概念
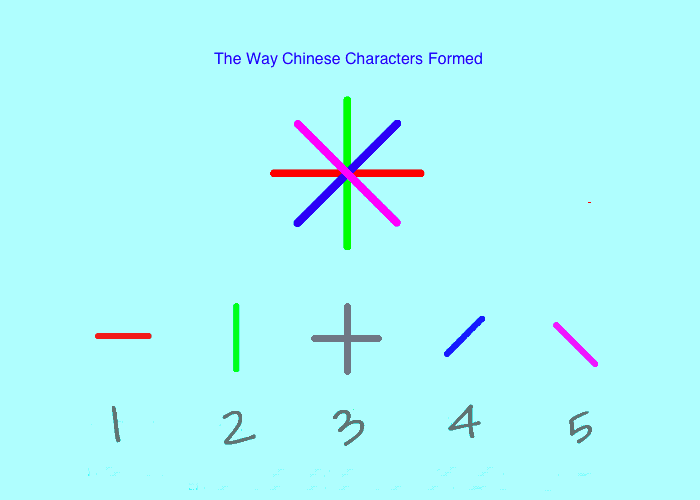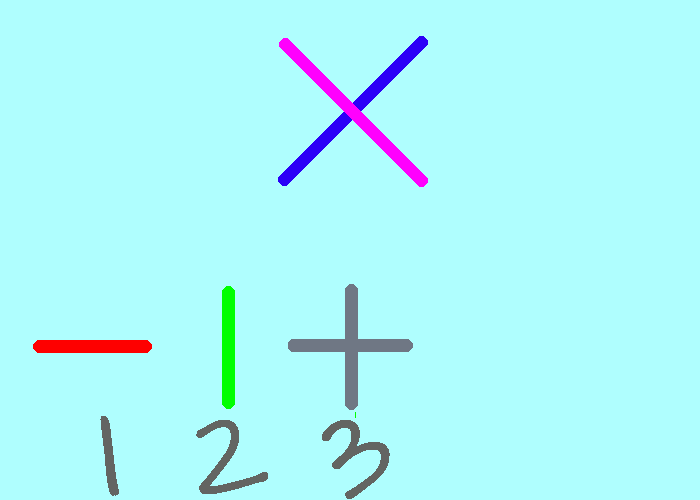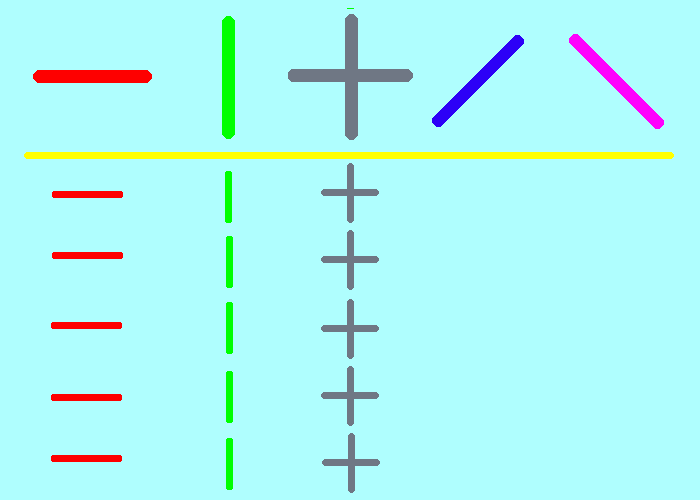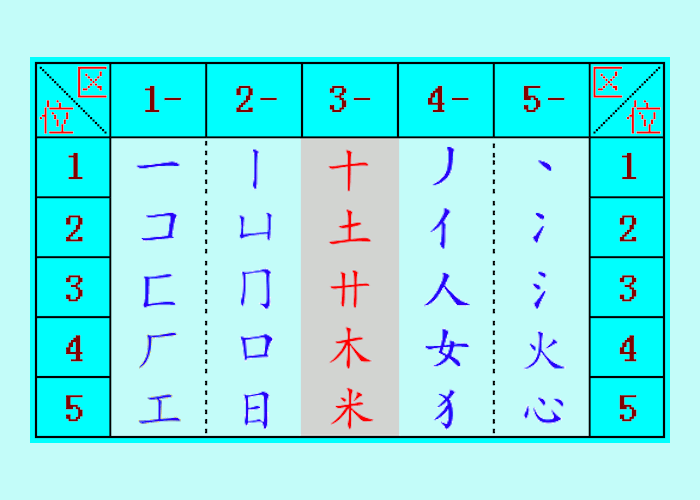
和码字根表(25个常用字根表的拓展)
说明,以下的统计数字,都是以国标字库GB2312(含6763个字)为范围,常用字一般为3800个(或5200个)。
一、字形编码是否是字形信息的代码,是否应该尽量多地包含字形信息?
我得出的答案是否定的。字形编码的本质是汉字集的检索(输入)工具,字形编码不等于完整的字形信息,以检索为目的的字形编码,不必包含完整全面的字形信息。
汉字有简单的,如:二,三,如,困、圆、从、茹、染、始、吩、算、莫、保,等等;
汉字有复杂的,如:韱、肈、糮、龔、襷、裫、癟、褫、癛、殛、夔、馕、蠻,等等;
汉字字形信息包括,字根,笔顺,与字根位置等信息。
要求字形编码包含所有的字形信息,那么:
1)、字根表应包含尽量多的汉字字根;
2)、单字编码不能固定码长;
3)、编码要取尽所有的汉字字根与笔画;
4)、编码还要包含字根间相对位置的信息。
这样的编码就非常的复杂。
我们知道,给出几个英文字母,就能唯一地组成的英文单字,如:English, Chinese。
对于上面的字根表,当给出42,34,42的编码时,你没有办法组成一个字,因为同一个码里有多个字根,字根的组合又有多个不同的位置。
但是对于一个给定的汉字集,一组编码,如42,34,42,(依照一定的规则)可以对应一个,或几个单字。
因此汉字字形编码,是对于给定汉字集的检索(输入)工具。检索对象(汉字集)是不可少的,离开了检索对象,字形编码对应不了汉字。
离开了检索对象(汉字集),想用字形编码反演出字形,是不可能的。这个结论对于所有的字形编码(笔画编码与字根编码)都是一样的。
因此字形编码的本质即:字形编码是汉字集的检索工具(字形编码离不开背后的汉字集)。字形编码不可能,也不必要包含所有的字形信息。
有了这个结论,就为形码必须取全字形信息的困难解了套,为以下编码问题给出了理论依据:
1)、字根表不必包含所有的汉字字根;
2)、编码可以固定码长;
3)、编码不必取尽所有的字根与笔画;
4)、单字可以分块(在定点位置)取码;
5)、字形编码的目的是(对汉字集)检索,编码方案应该:
①编码容易(字根表简单,取码方法简单);
②检索效率高(输入码数少,重码少)。
6)、可以制定有利于检索的规则。
二、为什么不是分四块,顺序取四个码?
有了对字形编码本质的认识,就容易接受《和码是最好最终的汉字形码》一文中,单字最好取四个码的结论。
既然单字是四个码,为什么不是最多分四块,顺序取四个字根码?
1)、《最好最终的汉字形码》一文中,也说明了,绝大多数汉字的输入,只需前三码,第四码只是少数情况下才用到的辅助码。
2)、单字有一块字,二块字,三块字,四块字与多块字。三块字占多数(70%左右)。
对于四块字,顺序取四个码。那么对于三块字,是否也要顺序取四码呢?
如果对三块字,也顺序取四码,以下常用字根都要取两个码,:
穴(22,43):窃,容,窑,窜,窝,窗,窍,窒,窖,窘,窟,窀,窈,窕,窠,窨,窭,窸,窝,窕,梥,窇,窉,窌,窐,窓,窙,窞,窣,窩,窮,窸;
阝(12,21):阶,防,际,阿,降,限,除,险,陷,陪,坠,陨,阮,陀,陂,陉,陟,陧,陬;
马(15,11):驱,驳,驶,驼,骄,骆,验,驹,骚,驷,驸,驺,驿,骀,骁,骈,骋,骍,骐,骒,骓;
虫(23,21):蛇,蜓,蜂,蜻,蜡,蝇,蝶,蚣,蛉,蛤,蜈,蛹,蝗,蝙;
足(23,21):跨,跳,路,跟,踢,踏,踩,蹈,跷,跺,踊,蹂;
禾(41,34):季,积,秧,称,透,梨,犁,移,稍,程,愁,稻,秕,秸,秽,稚,稆,逶,稞;
以上列举的只是部份常用字根的部份例字,可以看出对于三块字,如要求顺序取四个码,很多常用字根上要取两码,就增加了输入码数,增加了重码数。
3)、在单字中顺序取四个码比取三个码,要花费更多的注意力,这从上面列举的单字也可以看出,以下例字也可以说明:
俭,修,谋,些,郁,涛,佑,若,园,革,涤,帮。这样的字还有很多。
字形编码是字形检索(输入)码,以简单,快速为目的。因此和码单字取码规则:“单字最多分三块,最多取三个主要码”更好。
三、为什么汉字字形教学,需要有字形理论
我常看到识字课本上,教汉字书写是一笔一画地叠加,忽视汉字是由很多常用字根(口木人月心火氵王等)组成的基本字形知识。一笔一画地教汉字,很烦很难。要克服汉字难学,需要有汉字字形理论。
学生学了汉字,需要练习使用才能掌握与不忘。在信息时代,汉字字形的练习使用,重要的途径是在键盘上的汉字字形输入。
有效的汉字教学,需要与键盘字形练习与使用(输入)方法结合起来。
我在《解汉字难学之谜,创汉字易学方法》一文中,对汉字教学需要字形理论与技术有更多的说明。
四、为什么和码字形技术,适用于字形教学
字形教学需要有字形理论,那需要什么样的字形理论呢?
是否有包含了全部字形信息的字形描述技术与理论呢?我认为适合于字形教学的全息理论没有,如果有的话,那就是汉字字形本身。
字形教学所需的字形理论,是能帮助分析理解,认识记忆汉字字形,又可以在键盘上字形练习与使用(输入)字形的技术与理论。
和码汉字字形技术,以汉字的基本笔画(横竖撇捺)为起点,建立汉字的字形概念,又有和码25个常用字根,和码汉字字根表,汉字的字形分析与字根组合方法,也有汉字字形练习与输入软件。是一套系统汉字字形理论与技术。
和码汉字字形技术有很多成功的对外汉语与儿童识字教学实践,和码适用于字形教学。
五、将4.2版中的码(一)11,21,与码(口)33,34合并
1)、4.2版把字根“一”与“口”各分为两个码,给学习增加了难度。
2)、和码字形字母表,不应含有字形相同或相似的字母。
3)、5.0版第一码是(口)23的单字有625个(平均值为6763/25=270),是最大分布值,但对常用字的重码仍不突出。
合并后字根‘十’由4.2版的码22(码值22),变成了码31(码值13),这是很好的变化。
字根‘十’在有些字中不好取码。如:‘乱敌重垂鹅’等字,如果认为‘十’是双笔画核心字根,那么根据衍生字根的取码规则,在4.2版里‘乱敌重垂鹅’的第一码就只能取‘十’而不是‘丿’,这样的感觉很不好。现在5.0版‘十’的码值是13,比码41‘丿’的码值(14)还小,这样‘乱敌重垂鹅’第一码就可以取‘丿’了。
六、将第二区与第三区互换
4.2版的5个区排布是“横横竖撇点”(一一丨丿丶),修改后5.0版是“横竖十撇捺”(一丨十丿丶)。
这个修改使得大部份单字编码改变了。我问了两个朋友的意见,他们都说值得改。
和码的老朋友,长期的支持者叶志全先生建议,能否改为“横十竖撇捺”(一十丨丿丶),这样就可以保持第三区的编码不变,这也是一个选项。
当我们看到‘米’(或米字旗时),可能想到这个图案就是“横竖十撇捺”。利用人们已经熟悉的概念(词句),也许可以增加人们接受和码的容易程度,可以减少很多的解释。
七、将‘月’与‘冃’,‘冂’与‘几’合并
在4.2中,‘月’与‘冃’不在一起,那时我认为学汉字,就要知道‘月’与‘冃’的不同,和码帮助用户区别‘月’与‘冃’。
4.2版中,还区分了‘礻’(55)与‘衤’(55,43)。这个细致的区别对谁都有些难。
我又问过几个中国人,‘胖’‘青’字怎么写,他们都不知道‘胖’第一笔是‘丿’还是‘丨’,也认为这不重要。
在不同的字体中,‘胖’的第一笔画还有不同。
和码5.0版,认为‘月’与‘冃’是不同的,但在输入的层次上,都在码25中。
同样,‘礻’与‘衤’是不同,但在输入层次上,都在码55中。
八、有四类字根,采用了特殊取码
和码有核心字根的衍生字根的概念,如:‘稼’的第一码取34(木),而不是41(丿)。
以下情况也可以看似衍生字根的特例。
1)、虎,虏,虑,虚,虐,彪,虔,虞,觑,遽,劇,慮,戲,獻,盧,膚,處,虛,虜,虧,覷,顱,鸕,等的第一码都取14(厂),而不取21(丨);
2)、顽,顾,顿,倾,颂,领,颈,颗,题,颜,额,颠,颤,颁,颅,颇,颊,频,颓,颖,濒,等的第三码都取25(贝),而不取11(一);
弼,厦,廈,寡,嘎,嗄,等的第二码都取24(日目),而不取11(一);
3)、语,悟,捂,梧,晤,衙,唔,圄,浯,牾,焐,痦,龉,語,等的第二码都取13(彐),而不取11(一)。
另外:伟,围,陆,建,承,捕,逢,害,铺,割,苇,哺,圃,浦,脯,楔,玮,炜,祎,匍,埔,莆,彗,晡,揳,葜,滟,禊,碶,锲等的第二码都取31(十),而不取11(一)。
九、5.0版与4.2版编码分辨率比较(以GB2312的6763个字为统计范围)
4.2版5.0版改变不同的M1M2个数619618-1不同的M1M2M3个数47444572-172(3.6%)5.0版对汉字的分辨率是减少了,但不多,对于常用3800(或5200)个字,分辨率减少会更小。
十、5.0版对于4.2版,单字编码改变量统计
改变/6763第一码(M1)311446%第二码(M2)321147.5%第三码(M3)330748.9%M1M2484571.6%M1M2M3573084.7%5.0字根表,因为第二,三区互换,使得单字编码改变比例很大。严重影响了用户形成的习惯,我深感抱歉与不安。我个人也为此修改付出了很大代价,有2千本和码书,很多打印的卡片与资料都作废了,所有的软件都要做修改,网上资料,视频教程都要修改。
对常用的简体与繁体字(共9176个字)的修改与输入检查,已花了我近一个月的时间,如果要把大字库约7万个字全部修改完,至少还要2个月的时间(暂时不做大字库)。
但我认为这次修改是必须的,重要的,有误就尽早改,希望能得到和码老用户的谅解与支持。
十一、5.0版的适应方法
这篇文章是用5.0版输入的。从4.2版改为5.0版是困难的,就象用右手写字突然要改用左手。
建议用户下载安装后,用和码练习软件从头开始做适应性练习。特别是多做一二码字的练习。
老用户开始练习时,会不断出错,象不断地遭到批评一样,很容易感到累,会烦燥,会引起心理与生理的不舒服,这时就要意识到,这是改变习惯引起的不良反应,要及时地休息。我自己就清楚地感知到。
我也认为一定程度上,人的大脑是多线程的,当你练习一段时间后休息时,大脑会在后面(在你无意识的情况下)帮你做适应性处理,再回头练习就会感到有进步。
十二、5.0版后是否还会修改
这次修改的幅度大,是因为两个区交换了,我认为“横竖十撇捺”分区之后,再换区导致大改变的可能性为零。
我也把这次修改的原因与考虑的问题,都尽量详细地写在这里,让用户了解与评估和码方案的稳定性。
经过这几天的使用,我对5.0版很满意,对其稳定性很有信心。
再次为和码5.0版修改对和码老用户带来不良影响,深表歉意。
让我们一起克服困难,把汉字字形技术再往前推进一步。
谢谢!祝好!
欧阳贵林
2014年03月28日
点击下载:和码输入法5.0版
附录1、《和码》4.2版的说明
附录2、《和码》是最好最终的汉字形码
附录3、解汉字“难学”之谜,创汉字“易学”方法
- 和码5.0版的说明
- Mbatis 的#{}和¥{}说明:
- static和extern的说明
- big_endian和little_endian的说明
- big_endian和little_endian的说明
- PF_INET 和 AF_INET的说明!
- 模块和它们的说明
- cron 的配置和说明
- 哈希表和HashMap的说明
- vim 的配置和说明
- top和sar的说明
- 委托的说明和举例
- addKeyListener的使用方法和说明
- Bundle的说明和用法
- NSURLSession的介绍和说明
- ByteArrayOutputStream 和 ByteArrayInputStream的说明
- 我和asp的故事的说明
- php的xdebug的配置和说明
- FFplay的原理(1)
- 封装的评分星星类
- zero与usb-skeleton结合测试
- 文件的上传
- iwconfig用法
- 和码5.0版的说明
- MapReduce(十五): 从HDFS读取文件的源码分析
- 面试常见题之sizeof与strlen的区别
- CGContext一些绘图属性
- python+Django+pycharm 开发环境搭建
- dnsmasq用法
- FFplay的原理(3)
- 对系统的get异步请求进行一下小封装
- Java 调用MySQL存储过程配置与调用


