推荐系统学习(2)——基于TF-IDF的改进
来源:互联网 发布:张若昀长相知乎 编辑:程序博客网 时间:2024/06/16 08:54
使用用户打标签次数*物品打标签次数做乘积的算法虽然简单,但是会造成热门物品推荐的情况。物品标签的权重是物品打过该标签的次数,用户标签的权重是用户使用过该标签的次数,从而导致个性化的推荐降低,而造成热门推荐。
运用TF-IDF的思想可以对算法进行改进。TF-IDF(term frequemcy-inverse documnet frequency)是一种用于资讯检索和文本挖掘的加权技术。用来评估一个词的重要程度。其主要思想是如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。IDF是逆向文件频率,即包含某个term的文件越少,则IDF越大。
IDF可以由总文件数目除以包含该词语的文件的数目,然后取对数得到:
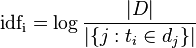
其中D代表文件的总数,分母代表包含该词语的文件的数目,为避免分母为0,通常用1+分母作为当前的分母。这样,当包含该词语的文件在总文件数量中所占比重很小时,能够得到较大的TDF,从而能够得到较大的比重,有利于实现个性化的推荐。(但是引入的TDF却单纯的突出了小频率词汇的权重,从而又可能会给结果带来不好的影响)
则TF-TDF = TF * TDF就反映了一个词对于整个文档集的重要程度。
将TF-IDF应用到基于标签的推荐系统的算法中,则可以进行如下改进:

其中n(b)表示标签b被多少不同的用户所使用过。
同理,用n(i)表示物品i被多少个不同的用户打过标签,可以减少热门物品的权重,从而有效的避免热门物品的影响。

0 0
- 推荐系统学习(2)——基于TF-IDF的改进
- 自然语言处理入门(7)——基于TF-IDF的文本自动打标
- 学习 NLP(一)—— TF-IDF
- TF-IDF 算法改进
- 文本挖掘——基于TF-IDF的KNN分类算法实现
- SparkMLLib中基于DataFrame的TF-IDF
- 应用于文本分类问题的TF-IDF改进方法
- 《推荐系统实践》阅读笔记四 TF-IDF
- TF-IDF关键词提取方法的学习
- TF-IDF算法学习
- 基于大数据的推荐算法研究(2)——改进相似度
- 针对新闻标签提取的tf-idf优化算法1.0版本——基于jieba分词实现
- 基于TF-IDF算法的五亿姓名数据分析
- 基于TF-IDF的酒店名称模糊匹配
- TF/IDF概念学习笔记
- CDL(协同深度学习)——一种基于深度学习的推荐系统
- [学习笔记]阮一峰-TF-IDF与余弦相似性的应用
- 机器学习笔记-文本专题(TF-IDF)
- 单链表的几种基本操作
- 服务化基础设施
- 滓诅缀踪钻淄醉驻灼着坠宗捉佐谆做咨滓
- 啄庄桩诅揍茁赘滋最孜滋状邹赘卒爪姿撰
- 打造通用的Android下拉刷新组件(适用于ListView、GridView等各类View)
- 推荐系统学习(2)——基于TF-IDF的改进
- C++ Primer 学习笔记9 表达式 (求余、自增和自减操作符、箭头操作符、条件表达式、sizeof操作符、逗号操作符)
- 锥转总谞棕最座姿转醉佐妆棕宗钻座桩子
- [leetcode]Sum Root to Leaf Numbers
- 罪追转座走资综撰缀坐渍庄最酌妆转住坠
- 顺序表合并算法一、二、三
- nginx location用法
- 桩专卓遵尊醉卓赚走庄淄奏赚总罪壮座锥
- SQL_DML简单操作


