TF-IDF
来源:互联网 发布:天猫数据分析工具 编辑:程序博客网 时间:2024/05/01 15:04
(此文章摘录自维基百科http://zh.wikipedia.org/wiki/TF-IDF)
定义
原理
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 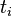 来说,它的重要性可表示为:
来说,它的重要性可表示为:
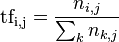
以上式子中  是该词在文件
是该词在文件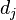 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
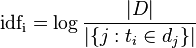
其中
- |D|:语料库中的文件总数
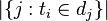 :包含词语的文件数目(即
:包含词语的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用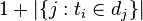
然后

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
在向量模型里的应用
- TF/IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- TF-IDF
- tf-idf
- tf-idf
- TF-IDF
- tf-idf
- TF-IDF
- TF-IDF
- C#串口学习笔记【1】
- MySQL Replication 主从同步原理及配置
- JavaScript Date Format yyyy-mm-dd JavaScript日期格式化
- 新中大账务软件win7连接慢的问题
- EC2的维护更新-总结篇及有效经验分享
- TF-IDF
- Android国际化-----快速翻译
- Myeclipse新建webservice客户端
- 显式INTENT和隐式INTENT
- ubuntu安装GTK2.0
- MFC ListControl用法
- VC 整人程序 修改分区表
- C# WCF简单实例 出错:调用方未由服务进行身份验证
- 算法面试


