H.264熵编码分析
来源:互联网 发布:mac添加搜狗输入法 编辑:程序博客网 时间:2024/06/01 08:11
转:H.264熵编码分析
利用信源的随机过程统计特性进行码率压缩的编码方式称为熵编码。它是把所有的语法(句法)元素(包括控制流数据,变换量化残差系数和运动矢量数据)以一定的编码形式映射成二进制比特流。熵编码是无损压缩编码方法,它生成的码流可以经解码无失真地恢复出数据。在信息论中表示一个数据符号的理论上最佳的比特数通常是一个分数而不是整数,这个比特数用log2(1/P)表示,其中P是每个数据符号的出现概率。这里Log2(1/P)指的就是熵的概念。熵的大小与信源的概率模型有着密切的关系,各个符号出现的概率不同,信源的熵也不同。当信源中各事件是等概率分布时,熵具有极大值。信源的熵与其可能达到的最大值之间的差值反映了该信源所含有的冗余度。信源的冗余度越小,即每个符号所独立携带的信息量越大,那么传送相同的信息量所需要的序列长度就越短,符号位也越少。因此,数据压缩的一个基本的途径是去除信源的符号之间的相关性,尽可能地使序列成为无记忆的,即前一符号的出现不影响以后任何一个符号出现的概率。
熵编码可以是定长编码,变长编码或算术编码;变长编码对出现频率高的符号用短码字表示,对出现频率低的符号用长码字表示。算术编码是一种递推形式的连续编码,其思想是用0到1的区间上的一个数来表示一个字符输入流,它的本质是为整个输入流分配一个码字,而不是给输入流中的每个字符分别指定码字。算术编码是用区间递进的方法来为输入流寻找这个码字的,它从于第一个符号确定的初始区间(0到1)开始,逐个字符地读入输入流,在每一个新的字符出现后递归地划分当前区间,划分的根据是各个字符的概率,将当前区间按照各个字符的概率划分成若干子区间,将当前字符对应的子2区间取出,作为处理下一个字符时的当前区间。到处理完最后 一个字符后,得到了最终区间,在最终区间中任意挑选一个数作为输出。算术编码是一种高效的熵编码方案,其每个符号所对应的码长被认为是分数。由于对每一个符号的编码都与以前编码的结果有关,所以它考虑的是信源符号序列整体的概率特性,而不是单个符号的概率特性, 因而它能够更大程度地逼近信源的极限熵,降低码率。
在H.264标准中有3种熵编码方案: 一个是指数哥伦布编码(Exponential Golomb Codes);一个是从可变长编码发展而来的上下文自适应可变长编码(CAVLC);另一个是从算术编码发展而来的基于上下文的自适应二进制算术编码(CABAC)。前两种属于变长编码,而第三种属于算术编码。研究表明CABAC的压缩效率比CAVLC提高了9%~14%。在标准中通过描述子(Descriptor)的形式来说明熵编码的方法。
Exp‐Golomb Codes
Exp‐Golomb的描述子有无符号指数哥伦布编码ue(v),有符号指数哥伦布编码se(v),截断指数哥伦布编码te(v)和映射指数哥伦布编码me(v)。
0阶指数哥伦布编码是一种有规则结构的变长编码,它的结构可以表示为
[M zeros][1][INFO]
其中M zeros称为前缀,由M个零组成,而M位INFO称为信息后缀。码字总长为2M+1。M和INFO的值由要编码的值索引code_num得到。(可参考标准表9‐1)
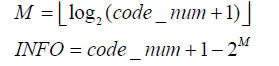
ue(v)从v到code_num的转换公式为code_num = v。(可参考标准表9‐2)
se(v)从v到code_num的转换公式为:
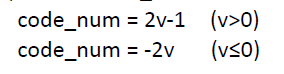
te(v)从v到code_num的转换,首先根据语法元素v值位数范围,如果v的位数大于1,v到code_num的转换过程和ue(v)相同;如果v的位数等于1,即v等于0或1,则code_num与v的值相同,但最终的编码值与code_num这个值相反。
me(v)从v到code_num的转换参考标准表9‐4。
CAVLC
CAVLC的描述子是ce(v)。
基于上下文自适应编码的CAVLC利用相邻已编码符号所提供的相关性为所要编码的符号选择合适的上下文模型,大大降低了符号间的冗余度。上下文模型的选择主要体现在非零系数和拖尾系数的个数编码所需表格(nC)的选择以及非零系数的幅值编码后缀长度(suffixLength)的更新。CAVLC编码的具体过程由以下五部分组成,编码顺序和Zig‐zag扫描顺序相反:
(1) 对非零系数的数目(TotalCoeffs)以及拖尾系数(TrailingOnes)的数目进行编码。根据这两个值一共有3个变长表格和1个定长表格(这4个表格只针对于亮度系数,色度系数使用其它表格)可供选择(选择的表格由相邻块非零系数的个数nC值确定,具体参见标准表9‐5)。其中的定长表格的码字是六个比特长,高四位表示TotalCoeffs,低两位表示TrailingOnes。
(2) 对每个拖尾系数的符号进行编码。(+1用0表示,‐1用1表示)
(3) 对除了拖尾系数之外的非零系数的幅值(Levels)进行编码。这一步比较复杂,这里详细介绍对单个幅值的编码方法:
a) 将有符号的level转换成无符号的levelCode:
如果level是正的,levelCode = (level<<1)‐2;
如果level是负的,levelCode = ‐(level<<1)‐1;
特别地,当TrailingOnes<3时,第一个非拖尾系数的幅值level要加1(当幅值为负)或减1(当幅值为正)后再计算levelCode。
b) 计算level_prefix:
level_prefix = levelCode / (1<<suffixLength);
根据level_prefix的值查标准表9‐6即可得到对应的字符串前缀。当TotalCoeffs>10且TrailingOnes<1时suffixLength初始为1,其它情况下suffixLength初始为0。
c) 计算level_suffix:
level_suffix = levelCode % (1<<suffixLength);
字符串后缀是level_suffix值的二进制无符号数形式。
d) suffixLength值更新为下一个编码作准备,如果当前已编码的非零系数值大于预先定义好的阈值,suffixLength加1。伪代码如下(注意这里隐含了上下文自适应过程):
If ( suffixLength == 0 )
suffixLength++;
else if ( Abs(level) > (3<<(suffixLength‐1)) && suffixLength <6)
suffixLength++;
e) 编码值为前缀和后缀的拼接。
(4) 对最后一个非零系数前零的数目(TotalZeros)进行编码(参见标准表9‐7,9‐8,9‐9)。
(5) 对每个非零系数前零的个数(RunBefore)进行编码(参见标准表9‐10)。还有一个变量ZerosLeft表示当前非零系数左边的所有零的个数,ZerosLeft的初始值等于TotalZeros,在每个非零系数的RunBefore值编码后进行更新。注意在以下两种情况下是不需要编码的:
a) 最后一个非零系数(run_before[0])前零的个数。
b) 没有剩余的零需要编码(ZerosLeft=0)。
CABAC
CABAC的描述子是ae(v)。
CABAC充分考虑和利用了视频流统计特性,克服了VLC编码中的缺点,充分利用了视频流的上下文信息,并且能够自适应视频流的统计信息,提高了编码效率。CABAC的编码流程如图1所示,主要分为3部分:语法元素二进制化、上下文建模和自适应二进制算术编码器。
大致编码过程如下:如果输入的语法元素是非二进制的语法元素则进行二进制化, 二进制的语法元素跳过这一过程。 二进制字符串进入编码器, 可以进行快速编码, 直接进入旁路编码器, 以固定的概率模型进行编码; 通常是根据语法元素的类型选择上下文, 然后二进制值和选择的上下文模型一起进入编码器, 输出编码码流, 并且根据编码符号更新上下文模型。CABAC要编码的语法元素包括两类:第一类包含关于宏块类型、子块类型以及时间和空间预测模式信息的元素;第二类包括所有残差元素,也就是所有变换系数相关的语法元素。

下面将详细介绍流程中的三个部分。
A. 语法元素二进制化
H.264通过二进制化把多维算术编码转化为二进制算术编码,提高了运算速度。语法元素二进制化就是把非二进制的符号映射成若干位的二进制串。CABAC引入了二进制化预处理过程来减小要编码的语法元素符号集的大小, 对于给定的语法元素用一个惟一的二进制串代替。CABAC二进制化方案由基本方案,串接方案(参考标准子条款9.3.2.3,9.3.2.6)以及特别的手工选择方案(参考标准子条款9.3.2.5)组成。基本方案有一元码、截断一元码、K阶指数哥伦布码和定长码4种;串接方案由基本方案串接而成;手工选择方案有5种,专门针对mb_type和sub_mb_type这两种语法元素。对语法元素的二进制化方案参考标准表9‐25。经二进制化编码输出的是MPS概率极高的比特流,这样可以达到极高的压缩效果。
B. 上下文建模
利用相邻的编码符号的相关性,用已编码符号为待编码符号选择合适的上下文模型,上下文模型提供了对当前待编码符号的概率估计,上下文信息可以降低符号间的冗余度。在H.264中通过索引选择的方法利用上下文信息。首先建立上下文集合,上下文变量按线性排列,每一个变量用索引值来表示,然后为每一个语法元素分配上下文变量,最后通过编码符号的上下文信息选择上下文变量。
在H.264中用64个有代表性的概率值来表示LPS(Least Probability Symbol)的概率。这64个概率值 通过下式产生:
通过下式产生:
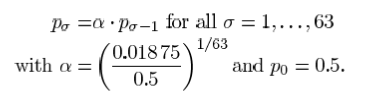
其中 表示概率的索引值(
表示概率的索引值( ),在H.264中概率模型用上下文变量表示,而上下文变量由2个变量组成, 分别为6位概率状态索引值
),在H.264中概率模型用上下文变量表示,而上下文变量由2个变量组成, 分别为6位概率状态索引值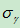 (pStateIdx)和1位最大可能符号值
(pStateIdx)和1位最大可能符号值 (valMPS),所以概率状态空间总共有7位128个状态。最大可能符号值MPS(Most Probability Symbol)取"0"或"1",(ctxIdx)为上下文变量的索引值,各语法元素的
(valMPS),所以概率状态空间总共有7位128个状态。最大可能符号值MPS(Most Probability Symbol)取"0"或"1",(ctxIdx)为上下文变量的索引值,各语法元素的 取值范围可参考标准表9‐11,其准确值是这样计算的:
取值范围可参考标准表9‐11,其准确值是这样计算的:
如果索引偏移值(标准表9‐11中范围的左值,即ctxIdxOffset)在标准表9‐30中,则ctxIdx是ctxIdxOffset与索引增加量(ctxIdxInc)之和,而ctxIdxInc取决于位索引(binIdx)和ctxIdxOffset;否则,ctxIdx是ctxIdxOffset,ctxIdxInc与上下文种类偏移(ctxIdxBlockCatOffset)之和。此时ctxIdxInc与ctxIdxBlockCatOffset的值和上下文种类(ctxBlockCat)相关。ctxBlockCat的取值可参考标准表9‐33。
上下文变量初始值由训练序列得到(参考标准子条款9.3.1.1),注意上下文变量初始值对于所有上下文变量的索引值ctxIdx都要计算,其计算表达式如下:
preCtxState = Clip3( 1, 126, ( ( m


