梯度下降(gradient descent)
来源:互联网 发布:北邮ipv4网络电视网站 编辑:程序博客网 时间:2024/05/21 17:05
梯度下降法,又称最速下降法。1847年由著名的数学家柯西Cauchy给出。
梯度下降法,基于这样的观察:如果实值函数  在点
在点 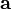 处可微且有定义,那么函数 在 点沿着梯度相反的方向
处可微且有定义,那么函数 在 点沿着梯度相反的方向  下降最快。
下降最快。
因而,如果

对于  为一个够小数值时成立,那么
为一个够小数值时成立,那么 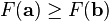 。
。
考虑到这一点,我们可以从函数  的局部极小值的初始估计
的局部极小值的初始估计 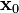 出发,并考虑如下序列
出发,并考虑如下序列 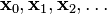 使得
使得

因此可得到

如果顺利的话序列  收敛到期望的极值。注意每次迭代步长
收敛到期望的极值。注意每次迭代步长  可以改变。
可以改变。
下面的图片示例了这一过程,这里假设 定义在平面上,并且函数图像是一个碗形。蓝色的曲线是等高线(水平集),即函数 为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达碗底,即函数 值最小的点。

给出目标函数J(θ),要使其最小化:

α被称为学习率,决定梯度下降搜索中的步长,梯度下降只能收敛于局部最优,如果需要可通过调整步长来实现全局最优。如果α过小,梯度下降可能很慢;如果过大,梯度下降有可能“迈过”(overshoot)最小点,并且有可能收敛失败,并且产生“分歧”(diverge)。梯度下降可以使函数收敛到一个局部最小值,特别对于learning rate α是固定值的时候对于某一个性能指数,我们能够运用梯度下降法,使这个指数降到最小。若该指数为均方误差,我们便得到了最小均方误差(LMS)算法。
现在我们回到线性回归的问题上,我们的目标函数J(θ):

对于这类的问题,我们有对应的梯度下降的更新规则与算法:

这种方法每一步都会遍历整个训练数据,被称为批量梯度下降,用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适。所以我们引入随机梯度下降,随机梯度下降是一种对参数随着样本训练,一个一个的及时更新的方式。常用于大规模训练集,当往往容易收敛到局部最优解。

单独针对上面的linear regression问题,批量梯度下降与随机梯度下降的比较
1.批量梯度下降---最小化所有训练样本的损失函数,各维同时更新,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。
2.随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向,但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
不只针对线性回归的问题,标准的梯度下降和随机梯度下降的区别:
1.标准下降时在权值更新前汇总所有样例得到的标准梯度,随机下降则是通过考察每次训练实例来更新。
2.对于步长α的取值,标准梯度下降的α比随机梯度下降的大。因为标准梯度下降的是使用准确的梯度,随机梯度下降使用的是近似的梯度,一不小心就会出错。
3.当目标函数有多个局部极小值时,随机梯度反而更可能避免进入局部极小值中。

下面给出批量梯度下降和随机梯度下降的matlab的代码:
clear ;close all;x = [1:50].';y = [4554 3014 2171 1891 1593 1532 1416 1326 1297 1266 ...1248 1052 951 936 918 797 743 665 662 652 ...629 609 596 590 582 547 486 471 462 435 ...424 403 400 386 386 384 384 383 370 365 ...360 358 354 347 320 319 318 311 307 290 ].';%m = length(y); % store the number of training examplesx = [ ones(m,1) x]; % Add a column of ones to xn = size(x,2); % number of featurestheta_batch_vec = [0 0]';theta_stoch_vec = [0 0]';alpha = 0.002;err = [0 0]';theta_batch_vec_v = zeros(10000,2);theta_stoch_vec_v = zeros(50*10000,2);for kk = 1:10000% batch gradient descent - loop over all training seth_theta_batch = (x*theta_batch_vec);h_theta_batch_v = h_theta_batch*ones(1,n);y_v = y*ones(1,n);theta_batch_vec = theta_batch_vec - alpha*1/m*sum((h_theta_batch_v - y_v).*x).';theta_batch_vec_v(kk,:) = theta_batch_vec;%j_theta_batch(kk) = 1/(2*m)*sum((h_theta_batch - y).^2);% stochastic gradient descent - loop over one training set at a timefor (jj = 1:50)h_theta_stoch = (x(jj,:)*theta_stoch_vec);h_theta_stoch_v = h_theta_stoch*ones(1,n);y_v = y(jj,:)*ones(1,n);theta_stoch_vec = theta_stoch_vec - alpha*1/m*((h_theta_stoch_v - y_v).*x(jj,:)).';%j_theta_stoch(kk,jj) = 1/(2*m)*sum((h_theta_stoch - y).^2);theta_stoch_vec_v(50*(kk-1)+jj,:) = theta_stoch_vec;endendfigure;plot(x(:,2),y,'bs-');hold onplot(x(:,2),x*theta_batch_vec,'md-');plot(x(:,2),x*theta_stoch_vec,'rp-');legend('measured', 'predicted-batch','predicted-stochastic');grid on;xlabel('Page index, x');ylabel('Page views, y');title('Measured and predicted page views');j_theta = zeros(250, 250); % initialize j_thetatheta0_vals = linspace(-2500, 2500, 250);theta1_vals = linspace(-50, 50, 250);for i = 1:length(theta0_vals) for j = 1:length(theta1_vals)theta_val_vec = [theta0_vals(i) theta1_vals(j)]';h_theta = (x*theta_val_vec);j_theta(i,j) = 1/(2*m)*sum((h_theta - y).^2); endendfigure;contour(theta0_vals,theta1_vals,10*log10(j_theta.'))xlabel('theta_0'); ylabel('theta_1')title('Cost function J(theta)');hold on;plot(theta_stoch_vec_v(:,1),theta_stoch_vec_v(:,2),'rs.');plot(theta_batch_vec_v(:,1),theta_batch_vec_v(:,2),'kx.');其中:
.


对于下面的这幅图来说,批量梯度下降(黑线)直接到了最小值,而随机梯度下降(红线)在到达最小值之前一直在最小值周围徘徊。

- 梯度下降(gradient descent)
- 梯度下降(Gradient descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降(gradient descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降(Gradient Descent)
- 梯度下降Gradient descent
- 梯度下降算法(Gradient descent)
- 梯度下降法(Gradient Descent)
- 梯度下降法(Gradient Descent)
- 梯度下降(Gradient Descent)小结
- 梯度下降(Gradient Descent)小结
- 梯度下降(Gradient Descent)小结
- 淘宝客网站应该怎么优化?
- java 单向链表的操作
- VS2010菜单资源详解
- html 实现自动填表
- NSSet类型以及与NSArray区别
- 梯度下降(gradient descent)
- 关于音乐播放器中随机播放的两种模式
- 架构师之路
- HDU 1811 Rank of Tetris(topsort)
- selenium-java-Firefox 特殊异常:界面找不到元素
- spdy_proxy(一)
- test
- Navicat for MySQL
- 由2+2=5对缓存池进行粗略了解


