Project2--Lucene的Ranking算法修改:BM25算法
来源:互联网 发布:小米手机自动更新软件 编辑:程序博客网 时间:2024/05/21 09:58
原文出自:http://blog.csdn.net/wbia2010lkl/article/details/6046661
1. BM25算法
BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下:
∑ 
其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。
K1通常为1.2,通常为0-1000
K的形式较为复杂
K=
上式中,dl表示文档的长度,avdl表示文档的平均长度,b通常取0.75
2. BM25具体实现
由于在典型的情况下,没有相关信息,即r和R都是0,而通常的查询中,不会有某个词项出现的次数大于1。因此打分的公式score变为
∑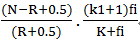
3. 使用Lucene实现BM25
Lucene本身的打分函数集中体现在tf·idf
为了简化实现过程,直接将代码中tf和idf函数的返回值修改为BM25打分公式的两部分。
文档的平均长度在索引建立的时候取得,同时在建立索引的过程中,将每个文档的docID与其长度,保存在一个hashMap中。
具体的函数实现如下(DefaulSimilarity类):
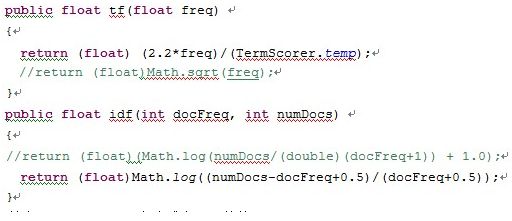
其中TermScore.temp为公式中K+fi的值
Temp的计算在TermScore类中进行计算:
public float score() {
assert doc != -1;
int f = freqs[pointer];
temp=(float)(1.2*(0.25+0.75*FileSearch.docToken.get(doc))+f);
System.out.println("weightValue: "+weightValue);
float raw = getSimilarity().tf(f)*weightValue; // compute tf(f)*weight
//f < SCORE_CACHE_SIZE // check cache
//? scoreCache[f]*temp // cache hit
//: getSimilarity().tf(f)*weightValue*temp; // cache miss
System.out.println("score func doc id :"+doc+" "+temp+" "+f+" "+ getSimilarity().tf(f));
System.out.println("raw value is"+raw);
return norms == null ? raw : raw * SIM_NORM_DECODER[norms[doc] & 0xFF];
}
值得注意的是:在lucene的得分计算中,使用explain函数可以看出,除了tf、idf的乘积之外,还有一个fieldNorm值,这个值的计算是基于索引的建立过程,与文档以及field的长度有关,综合考虑,这个值对于查询的过程还是比较有效的,因此在具体实现中,依然保存了fieldNorm的值。
- Project2--Lucene的Ranking算法修改:BM25算法
- Project2--Lucene的Ranking算法修改:BM25算法
- Project2--Lucene的Ranking机制浅析
- lucene中的ranking算法
- 将BM25 用作lucene排序算法的实现步骤
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- bm25 算法
- 在lucene的ranking算法中使用Language Model
- BM25算法的实现过程
- Okapi BM25算法详解
- 【Boost】boost库asio详解5——resolver与endpoint使用说明
- 贪心算法介绍
- 数据库多表连接,返回结果集
- 两段shell脚本,监控进程和主动结束进程
- Git---强大的版本控制工具
- Project2--Lucene的Ranking算法修改:BM25算法
- Linq:基本语法group by, order by ,into(3)
- Redis常用命令
- Java web测试分为6个部分
- 成员函数占内存空间吗
- 如何系统地学习数据挖掘?
- 使用两个单独的ViewController 来实现横竖屏的翻转
- Android系统权限和root权限
- 推荐代码调整工具


